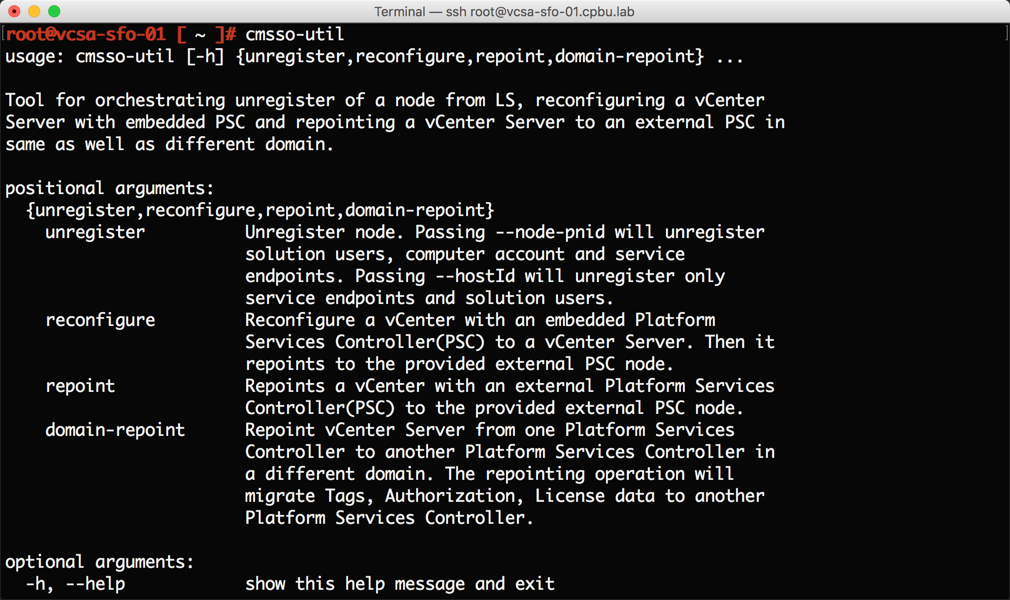
سرور Blade c3000 قابليت هاي منحصر به فردي را ارائه مي دهد. از جمله کاربردهاي c3000 مي توان به موارد زير اشاره کرد:
1- با توجه به قابليت توسعه براي کسب و کارهاي کوچک تا متوسط مناسب است.
2- براي نرم افزارهايي که حداکثر به 8 سرور در هر شاسي نياز دارند.
3- مکان هايي که در تأمين انرژي رک ها و سيستم خنک کننده ي آن ها محدوديت دارند.
4- ديتا سنتر هايي که نياز دارند تا به برق UPS يا برق 100-120 VAC متصل شوند.
مديريت يکپارچه موجود بر روي c3000 همانند c7000، به شما کنترل کاملي را بر روي دستگاه تان مي دهد. هر انکلوژر c3000 بخش هاي متحرک کابل هاي زير ساخت، منابع تأمين برق و خنک کننده ها، شبکه و افزونگي را در يک بسته جمع مي کنند. c3000 راهکار مقرون به صرفه اي است که با ويژگي هاي مفيدي همچون سرعت بالا و سهولت در ايجاد تغييرات، از هدر رفتن زمان و انرژي شما جلوگيري مي کند. نتيجه نهايي از بررسي اين دستگاه سهولت بيشتر هنگام نصب، نگهداري و استفاده هاي روزانه مي باشد.
بعد از انتخاب انکلوژر و اجزاء کليدي مربوط به آن مي توان ساير اجزاء مورد نياز را اضافه کرد. در ادامه به اين موارد اشاره شده است :
ماژول هاي Interconnect
سرور هاي HPE ProLiantو Integrity Server Blades
Expansion Blades
HPE Insight Control Optional براي نرم افزار مديريت BladeSystem
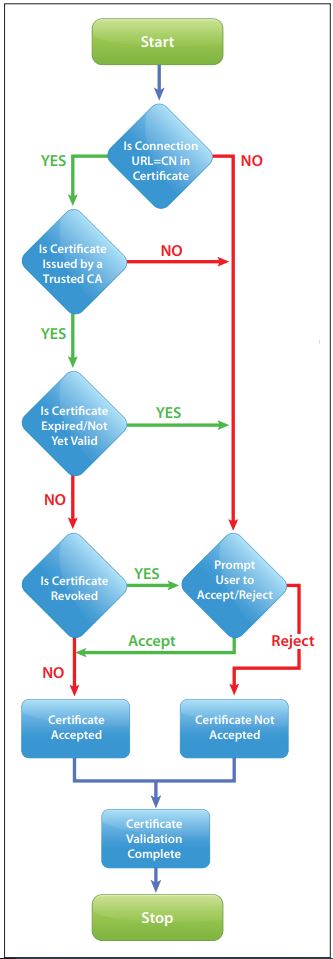
توجه داشته باشيم که :انکولوژر C7000 و C3000 قابليت پشتيباني از رده هاي G1 الي G9 سرورهاي ProLiant و Integrity Server Blades را دارند . البته اين مبحث منوط بر اين است که از الزامات Onboard Administrator پشتيباني کند . بعضي از سرورهاي HPE ProLiant Blade و مؤلفه هاي آنها يک نسخه خاص از Onboard Administrator Firmware را لازم دارند . عرضه اين Firmware ممکن است که به ارتقاء سيستم فرعي Subsystem Firmware هاي ديگر نيازمند باشد.
BladeSystem c3000 Enclosure حداکثر 8 عدد سرور Blade و 4 عدد تيغه توسعه ( از مجموع 8 عدد تيغه نبايد تجاوز کند ) به همراه اتصالات مربوط به استوريج و شبکه هاي Redundant ، را ارائه مي دهد . اين محصول همچنين شامل MidPlane مولتي-ترابيت با سرعت بالا نيز مي باشد که جهت برقراري اتصالات Wire-Once سرور هاي Bladeبه شبکه و ذخيره ساز اشتراکي مورد استفاده قرار مي گيرد . توان برقي که در اين انکلوژر به کار مي رود از طريق منبع تغذيه Backplane تأمين مي شود و اين تضمين را مي دهد که ظرفيت کامل آن براي تمام تيغه ها (Blades) قابل دسترس باشد.
امروزه سازمان ها به دنبال این هستند که عملکرد کسب و کار خود را توسعه داده و بار کاری خود را اعم از سنتی و هیبریدی ، به شکل ایمن بر روی یک زیر ساخت یکپارچه ، همگام کنند .
سرور HP BL460c g10 از جمله محصولاتی است که توسط کمپانی HPE تولید و روانه بازار شد . این سرور جهت پیکربندی و توسعه در محدوده وسیع طراحی شده است ، علاوه بر این قابلیت انعطاف پذیری این دستگاه ، امکانات ذخیره سازی بیشتر و عملیات I/O سریعتری را به ارمغان می آورد. همچنین توان پردازشی قدرتمندی که سرور BL660 G10 ارائه می دهد ، جهت برآورده کردن نیاز انواع بار کاری با TCO کمتر ، عرضه گردیده است . تمام قابلیت های فوق الذکر این محصول ، توسط HPE OneView مدیریت می شوند که از یک پلت فرم مدیریتی یکپارچه جهت تسریع سرویس ها ، بهره می برد .
سرور BL460c G10 مانند سایر محصولات هم رده خود از خانواده پردازنده های قابل ارتقاء ®Intel® Xeon پشتیبانی می کند ، این پردازنده نسبت به نسل قبلی 25% افزایش عملکرد دارد . همچنین این دستگاه از 2666MT/s HPE DDR4 SmartMemory نیز برخوردا است .
از دیگر قابلیت های سرور HP BL460c g10 می توان به موارد زیر اشاره کرد :
**• پشتیبانی از گزینه های Tiered Storage Controller **• ارائه دادن Internal 12 Gb/s SAS **• ارائه 20Gb FlexibleLOMs **• فراهم آوردن 2 عدد NVMe ، M.2 و حداکثر 4 عدد درایو uFF **• ارائه دادن گزینه های HPE ProLiant Persistent Memory
پیشنهاد می شود جهت آشنایی بیشتر با سرورهای Blade ، مطلب زیر را مورد مطالعه قرار دهید :
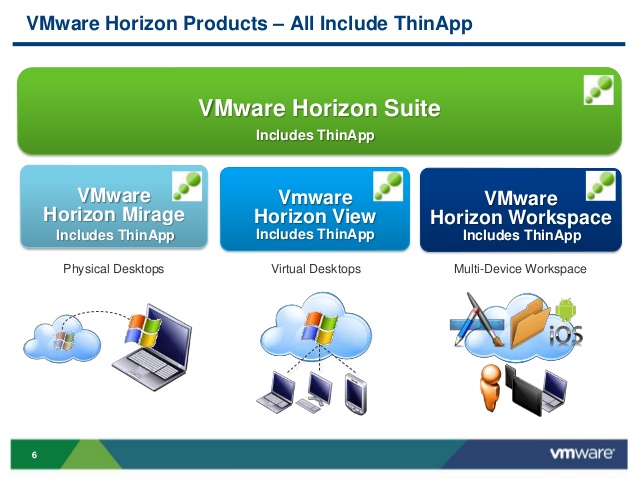
VMware محصولات گوناگونی از Horizon را عرضه کرده است که همه این محصولات برای ارائه خدمات به کاربران در یک مجموعه واحد به نام VMware Horizon Suite قرار می گیرند. ادمین با استفاده از مجموعه Horizon می تواند دسکتاپ ها، اپلیکیشن ها و داده را در سراسر انواع endpoint ها توزیع کند و پاسخگوی تقاضای کاربران برای دسترسی به فایل ها و داده ها در انواع دستگاه ها و در محیط خانه، اداره و … باشد. این مجموعه شامل راهکارهای Horizon View، Horizon Mirage و Horizon Workspace می شود و از قابلیت های زیر پشتیبانی می کند:
اپلیکیشن ها و دسکتاپ های مجازی
مدیریت لایه بندی شده ی windows image به همراه مدیریت متمرکز، بازیابی و پشتیبان گیری
به اشتراک گذاری فایل
مدیریت فضای کاری متغیر
Application catalog and management
مدیریت متمرکز مبتنی بر policy
VMware Horizon View
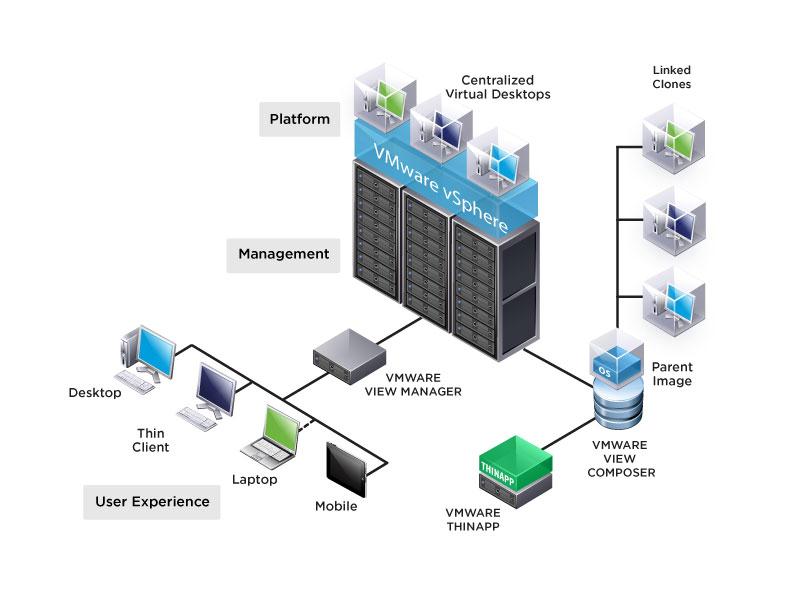
Horizon View یک راهکارِ مجازی سازی دسکتاپ برای تسهیل مدیریت IT، افزایش امنیت و کنترل دسترسی بر کاربرنهایی است که هزینه ها را نیز کاهش می دهد. با استفاده از Horizon View، مدیر شبکه می تواند مدیریت هزاران دسکتاپ را اتوماتیک و ساده سازی کند و از طریق واحد مرکزی با اطمینان دسکتاپ را به عنوان یک سرویس به کاربران تحویل دهد.
مهمترین بخش در Horizon view واسط اتصال یا همان View Manager است که کاربران را به دسکتاپ های مجازی موجودشان در دیتاسنتر متصل می کند. همچنین View شامل پروتکل نمایش از راه دور PCoIP است که جهت ارائه بهترین تجربه کاربری ممکن ، تحت ارتباطات LAN یا WAN استفاده می شود. در نتیجه به کاربر یک دسکتاپ شخصی قدرتمند برای دسترسی به داده، اپلیکیشن ها، ارتباطات یکپارچه (صوت، تصویر و ..) و گرافیک 3D تعلق می گیرد.
علاوه بر موارد ذکر شده، Horizon View شامل ThinApp برای مجازی سازی اپلیکیشن و Composer (برای اینکه به سرعت image های دسکتاپ را از طریق یک golden image ایجاد کند) می شود. کاربران از طریق چندین روش می توانند به دسکتاپ های مجازی خود متصل شوند که شامل View software client بر روی لپتاپ، View iPad یا Android client، مرورگر وب یا یک دستگاه thin-client می شود.
برخی از مولفه های اصلی در Horizon View عبارتند از:
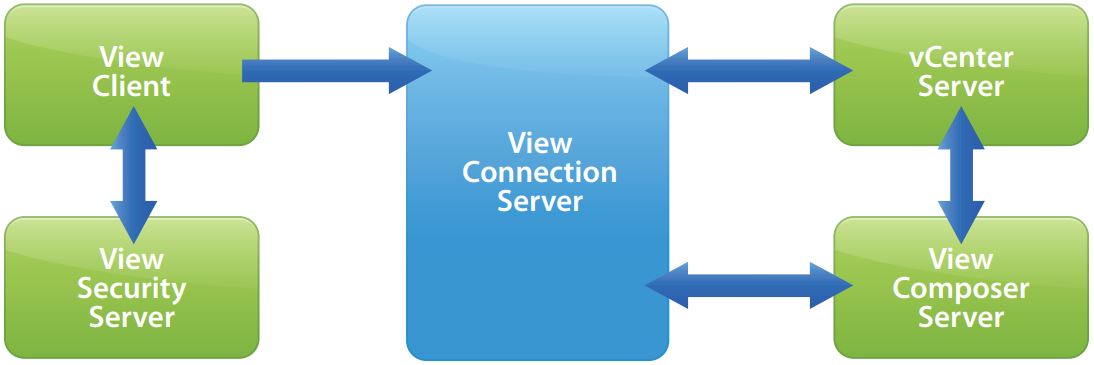
View Connection Server – یک سرویس نرم افزاری است که از طریق احراز هویت و سپس هدایت درخواست های ورودی کاربر به دسکتاپ مجازی، دسکتاپ فیزیکی یا سرور ترمینال مناسب به عنوان واسطی برای اتصال کلاینت عمل می کند.
View Agent – سرویسینرم افزاری است که بر روی همه ماشین های مجازی مهمان، سیستم های فیزیکی یا سرورهای ترمینال نصب می شود تا بتوانند توسط View مدیریت شوند.
View Client – اپلیکیشنی نرم افزاری است که با View Connection Server ارتباط برقرار می کند تا به کاربران اجازه اتصال به دسکتاپ ها را بدهد.
View Client with Local Mode – نسخه ای از View Client است که جهت پشتیبانی از ویژگی local desktop ارائه شده است و به کاربران اجازه دانلود ماشین های مجازی و استفاده از آنها بر روی سیستم های محلی خود را می دهد.
View Administrator – یک اپلیکیشن وب است که اجازه کانفیگ View Connection Server ، استقرار و مدیریت دسکتاپ ها، کنترل احراز هویت کاربر، راه اندازی و ارزیابی رویدادهای سیستم و اجرای فعالیت های تحلیلی را می دهد.
vCenter Server – سروری است که به عنوان administrator مرکزی برای هاست های ESX/ESXi عمل می کند. vCenter Server بخشی مرکزی را برای کانفیگ، اصلاح و مدیریت ماشین های مجازی موجود در دیتاسنتر فراهم می کند.
View Composer – سرویسی نرم افزاری است که بر روی vCenter server نصب می شود تا View بتواند به سرعت چندین دسکتاپ linked-clone را از یک Base Image واحد در شبکه مستقر نماید.
View Transfer Server – یک سرویس نرم افزاری است که انتقال داده میان دیتاسنتر و دسکتاپ های View را مدیریت و تسهیل می کند. برای پشتیبانی از دسکتاپ هایی که View Client with Local Mode را اجرا می کنند، View Transfer Server مورد نیاز است.
VMware Horizon Mirage
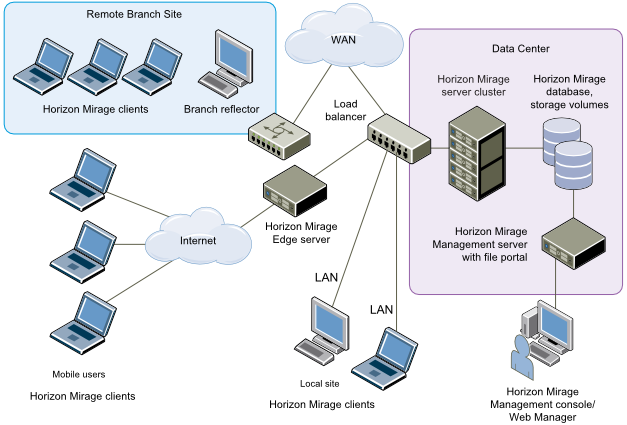
کمپانی VMware راهکار Mirage را در سال 2012 از شرکت Wanova خریداری نمود و در مجموعه VMware Horizon Suite قرار داد. Mirage راهکاری منحصر به فرد برای مدیریت متمرکز دسکتاپ های فیزیکی یا مجازی، لپ تاپها و یا دستگاه های شخصی مورد استفاده در محیط کار است. هنگامی که Mirage بر روی یک windows PC نصب شده باشد، کپی کاملی را از آن Windows بر روی دیتاسنتر قرار می دهد و آنها را با یکدیگر همگام نگاه میدارد. این همگام سازی شامل تغییراتی از جانب کاربر نهایی در windows می شود که بر روی دیتاسنتر بارگذاری می شوند. همچنین شامل تغییراتی از جانب مدیر شبکه در رابطه با IT است که دانلود شده و به طور مستقیم بر روی windows PC کاربر اعمال می شود. Mirage توانایی مدیریت مرکزی image های دسکتاپ ها را دارد در حالی که مجوز مدیریت محیط local کاربر را به خود کاربرنهایی نیز می دهد.
Mirage می تواند PC را به لایه هایی مجزا تقسیم کند که به طور مستقل مدیریت می شوند: لایه Base Image، یک لایه شامل اپلیکیشن هایی نصب شده توسط کاربر و اطلاعات ماشین همچون machine ID و یک لایه شامل داده و فایل های شخصی کاربر.
در این روش، مدیر IT می تواند یک read-only Base Image ایجاد کند که معمولا شامل سیستم عامل (OS) و اپلیکیشن های اصلی همچون Microsoft Office و راهکارهای آنتی ویروسی می شود که به صورت مرکزی مدیریت می شوند. این Base Image می تواند بر روی کپی ذخیره شده از هر PC مستقر شود و سپس با نقطه نهایی هماهنگ شود. به دلیل لایه بندی، Image می تواند patch، بروزرسانی و re-synchronized شود، بدون اینکه اپلیکیشن های نصب شده توسط کاربر یا داده را بازنویسی کند. این ویژگی منجر به بهینه سازی در عملیات شبکه خواهند شد و موارد استفاده زیر را خواهد داشت:
مدیریت Image واحد – ادمین می تواند یک Image اصلی را مدیریت کند و آن را با هزاران نقطه نهایی (endpiont) همگام سازد.
مهاجرت سخت افزاری – با جایگزین کردن Base Image مرتبط با PC یک کاربر نهایی، دسکتاپ کاربر از جمله اپلیکیشن ها، داده و تنظیمات شخصی می تواند به سخت افزار جدید از جمله سخت افزاری از سازنده ای دیگر منتقل شود. این فرآیند را می توان به عنوان بخشی از یک فرآیند مهاجرت سخت افزاری یا برای جایگزینی یک PC دچار خرابی، یا دزدیده شده استفاده نمود.
اصلاح ریموت اپلیکیشن های آسیب دیده – با اجرای یک Base image ، ادمین می تواند با ریموت زدن به کپی اصلی موجود در دیتاسنتر، مشکلات اپلیکیشن های اصلی یا OS را اصلاح کند.
مهاجرت محلی از ویندوز Win xP به Win 7 – با جایگزین کردن Base Image مرتبط با PC یک کاربر نهایی، دسکتاپ کاربر از جمله داده و تنظیمات شخصی می تواند تحت شبکه و بدون زیرساخت اضافی از Win XP به Win 7 منتقل شود
برخی از مولفه های موجود در VMware Mirage عبارتند از:
Mirage Client – فایلی قابل اجرا بر روی client endpoint است و به یک Mirage server یا به load balanced Mirage servers برای واکشی بروزرسانی ها از دسکتاپ مجازی مرکزی، متصل می شود.
Mirage Management Server – یک کنسول اجرایی است که Mirage Server Cluster را کنترل و مدیریت می کند
Mirage Server – در دیتاسنتر قرار می گیرد و عملکرد اصلی آن همگام سازی کلاینت ها با دسکتاپ مجازی مرکزی است. همچنین در برابر تحویل لایه Base ، لایه اپلیکیشن و دسکتاپ مجازی مرکزی به کلاینت ها مسئول است و آنها را بر روی کلاینت یکپارچه می کند.
Mirage Management Console – یک GUI است که برای نگهداری، مدیریت و نظارت بر endpoint های نصب شده استفاده می شود. ادمین می تواند Mirage client ها، لایه های Base و لایه های اپلیکیشن را کانفیگ کند. همچنین با استفاده از Management console می تواند بر روی دسکتاپ مجازی مرکزی تغییرات را اعمال نماید.
Centralized Virtual Desktop – محتوای کامل هر PC است. این داده به Mirage Server منتقل می شود و در آنجا ذخیره می گردد. از دسکتاپ مجازی مرکزی برای مدیریت، بروزرسانی، patch، پشتیبان گیری، عیب یابی، بازیابی و ارزیابی دسکتاپ در دیتاسنتر استفاده می شود.
VMware Horizon Workspace
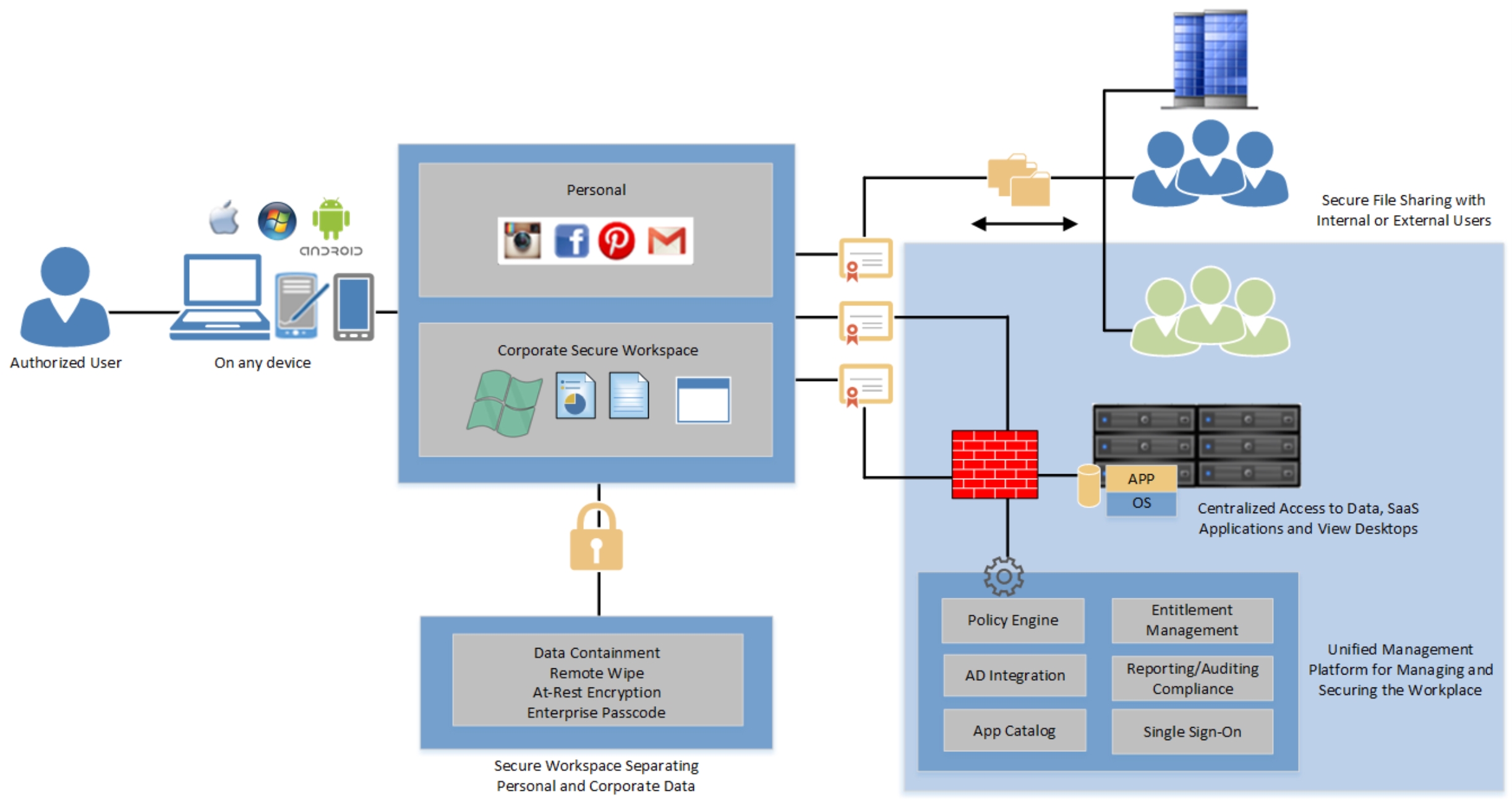
یک نرم افزار مدیریت اینترپرایز است که واسط مرکزی واحدی را جهت دسترسی ایمن فراهم می کند. شما در هر زمان و از هر مکانی می توانید از طریق لپتاپ خود، کامپیوترهای خانگی و دستگاه های موبایل android یا ios به اپلیکیشن ها، دسکتاپ ها، فایل ها و سرویسهای وب کمپانی دسترسی یابید
مدیران شبکه از طریق پلتفرم مدیریت مبتنی بر وب می توانند مجموعه ای customize از دسترسی به اپلیکیشن و داده را برای کاربران فراهم کنند که شامل تنظیمات security policy و مجوز استفاده از اپلیکیشن ها می شود. سازمان ها می توانند به سادگی دستگاه های جدید، کاربران جدید یا اپلیکیشن های جدید را برای یک گروه از کاربران بدون نیاز به کانفیگ دوباره دستگاه ها یا endpoint ها اضافه کنند.
برخی از مولفه های اصلی در Horizon Workspace عبارتند از:
Workspace Configurator – یک کنسول مدیریتی و واسط کاربری تحت web است که برای مدیریت مرکزی SSL همچنین تنظیمات شبکه، Gateway، vCenter و SMTP در Horizon vApp استفاده می شود.
Workspace Manager – یک واسط اجرایی تحت وب است که کانفیگ application catalog، user entitlement management و system reporting را ممکن می سازد.
Workspace Data – به عنوان یک datastore برای فایل های کاربر عمل می کند. سیاست های به اشتراک گذاری فایل ها را کنترل و سرویس های نمایش فایل را فراهم می کند.
Workspace Connector – قابلیت هایی را برای احراز هویت کاربر local و پیوست Active Directory و سرویس های همگام سازی فراهم می کند. ThinApp catalog loading و View pool synchronization از دیگر خدماتی است که ارائه می دهد.
Workspace Gateway – به عنوان یک namespace واحد برای همه تعاملات Workspace عمل می کند و دامنه ای برای دسترسی به Worspace ایجاد می کند. همچنین به عنوان بخشی مرکزی برای تجمیع همه اتصالات کلاینت است و ترافیک کلاینت را به مقصد درست مسیریابی می کند.
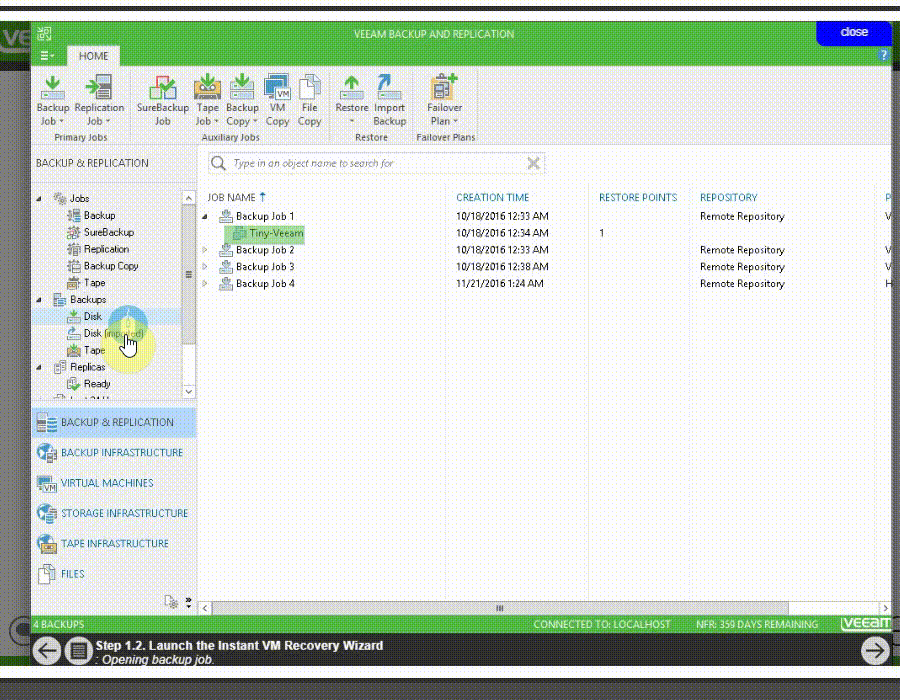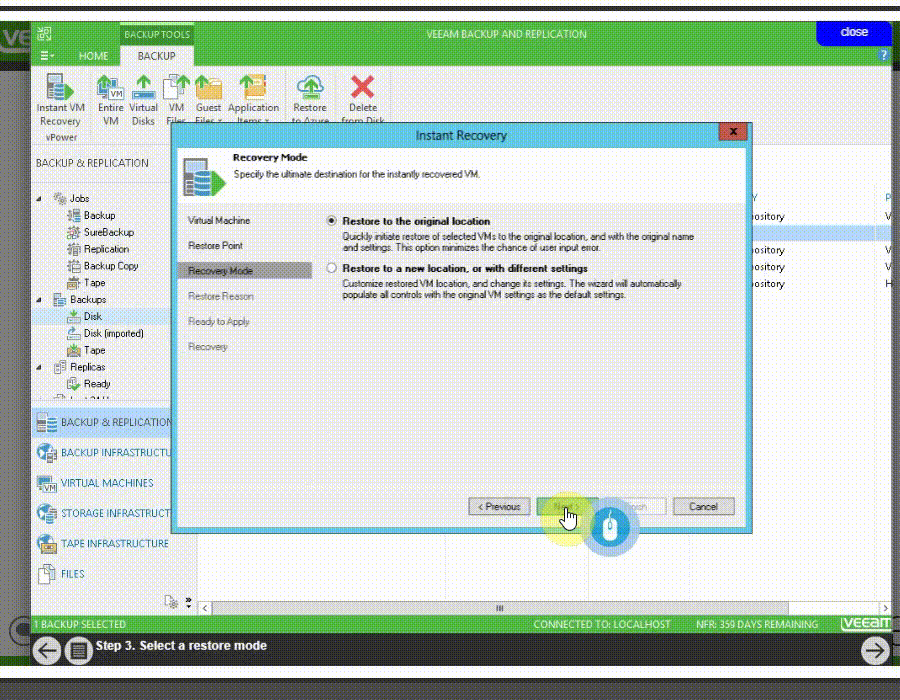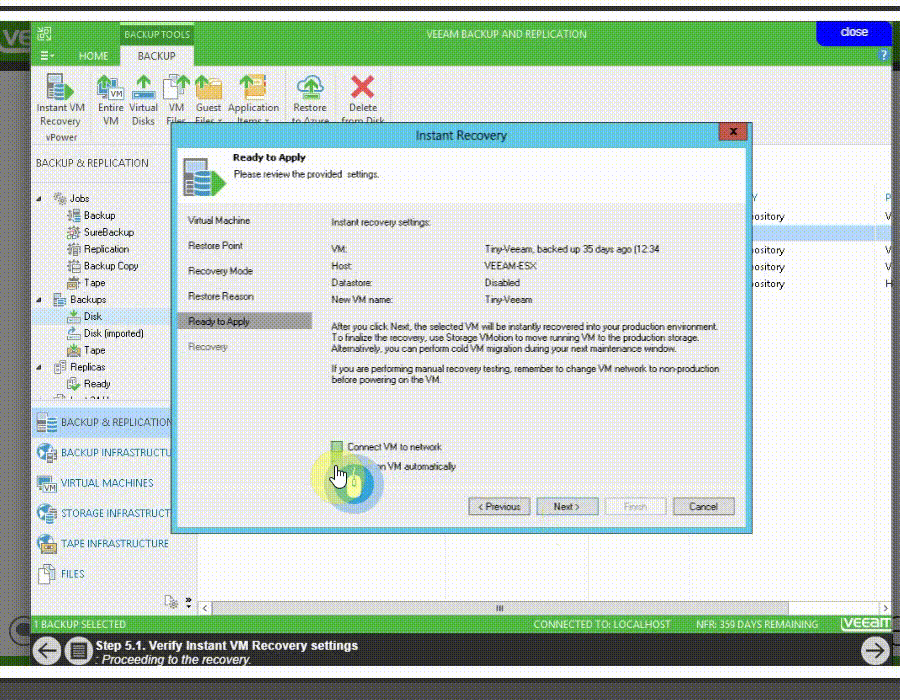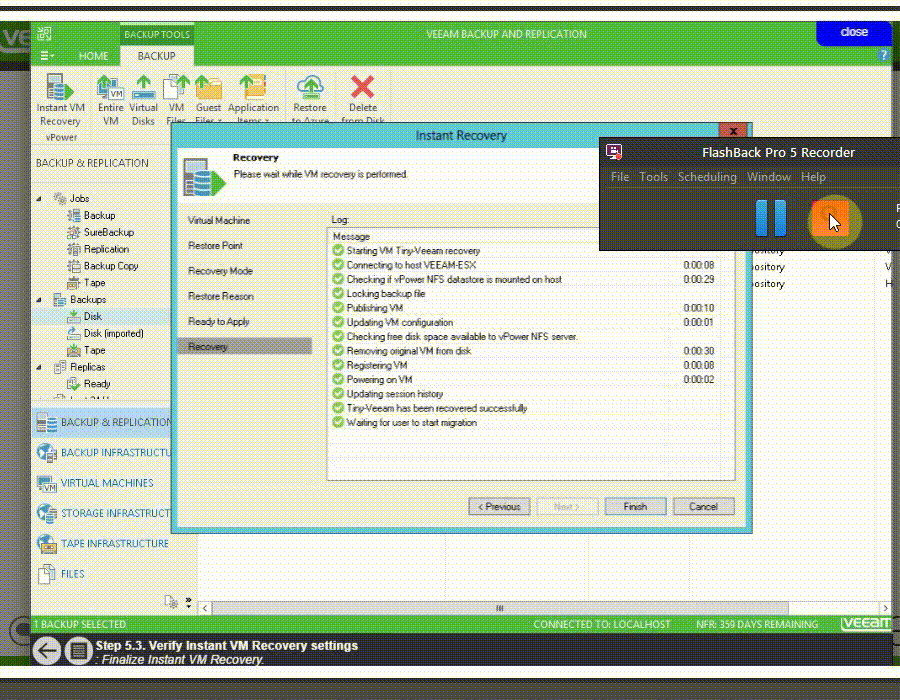
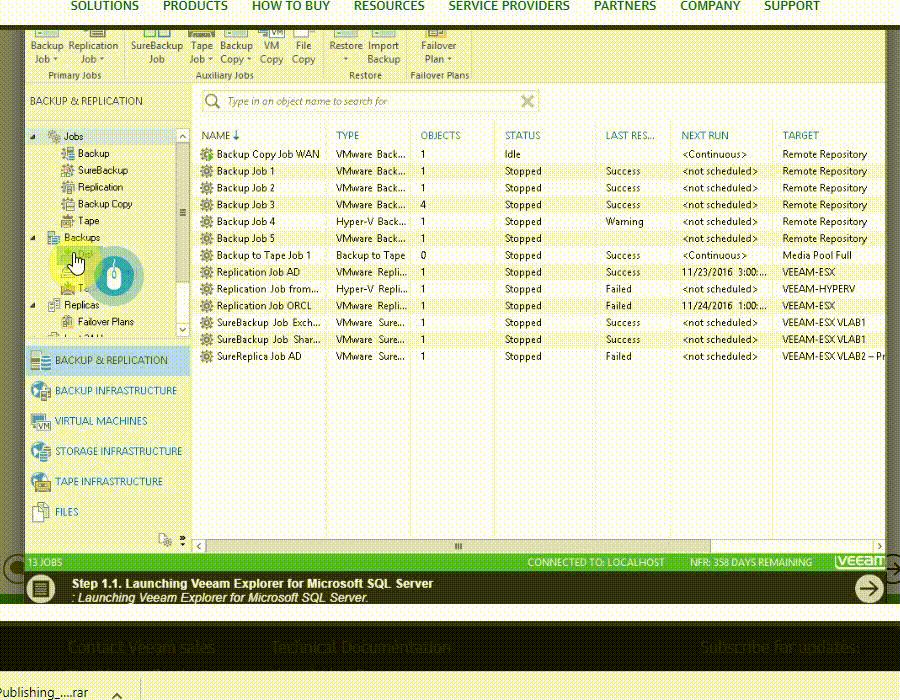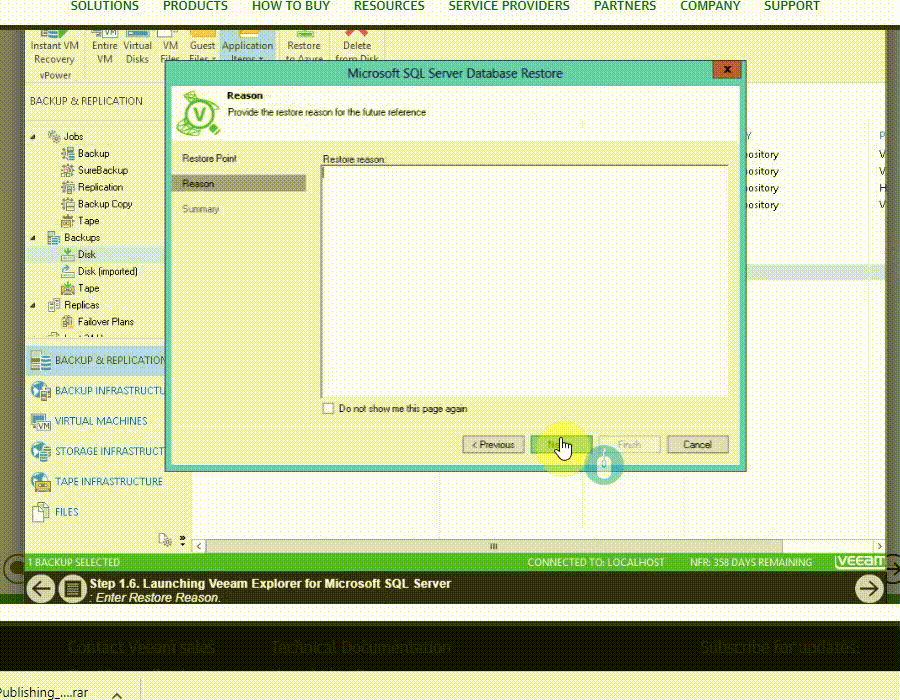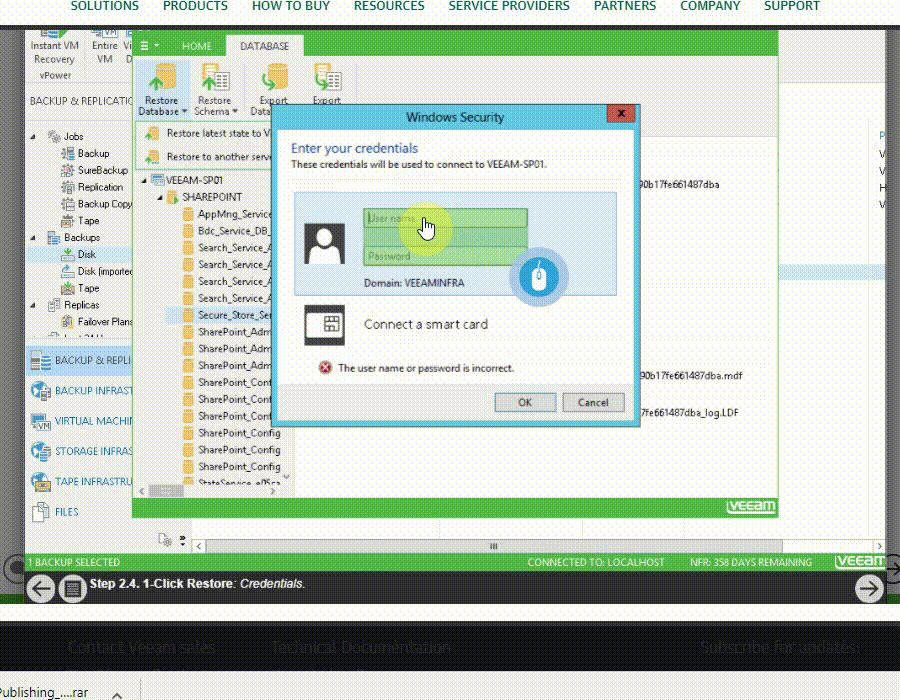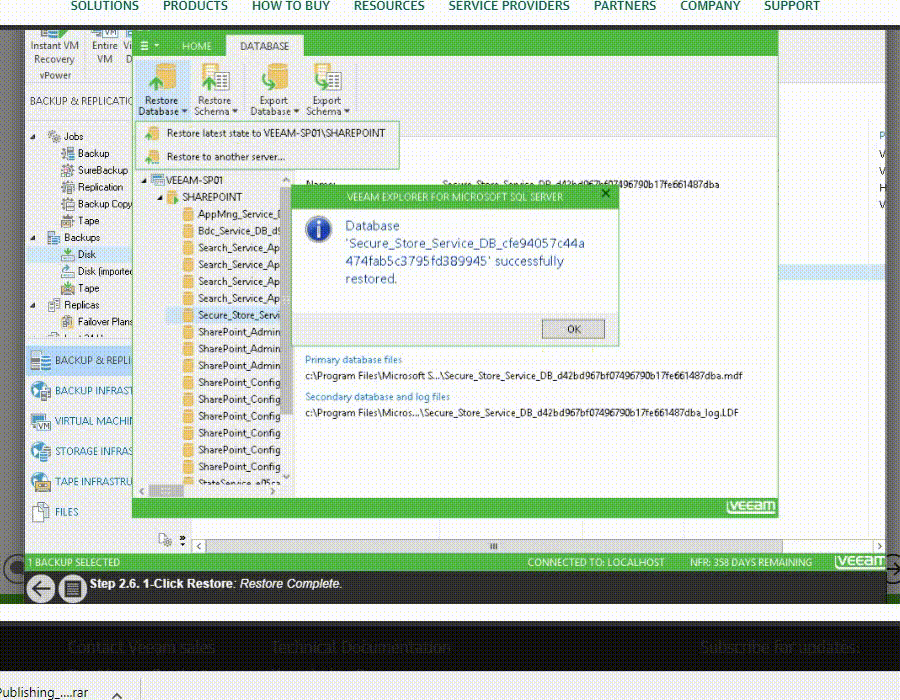
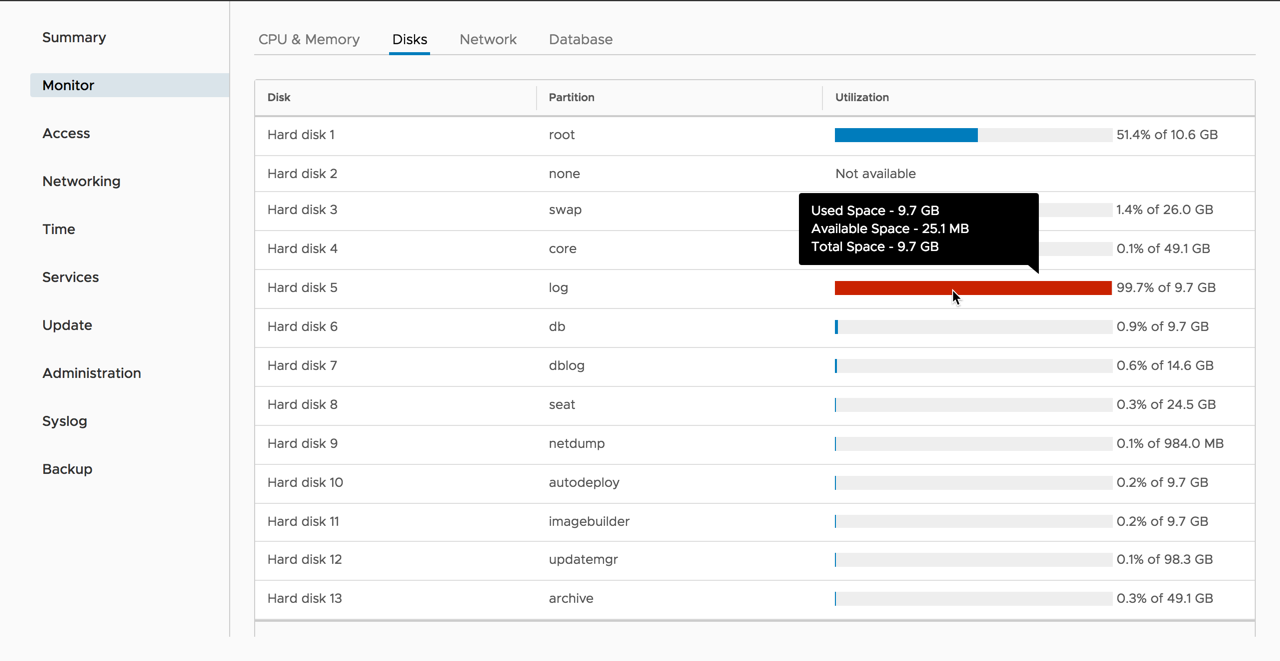
يکي از اساسي ترين مسايل براي فهم پشتيبان گيري (backup) و بازيابي (recovery) ، مفهومِ سطوح backup است و اينکه هر يک از اين سطوح چه معنايي دارند.
فقدانِ درک صحيح از اينکه اين سطوح چه هستند و چگونه به کار گرفته مي شوند، منجر شده است که سازمان ها تجربه ناخوشايندي از پهناي باند و فضاي ذخيره سازي به هدر رفته اي داشته باشند که جهت از دست نرفتن داده هاي مهم در پشتيبان گيري از اطلاعات به آنها تحميل مي شود. همچنين درک اين مفاهيم به هنگام انتخاب محصولات يا خدمات حفاظت از اطلاعات بسيار ضروري است.
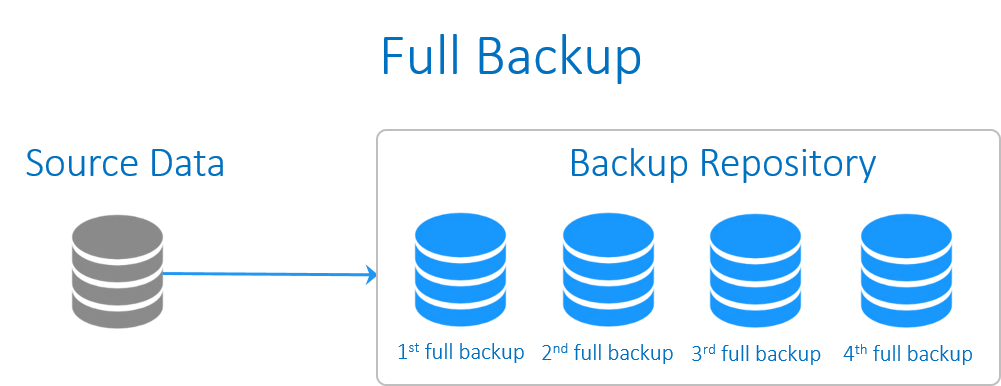
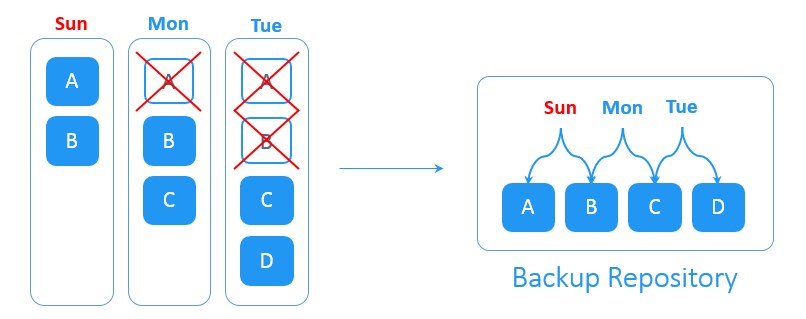
Full backup
پشتيبان گيريِ کامل، شامل همه داده هاي کل سيستم مي شود. بکاپ کامل از Windows system ، بايد کپي هر يک از فايل ها بر روي هر درايو از ماشين يا VM را در برگيرد.
تنها چيزي که در پشتيبان گيري کامل حذف مي شود، فايل هايي هستند که از طريق پيکربندي مستثنا مي شوند. به طور مثال، اکثر ادمين هاي سيستم تصميم مي گيرند که دايرکتوري هايي را که در طول بازگرداني ارزشي ندارند (به طور مثال، /boot يا /dev) يا دايرکتوري هاي شامل فايل هاي موقتي (به طور مثال، C:\Windows\TEMP در ويندوز، يا /tmp در لينوکس) حذف شوند.
در مورد اينکه فرآيند پشتيبان گيري از اطلاعات شامل چه فايل هايي بايد شود، دو رويکرد وجود دارد: از همه چيز بکاپ بگيريد و چيزهايي را که مي دانيد به آنها نياز نداريد را حذف کنيد، يا اينکه تنها چيزي را که مي خواهيد از آن بکاپ بگيريد، انتخاب کنيد. اولين رويکرد گزينه اي امن تر است و رويکرد دوم نيز منجر به صرفه جويي در فضاي سيستم از اطلاعات شما خواهد شد. برخي معتقدند که پشتيبان گيري از فايل هاي اپليکيشن همچون دايرکتوري هاي شاملSQL Server يا Oracle ، بيهوده است و به سادگي در طول فرآيند بازگرداني، اپليکيشن را دوباره بارگذاري مي کنند. مشکل رويکرد اخير اين است که احتمال دارد شخصي داده اي ارزشمند را در يک دايرکتوري قرار دهد که براي پشتيبان گيري انتخاب نشده است. به فرض اگر شما تنها دايرکتوريِ home/ يا D:\Data را براي پشتيبان گيري برگزينيد، چگونه سيستمِ بکاپ تشخيص خواهد داد که شخصي اطلاعاتي مهم را در ديگر دايرکتورها ذخيره کرده است؟ به همين دليل، با وجود اينکه رويکرد اول فضاي زيادتري را اشغال مي کند، پشتيبان گيري از همه چيز روشي امن تر مي باشد و تنها فايلهايي که نيازي نداريد، حذف مي شوند. البته اگر شما يک محيطِ به شدت کنترل شده داشته باشيد که در آن همه داده ها در مکاني مشخص بارگذاري شده باشند و راهکار هماهنگ شده ي مناسبي براي جابجايي سيستم عامل و اپليکيشن ها در فرآيند بازگرداني داشته باشيد، استفاده از راهکار دوم برايتان موثر خواهد بود.
از آنجايي که حجم عظيمي از داده ها بايد کپي شوند، در اين فرآيند زمان بسياري صرف خواهد شد (در مقايسه با انواع ديگر از روش هاي بکاپ گيري از اطلاعات ، اين روش 10 برابر زمان بيشتري را صرف مي کند). در نتيجه در هر نوبتِ پشتيبان گيري، بارکاري قابل ملاحظه اي به شبکه تحميل مي شود و با عمليات روتينِ شبکه شما تداخل پيدا مي کند. همچنين بکاپ گيري از اطلاعات به طور کامل حجم بالايي از فضاي ذخيره سازي را نيز اشغال مي کند.
به همين دليل است که بکاپ گيري از اطلاعات به طور کامل تنها به صورت دوره اي گرفته خواهد شد و آن را با انواع ديگر بکاپ ترکيب مي کنند.
فوايد پشتيبان گيري از اطلاعات به طور کامل:
ريکاوري سريعِ داده ها به هنگام رخدادِ يک disaster
مديريت بهتر ذخيره سازي، از آنجايي که تمام مجموعه داده ها در يک فايل بکاپِ واحد ذخيره مي شوند
معايب پشتيبان گيري از اطلاعات به طور کامل:
با وجود اينکه بکاپ گيري از اطلاعات به طور کامل، مزيت هاي بالا را براي شما به ارمغان مي آورد اما شامل نقاط ضعف بسياري نيز هست:
اجراي بکاپِ کامل، زمان بسياري زيادي را به خود اختصاص مي دهد
شما نياز به يک ذخيره ساز با ظرفيت بسيار بالا خواهيد داشت تا بتواند همه بکاپ هاي شما را دربر گيرد
از آنجايي که هر فايلِ full backup شامل کل مجموعه داده هاي شماست (که اغلب محرمانه هستند)، اگر اين داده ها به دسترسي شخصي فاقدِ صلاحيت برسند، کسب و کار شما دچار مخاطره مي شود. هر چند اگر راهکار بکاپِ شما از ويژگي data protection پشتيباني نمايد، مي توان از اين خطرات پيشگيري نمود.
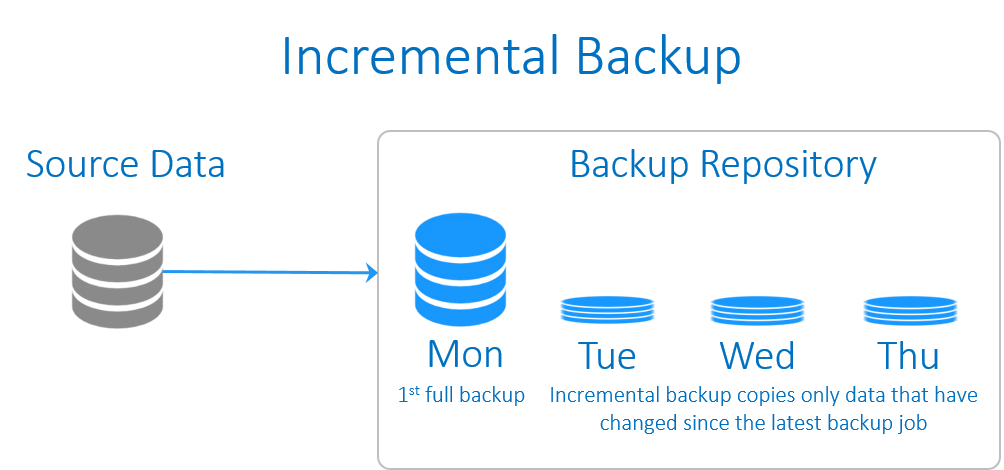
incremental backup (پشتيبان گيري افزايشي)
بکاپِ افزايشي معمولا از داده هايي پشتيبان مي گيرد که از زمان آخرين بکاپِ گرفته شده (هر نوعي از بکاپ که باشد)، تغييري روي آنها صورت گرفته باشد. گرفتن يک بکاپِ کاملِ اوليه از پيش شرط هاي ايجادِ بکاپِ افزايشي است. و بسته به سياست هاي ذخيره سازيِ بکاپ، پس از يک دوره زماني معين به يک full backup جديد براي تکرار اين سيکل نياز است.
برخي از اين نوع بکاپ ها، بکاپ هاي file-based هستند به اين معنا که از همه فايلهايي که نسبت به آخرين زمان بکاپ تغيير کرده باشند، بکاپ تهيه مي شود. در حالي که ما به روش هاي مختلف مي کوشيم تا تاثير I/O ناشي از بکاپها بر روي سرور (به خصوص به هنگام پشتيبان گيري از VM ها) را کاهش دهيم، در اين شيوه بکاپ گيري از اطلاعات با چالشي در اين مورد مواجه خواهيم شد. چرا که پشتيبان گيري از يک فايل 10GB که تنها 1 MB از آن تغيير کرده است، چندان کارآمد نيست.
به دليل ناکارآمدي در شيوه file-based، اکثر کمپاني ها به سمت بکاپ افزايشيِ block-based رفته اند که در آن تنها از بلاک هاي تغيير يافته، بکاپ گرفته مي شود. رايجترين روش براي انجام آن هنگامي است که از محصولات نرم افزاري بکاپ تهيه مي شود، به طور مثال از VMware يا Hyper-V با استفاده از API هر يک از آنها، مي توان پشتيبان تهيه نمود. هر App يک API مناسب خود را اعلام مي کند که بکاپ افزايشيِ block-based را انجام مي دهد.
ويژگي ها
از لحاظِ سرعتِ پشتيبان گيري/بازگرداني، بکاپ differential به عنوانِ راهکاري است که در ميانِ دو راهکار بکاپِ کامل و بکاپ افزايشي قرار مي گيرد:
عمليات بکاپ گيري از اطلاعات در آن کندتر از بکاپ افزايشي اما سريعتر از بکاپ کامل است
عمليات بازگردانيِ آن، آهسته تر از بکاپ کامل اما سريع تر از بکاپ افزايشي است
فضاي ذخيره سازي لازم براي بکاپِ differential، حداقل در يک دوره مشخص، کمتر از فضاي لازم براي بکاپِ کامل و بيشتر از فضاي مورد نياز براي بکاپ افزايشي است.
Mirror backup
اين راهکار مشابه با بکاپ گيري از اطلاعات به طور کامل است. اين نوع بکاپ گيري از اطلاعات، کپي دقيقي از مجموعه داده ها ايجاد مي کند با اين تفاوت که بدون رديابيِ نسخه هاي مختلفِ فايل ها، تنها آخرين نسخه از داده در بکاپ ذخيره مي شود.
بکاپِ Mirror ، فرآيند ايجاد کپي مستقيمي از فايل ها و فولدرهاي انتخاب شده، در زماني معين است. از آنجايي که فايل ها و فولدرها بدون هيچ گونه فشرده سازي در مقصد کپي مي شود، سريع ترين انواع روش هاي پشتيبان گيري از اطلاعات است. با وجود سرعت افزايش يافته در آن، نقاط ضعفي را نيز به همراه خواهد داشت: به فضاي ذخيره سازي وسيعتري نياز دارد و نمي تواند از طريق رمز عبور محافظت شود.
در اين نوع از بکاپ گيري، هنگامي که فايل هاي بي کاربرد حذف مي شوند، از روي بکاپِ mirror نيز حذف خواهند شد. بسياري از خدماتِ بکاپ ، بکاپِ mirror را با حداقل 30 روز فرصت براي حذف پيشنهاد مي کنند. به اين معناست که به هنگام حذف يک فايل از منبع، آن فايل حداقل 30 روز بر روي storage server نگهداري مي شود.
ويژگي ها
امتيازي که بکاپِ mirror در اختيار شما مي گذارد، بکاپي درست است که شامل فايل هاي منسوخ شده و قديمي نمي شود.
و اما معايب آن زماني خود را نشان خواهد داد که فايل ها به صورت تصادفي يا به واسطه ويروس ها از منبع حذف شده باشند.
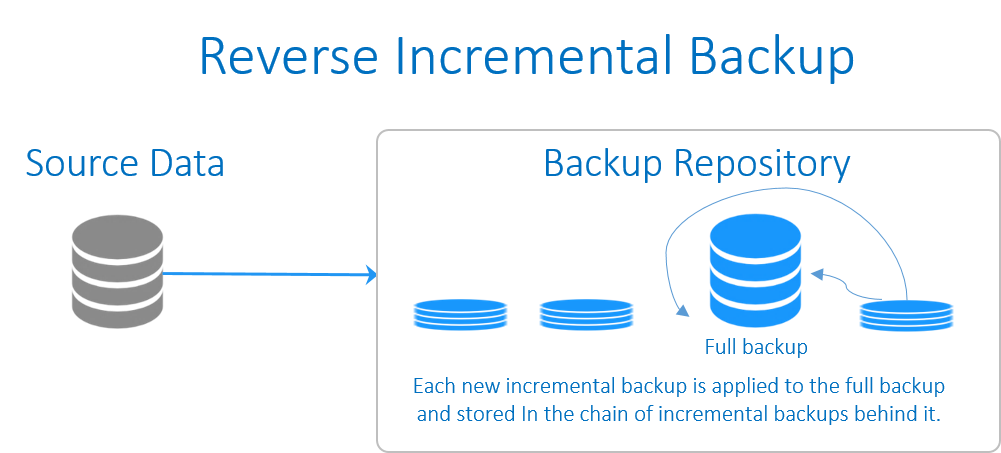
در اين نوع بکاپ گيري از اطلاعات نيز براي شروع به يک بکاپ کامل اوليه نياز است. پس از ايجاد بکاپِ کامل اوليه، هر بکاپ افزايشيِ موفق تغييرات را به نسخه پيشين اعمال مي کند که در نتيجه آن در هر زمان يک بکاپ کاملِ جديد (به صورت مصنوعي) ايجاد مي شود. در حالي که کماکان توانايي بازگشت به نسخه هاي پيشين وجود دارد. هر يک از بکاپ هاي افزايشيِ اعمال شده به بکاپ کامل، نيز ذخيره مي شوند که در زنجيره اي از بکاپ ها، به طور مستمر در پشت سرِ بکاپ کاملِ به روز شده، در جريان هستند.
امتياز اصلي در اين نوع از بکاپ گيري فرآيند بازيابي کارآمدترِ آن است، چرا که بخش زيادي از جديدترين نسخه هاي داده به بکاپ کامل اوليه اضافه مي شود و نيازي نداريد بکاپ هاي افزايشي را در طول بازيابي بکار ببنديد. در گيف زير فرآيند اجراي اين نوع بکاپ نشان داده شده است.
Smart backup (پشتيبان گيري هوشمند)
پشتيبان گيري هوشمند، ترکيبي از بکاپ هاي کامل، افزايشي و تفاضلي است. بسته به هدفي که در بکاپ گيري از اطلاعات در نظر داريد و همچنين فضاي ذخيره سازيِ در دسترس، بکاپ هوشمند مي تواند راهکاري کارآمد را ارائه دهد. جدول زير ايده اي در رابطه با چگونگي کارکرد اين نوع بکاپ، در اختيار شما مي گذارد.
با استفاده از بکاپ هوشمند، هميشه مي توانيد تضمين نماييد که فضاي ذخيره سازيِ کافي براي بکاپ هاي خود در اختيار داريد.
Continuous Data Protection (محافظت مستمر از داده)
بر خلاف بکاپ هاي ديگر که به صورت دوره اي انجام مي شوند، CDP از هر تغييري در مجموعه داده هاي منبع log تهيه مي کند که از سويي مشابه با بکاپِ mirror است. اختلاف CDP با mirror در اين است که log مربوط به تغييرات براي بازيابيِ نسخه هاي قديمي تر از داده مي تواند بازيابي شود.
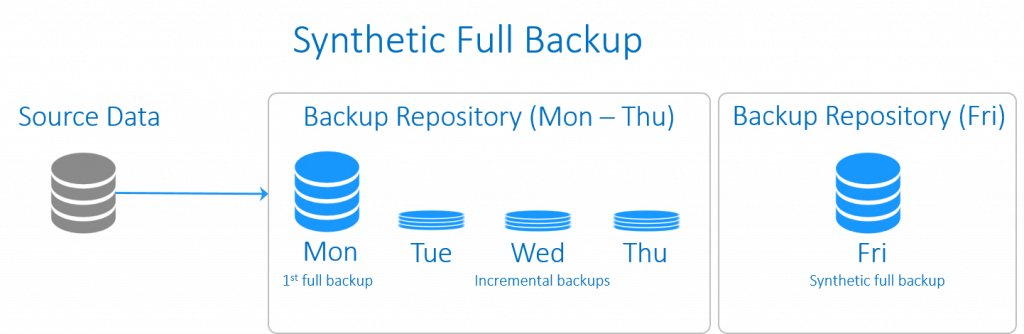
Synthetic Full Backup (بکاپ کامل ساختگي)
اين نوع از بکاپ شباهت هاي بسياري با بکاپ افزايشي معکوس دارد. اختلافِ آنها در چگونگي مديريت داده هاست. بکاپ کامل مصنوعي با اجراي بکاپ کاملِ مرسوم آغاز مي شود که در ادامه مجموعه اي از بکاپ ها افزايشي را در پي دارد. در زماني معين، بکاپ هاي افزايشي هماهنگ مي شوند و به بکاپ کاملِ موجود اعمال مي شوند تا بکاپ کاملي را به طور مصنوعي و به عنوان يک نقطه شروعِ جديد ايجاد نمايند.
بکاپ کاملِ ساختگي، تمامي امتيازات يک بکاپ کامل را دارد، در حالي که زمان و فضاي ذخيره سازيِ کمتري را صرف مي کند.
از جمله مزاياي بهره وري از بکاپ کامل ساختگي عبارتند از:
عمليات بازيابي و بکاپ گيريِ سريع
مديريتِ بهترِ ذخيره ساز
نياز کمتر به فضاي ذخيره سازي
يارهاي کاريِ کمتر در شبکه
Forever-Incremental Backup
اين راهکار با بکاپ افزايشي عادي متفاوت است. همچون اکثر راهکارهاي پيشين براي شروع به يک بکاپ کامل اوليه به عنوان يک نقطه مرجع براي ردگيري تغييرات نياز دارد. از آن لحظه، تنها بکاپ هاي افزايشي بدون هيچ گونه بکاپ کاملِ دوره اي ايجاد مي شوند.
فرض کنيد که شما بکاپ کامل را در روز شنبه ايجاد کرديد. با شروع روز بعد، بکاپ هاي افزايشي به صورت روزانه ايجاد مي شوند. در روز يکشنبه دو بلوک جديدِ A و B در مجموعه داده هاي منبع ايجاد شده اند. در روز دوشنبه بلوک A حذف و بلوکِ جديد C بر روي منبع ايجاد شده است. در روز سه شنبه بلوک B حذف و بلوک جديد D ايجاد شده است. سيستمِ forever-incremental backup تماميِ تغييرات روزانه را پيگيري مي کند. حذف بلوک هاي داده تکراري تا فضاي ذخيره سازي مورد نياز براي بکاپ را کاهش دهد.
يا توجه به سياست هاي ويژه در زمينه نگهداري بکاپ ها، پس از ايجادِ مجموعه اي از بکاپ هاي افزايشي، نقاط بکاپ گيري و بازيابيِ منقضي شده حذف مي شوند تا فضاي ذخيره سازيِ اشغال شده در backup repository آزاد شود.
امتيازاتي که روش بکاپ گيريِ forever-incremental نصيب شما خواهد کرد نيز مشابه با روشِ بکاپ کامل ساختگي است.
جمع بندي
در حقيقت راهکار بکاپ گيري از اطلاعات خوب يا بد وجود ندارد. بايد در نظر بگيريد که چه نوعي از بکاپ گيري براي شما بهترين است و نيازهاي ويژه ي سازمانِ شما را بر مبناي سياست هاي محافظت از داده، ذخيره سازِ موجود، منابع، پهناي باند شبکه، نواحي داده اي مهم و …. برآورده مي سازد.
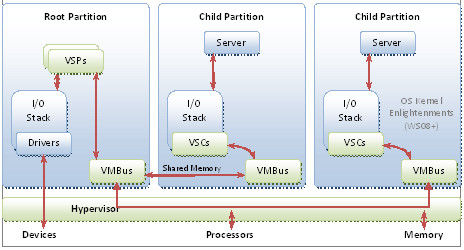
Hyper-V features a Type 1 hypervisor-based architecture. The hypervisor virtualizes processors and memory and provides mechanisms for the virtualization stack in the root partition to manage child partitions (virtual machines) and expose services such as I/O devices to the virtual machines.
The root partition owns and has direct access to the physical I/O devices. The virtualization stack in the root partition provides a memory manager for virtual machines, management APIs, and virtualized I/O devices. It also implements emulated devices such as the integrated device electronics (IDE) disk controller and PS/2 input device port, and it supports Hyper-V-specific synthetic devices for increased performance and reduced overhead.
The Hyper-V-specific I/O architecture consists of virtualization service providers (VSPs) in the root partition and virtualization service clients (VSCs) in the child partition. Each service is exposed as a device over VMBus, which acts as an I/O bus and enables high-performance communication between virtual machines that use mechanisms such as shared memory. The guest operating system’s Plug and Play manager enumerates these devices, including VMBus, and loads the appropriate device drivers (virtual service clients). Services other than I/O are also exposed through this architecture.
Starting with Windows Server 2008, the operating system features enlightenments to optimize its behavior when it is running in virtual machines. The benefits include reducing the cost of memory virtualization, improving multicore scalability, and decreasing the background CPU usage of the guest operating system.
The following sections suggest best practices that yield increased performance on servers running Hyper-V role.
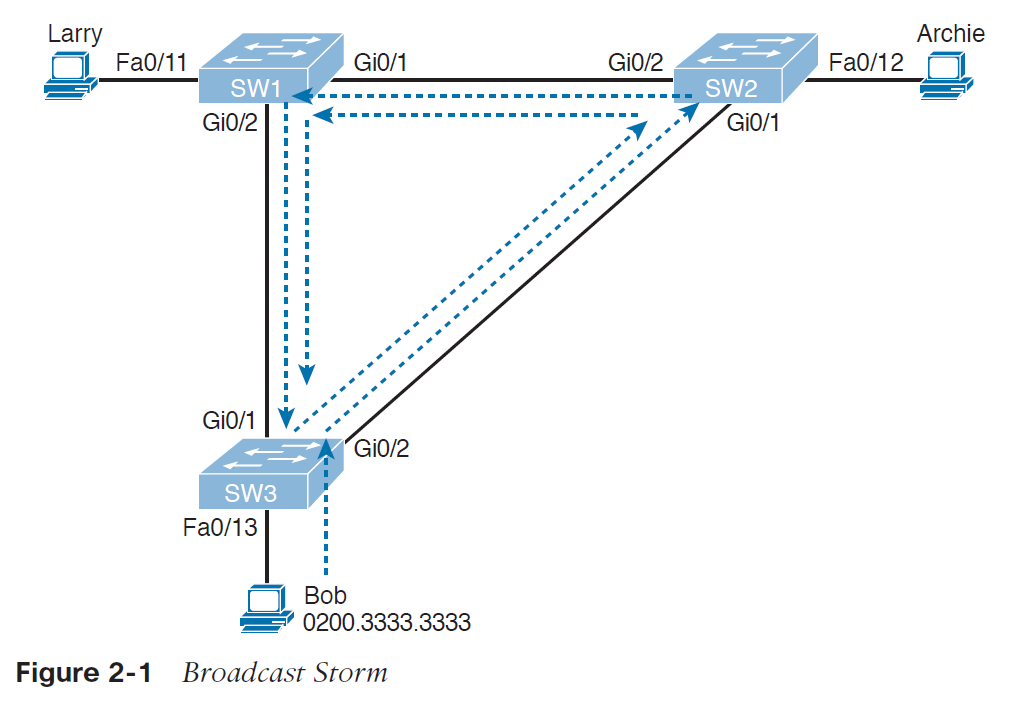
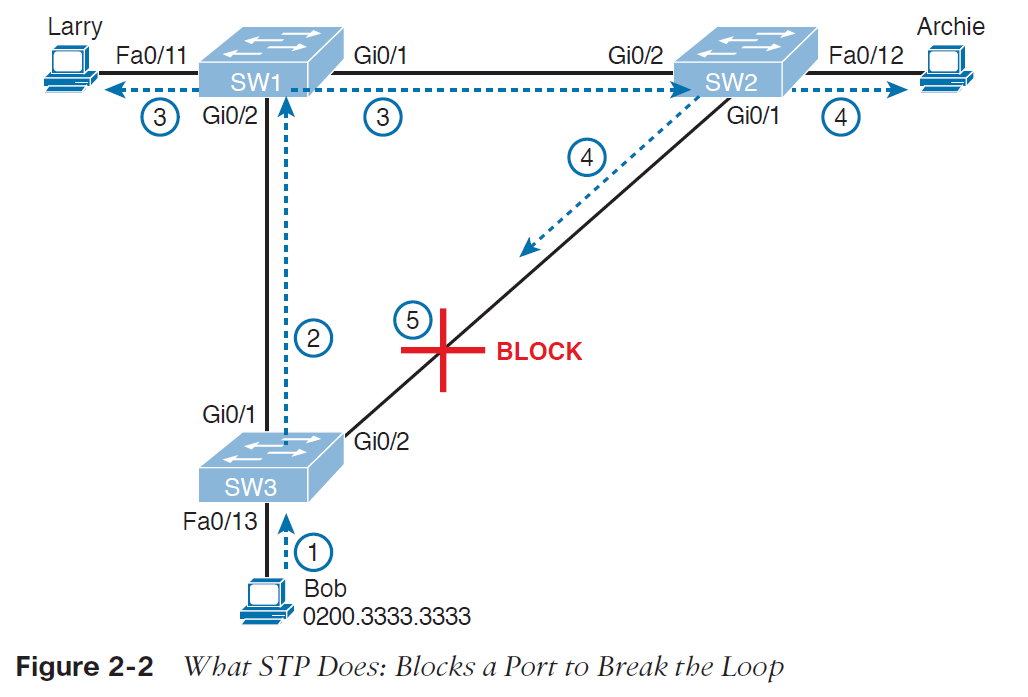
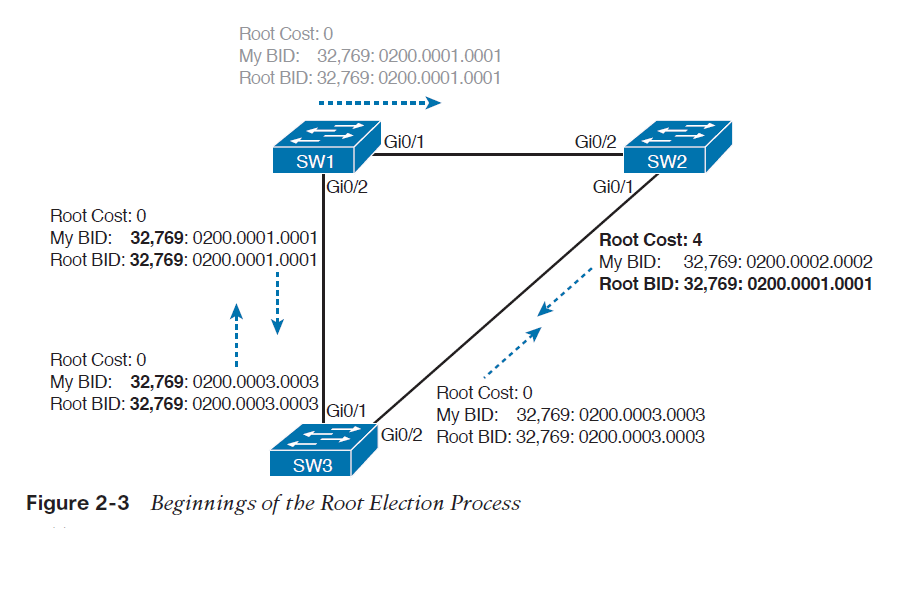
در یک شبکه lan، اگر تمامی بسته ها به مقصد سگمنت های دیگر شبکه توسط روتری یکسان فرستاده شوند، هنگامی که gateway از کار بیافتد، همه ی هاست هایی که از آن روتر به عنوان next-hop پیش فرض استفاده می کنند در برقراری ارتباط با شبکه های خارجی موفق نخواهند بود. برای رفع این مشکل، سیسکو پروتکل اختصاصی HSRP را ارائه داده است که برای gateway ها در یک lan ، افزونگی ایجاد می کند تا قابلیت اطمینان شبکه را افزایش دهد.
یکی از راه های دستیابی به uptime نزدیک به 100 درصد در شبکه، استفاده از پروتکل HSRP است که افزونگی را در شبکه های IP ، ارائه می دهد. HSRP تضمین خواهد کرد که به هنگام ایجاد خطا در دستگاه ها یا مدارهای دسترسی که در لبه (edge) شبکه قرار دارند، ترافیک های کاربر بلافاصله به بیرون شبکه ارسال شوند.
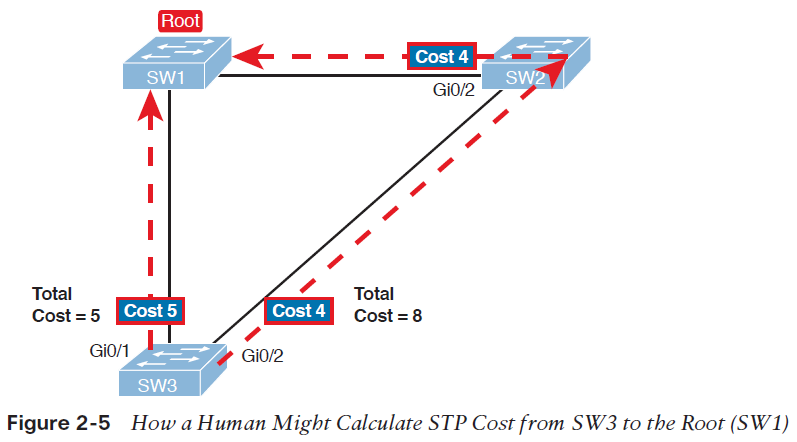
با به اشتراک گذاشتن یک آدرس IP و آدرس MAC (لایه 2) میان دو یا تعدادی بیشتری از روترها، آنها می توانند به عنوان یک روتر مجازیِ واحد (virtual router) عمل نمایند. روترهای عضو در این گروه، به طور مستمر برای رصد وضعیت روترهای دیگر پیام هایی را با یکدیگر مبادله می نمایند. در نتیجه هر روتر مسئولیت مسیریابی روتری دیگر را نیز بر عهده خواهد گرفت. و بر پایه این پروتکل، هاست ها می توانند بسته های IP را به آدرس MAC و IP پایداری ارسال نمایند.
مکانیزم های پویا برای تشخیص روتر
در ادامه مکانیزم های موجود برای تشخیص روتر توسط هاست تشریح می شود. بسیاری از این مکانیزم ها منجر به تاب آوری (resiliency) بیشترِ شبکه نمی شوند. این مسئله به این معنا می تواند باشد که در ابتدا برای پروتکل ها قابلیت تاب آوریِ شبکه در نظر گرفته نمی شد یا اینکه اجرای پروتکل برای هر هاست از شبکه ممکن نبود. باید این را در نظر داشته باشید که بسیاری از هاست ها، تنها مجوز تنظیمِ default gateway را به شما می دهند.
Proxy Address Resolution Protocol
برخی از هاست ها از پروتکل (proxy Address Resolution Protocol (ARP برای انتخاب یک روتر استفاده می کنند. هنگامی که یک هاست proxy ARP را اجرا می کند، به منظور دستیابی به آدرس IP هاستی که قصد ارتباط با آن را دارد، یک درخواست ARP ارسال می کند. فرض کنید روتر A در شبکه، از طرف هاستِ مقصد پاسخ می دهد و آدرس MAC اش را در اختیار می گذارد. به واسطه ی پروتکل ARP ، هاست مبدا با هاست راه دور به گونه ای برخورد می کند که گویی به همان سگمنت از شبکه متصل است. اگر روتر A از کار بیافتد، هاست مبدا به ارسال بسته ها به هاست مقصد از طریق آدرس MAC مربوط به روتر A ادامه می دهد، با آنکه این بسته ها به مقصدی ارسال نمی شوند و از بین می روند. شما می توانید منتظر بمانید تا پروتکل ARP ، آدرس MAC یک روتر دیگر بر روی همان سگمنت ،به فرض روتر B ، را به دست آورد. آدرس روتر B از طریق ارسال یک درخواستِ دیگر ARP یا راه اندازی مجددِ هاست مبدا برای ارسال درخواست ARP به دست می آید. از طرف دیگر برای مدت زمانی قابل توجه، هاست مبدا نمی تواند با هاست راه دور ارتباط برقرار کند، با وجود اینکه انتقال بسته هایی که پیش از این توسط روتر A ارسال می شدند از طریق روتر B میسر می شود.
Dynamic Routing Protocol
برخی از هاست ها یک پروتکل مسیریابی پویا همچون (Routing Information Protocol (RIP یا (Open Shortest Path First (OSPF را اجرا می کنند تا روترها را بیابند. نقطه ضعفِ پروتکل RIP، سرعتِ کُندِ آن برای به کارگیری تغییرات در توپولوژی است. اجرای یک پروتکل مسیریابی پویا بر روی هر هاست، به دلایلی ممکن است، عملی نباشد. که این دلایل شاملِ administrative overhead ، processing overhead ، مسائل امنیت یا عدم امکانِ پیاده سازی پروتکل بر روی برخی از پلتفرم ها می شود.
(ICMP Router Discovery Protocol (IRDP
به هنگام عدم دسترسی پذیری به یک مسیر، برخی از هاست های جدیدتر از IRDP برای یافتن روتری جدید استفاده می کنند. هاستی که IRDP را اجرا می کند به پیام های multicast دریافت شده از روتر پیش فرضِ خود گوش فرا می دهد و هنگامی که پس از مدتی پیام های hello را دریافت نکند، از یک روتر جایگزین بهره می برد.
Dynamic Host Configuration Protocol
پروتکل DHCP مکانیزمی را برای انتقال اطلاعات کانفیگ به هاست ها بر روی شبکه TCP/IP ارائه می دهد. این اطلاعات کانفیگ معمولا شامل آدرس IP و default gateway می شود. اگر default gateway از کار بیافتد، هیچ مکانیزمی برای تغییر به روتری جایگزین وجود ندارد.
عملیات HSRP
در بسیاری از هاست ها تشخیص پویا پشتیبانی نمی شود. بنا به دلایلی که پیشتر ذکر شد، اجرای یک مکانیزم تشخیص پویای روتر بر روی هر هاست از شبکه نیز ممکن است تحقق پذیر نباشد. در نتیجه پروتکل HSRP برای این هاست ها failover service را فراهم می کند.
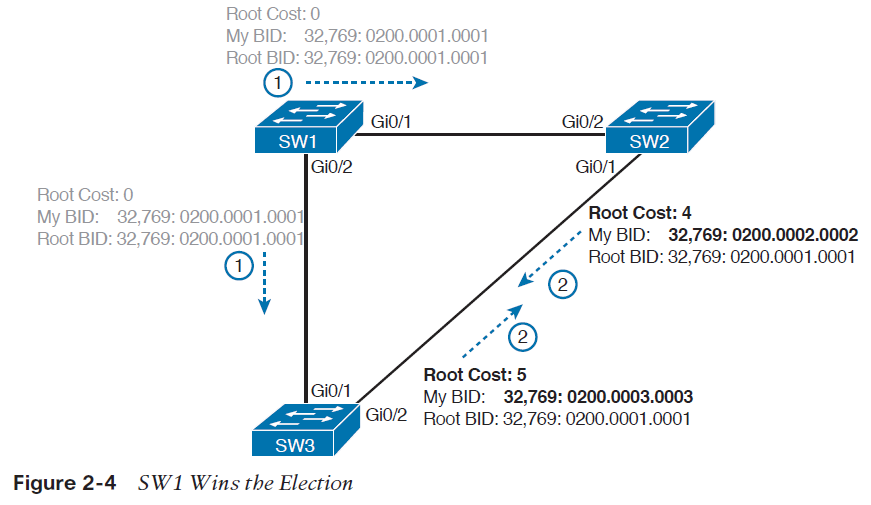
با استفاده از HSRP ، مجموعه ای از روترها به صورت همزمان فعالیت می کنند تا به عنوان یک روتر مجازی واحد به هاست های موجود بر روی LAN نشان داده می شوند. این مجموعه به عنوان گروه HSRP یا گروه standby شناخته می شوند. یک روترِ برگزیده از این گروه مسئولیت ارسال بسته هایی را بر عهده دارد که هاست ها به روتر مجازی می فرستند. این روتر به عنوان Active router شناخته می شود و روتر دیگر به عنوان Standby router انتخاب می شود. هنگامی که روتر Active از کار بیافتد، روتر standby وظایفِ ارسال بسته را بر عهده می گیرد. با وجود آنکه تعداد دلخواهی از روترها پروتکل HSRP را می توانند اجرا نمایند، تنها روتر Active ، بسته هایی را ارسال می کند که به روتر مجازی فرستاده شده اند.
برای به حداقل رساندن ترافیک شبکه، به محض اینکه پروتکل فرآیند انتخاب را کامل کرد، تنها روترهای Active و standby پیام های HSRP را به صورت دوره ای می فرستند. اگر روتر Active از کار بیافتد، روتر standby به عنوان روتر Active فعال خواهد شد. اگر یک روتر standby از کار بیافتد یا به یک روتر Active تبدیل شود، سپس روتر دیگری به عنوان روتر standby انتخاب می شود.
بر روی یک LAN مشخص، چندین گروه standby همزمان می توانند حضور و یا همپوشانی داشته باشند. هر گروه standby یک روتر مجازی را شبیه سازی می کنند. روتری مشخص ممکن است در چندین گروه شرکت داشته باشد. در چنین مواقعی، روتر تایمر و وضعیت هر گروه را به صورت جداگانه نگهداری می کند.
هر گروه standby یک آدرس MAC و یک آدرس IP دارد.
ارتباطات در HSRP
با استفاده از پروتکل HSRP سه نوع از پیام های multicast میان دستگاه ها رد و بدل می شود:
Hello – پیام hello میان دستگاه های Active و Standby ارسال می شود (به صورت پیش فرض هر 3 ثانیه). اگر دستگاه Standby به مدت 10 ثانیه از سمت Active پیامی دریافت نکند، خودش نقش Active را بر عهده خواهد گرفت.
Resign – پیام resign از طرف روترِ active فرستاده می شود، هنگامی که این روتر قرار است آفلاین شود یا به دلایلی از نقش Active صرف نظر کند. این پیام به روتر Standby می گوید که برای نقش Active آماده شود.
Coup – پیام coup هنگامی استفاده می شود که روتر Standby می خواهد به عنوان روتر Active فعال شود (preemption).
وضعیت روترها در HSRP
روترها در پروتکل HSRP در یکی از وضعیت های زیر قرار می گیرند:
Active – حالتی است که ترافیک در حال ارسال است.
Init یا Disabled – حالتی است که روتر آماده نیست یا قادر به شرکت در فرآیند HSRP نیست.
Learn – حالتی است که هنوز آدرس IP مجازی تعیین نشده است و پیام hello از طرف روتر Active دیده نشده است.
Listen – حالتی است که یک روتر پیام های hello را دریافت می کند.
Speak – حالتی است که روتر پیام های hello را می فرستد و دریافت می کند.
Standby – حالتی است که روتر آماده می شود تا وظایف ارسال ترافیکِ مربوط به روتر Active را بر عهده بگیرد.
ویژگی های HSRP
Preemption
ویژگیِ Preemption در HSRP بلافاصله روتری با حداکثر اولویت را به عنوان روتر Active فعال می سازد. اولویت روتر در ابتدا از طریق مقدار priority تعیین می شود که توسط شما تنظیم شده است و سپس به واسطه آدرس IP . هرچه این مقدار بیشتر باشد، اولویت بالاتر است.
وقتی که یک روتر با اولویت بیشتر حق تقدم می یابد، یک پیام coup می فرستد. هنگامی که یک روتر Active با اولویتی کمتر پیامِ coup یا پیامِ hello را از یک روتر با اولویتی بالاتر دریافت کند، به وضعیت speak تغییر می کند و یک پیامِ resign می فرستد.
Preempt Delay
این ویژگی منجر خواهد شد که فرآیند preemption برای مدت زمانی قابل تنظیم به تعویق بیافتد، و در نتیجه روترِ با اولویت بالا اجازه خواهد یافت که پیش از دریافت نقشِ Active، جدول routing خود را پُر نماید.
Interface Tracking
این ویژگی به شما اجازه خواهد داد که اینترفیسی را بر روی روتر، برای نظارت بر فرآیند HSRP تعیین نمایید تا اولویت HSRP را برای گروهی معین تغییر دهد.
اگر line protocol مربوط به اینترفیس مشخص شده down شود، اولویت HSRP مربوط به این روتر کاهش یافته است. در نتیجه به روتر دیگری با اولویت بالاتر اجازه داده می شود تا Active شود. برای اینکه از Interafece Tracking در HSRP استفاده نمایید دستور زیر را به کار برید:
[Standby [group] track interface [priority
Multiple HSRP Group
ویژگی MHSRP به نسخه 10.3 از Cisco IOS اضافه شد. این ویژگی به اشتراک گذاری load و افزونگی در شبکه را در اختیار می گذارد. و اجازه خواهد داد که روترهای افزونه به طور کامل مورد بهره برداری قرار گیرند. در حالی که روتری در نقش Active ترافیکِ یک گروهِ HSRP را ارسال می کند، در همان حال در گروهی دیگر می تواند در وضعیت standby یا listen قرار بگیرد.
آدرس MAC و IP مجازی
آدرس IP مجازی توسط ادمین شبکه کانفیگ می شود. هاست آدرسِ IP مربوط به default gateway خود را برابر با این آدرس IP مجازی خواهد گذاشت و در این حالت روترِ Active به آن پاسخ خواهد داد. آدرس MAC مجازی بر طبق الگوی زیر ایجاد می شود:
##.0000.0C07.AC
بخشِ 0000.0C مربوط به شناسه OUI شرکت Cisco است. بخشِ 07.AC ،شناسه ی اعمال شده برای پروتکلِ HSRP است و ## شناسه ی گروه HSRP است که توسط ادمین شبکه کانفیگ می شود.
**************
برای پروتکل HSRP دو نسخه ارائه شده است که با توجه به نوع سوئیچ لایه 3 یا روتری که در اختیار دارید، می توانید یکی از این دو نسخه را استفاده نمایید. در زیر جدول تفاوت این دو نسخه آورده شده است.
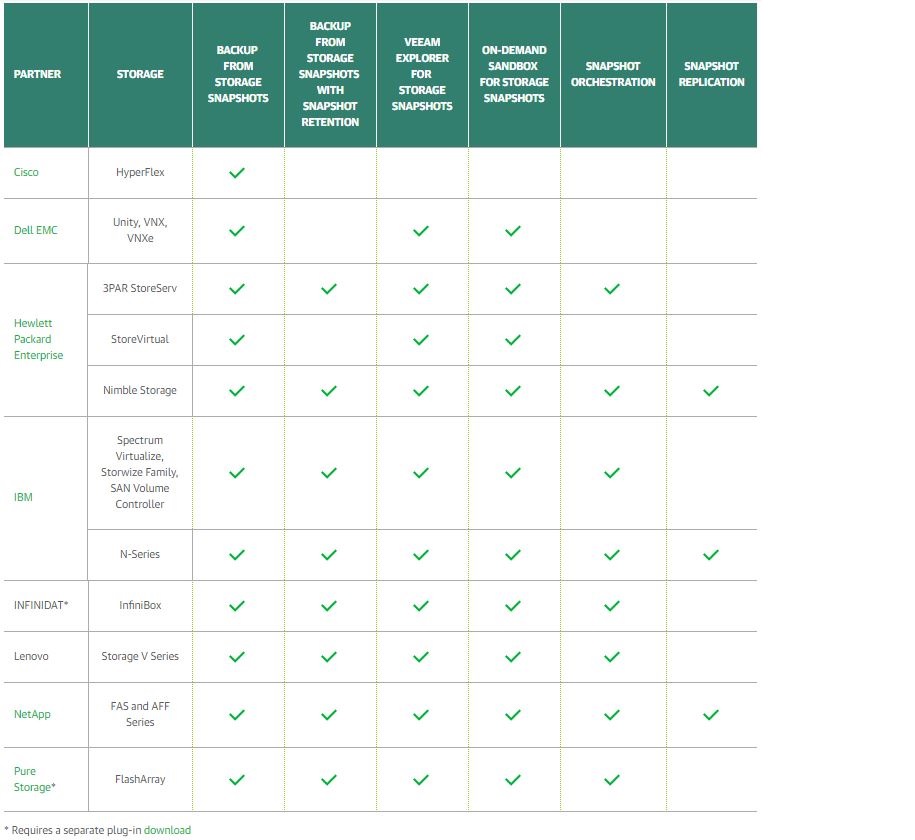
نرم افزار EMC FAST به محصولات EMC Unity اجازه می دهد تا از درایوهای Flash با کارایی بالا استفاده کنند. نرم افزار FAST شامل Fully Automated Storage Tiering برای (Virtual Pools (FAST VP و FAST Cache است. این دو ویژگی در کنار هم کار می کنند تا از فضای ذخیره سازی درون سیستم به صورت مؤثر استفاده شود. هر یک از این ویژگی های نرم افزاری تضمین می کند که فعال ترین داده ها از طریق Flash پشتیبانی می شوند.
هنگامی که ویژگیِ FAST VP فعال شود، این ویژگی آمارهایِ Performance روی هر [1] slice در یک Pool را اندازه گیری و ثبت می کند. در ادامه، FAST VP این داده ها را تجزیه و تحلیل می کند و تصمیم می گیرد تا داده ها را به tier های مختلف انتقال دهد (با توجه به میزان استفاده از داده) تا Performance یک Pool را بیشینه کند و از فضای درون Pool به طور موثری بهرمند شود. Slice هایی که بیشترین استفاده را دارند به طور خودکار به Tier های بالاتر در یک Pool منتقل می شوند، در حالی که Slice هایی که استفاده کمتری دارند به Tier های پایین تر منتقل می شوند. داده هایی که از قبل روی Flash در یک Pool قرار گرفته اند از فضای Fast Cache استفاده نمی کنند که این قابلیت اجازه می دهد تا داده های مستقرِ بیشتری بر روی هارد دیسک ها از مزایای فلش Fast VP بهره مند شوند.
این مقاله برای مشتریان ، شرکا و کارکنان فاراد در نظر گرفته شده است که از ویژگی های FAST VP و FAST CACHE در خانواده EMC Unity از سیستم های استوریج استفاده می کنند. استفاده از این ویژگی با EMC Unity و نرم افزار مدیریت EMC همراه می شود.
بطور معمول وقتی داده ای ایجاد می شود ابتدا در بالاترین tier قرار می گیرد و با توجه به میزان نوشتن و خواندن از آن داده ، استوریج نسبت به انتقال داده در tier مناسب اقدام می کند. از این روند نیز به عنوان چرخه حیات داده ها یاد شده است. EMC Unity سیستم ذخیره سازی کاملا اتوماتیک (Fully Automated Storage Tiering) را برای Pool های مجازی (FAST VP) ارائه می دهد که بر الگوهای دسترسی به داده (خواندن و نوشتن داده ها) درونِ Pool های سیستم نظارت می کند و به صورت پویا خود را تطبیق می دهد از طریقِ در نظر گرفتن و انتخاب مناسب ترین tier که میزان کارایی (Performance) مورد نیاز را ارائه می دهد. FAST VP درایوها را به سه دسته تقسیم می کند. این سطوح عبارتند از:
Extreme Performance Tier – شامل درایوهای Flash است
Performance Tier – شامل درایوهای (Serial Attached SCSI (SAS است
Capacity Tier – شامل درایوهای (Near-Line SAS (NL-SAS
FAST VP به کاهش هزینه (Total Cost of Ownership-TCO) با حفظ Performance و با استفاده از ساختار Pool می پردازد. به جای ایجاد یک Pool با یک نوع درایو، مخلوط کردن Flash، SAS و NL SAS درایوها می توانند از طریق کاهش تعداد درایوها و استفاده از درایوهایی با ظرفیت بیشتر به کاهش هزینه های یک پیکربندی کمک کنند. داده هایی که دارای سطح عملکرد بالایی هستند در درایو های Flash قرار می گیرند، در حالی که داده هایی که فعالیت کمتری دارند در SAS یا NL-SAS قرار می گیرند.
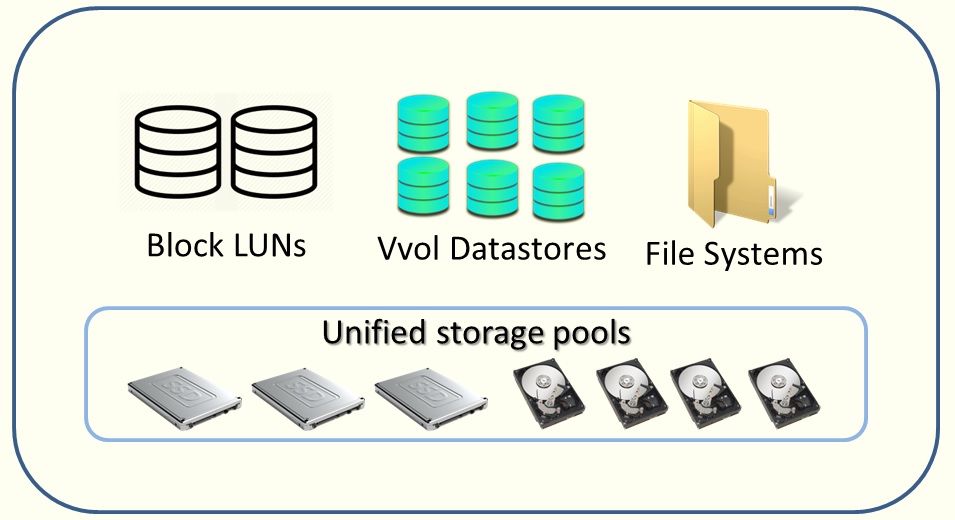
EMC Unity یک رویکرد واحد برای ایجاد منابع ذخیره سازی در سیستم دارد. Block LUNs، File Systems و VMware Datastores همه می توانند در یک Pool واحد وجود داشته باشند و همگی می توانند از ویژگی های FAST VP بهره مند شوند. در تنظیمات سیستم با حداقل مقدار Fast VP ، Flash به راحتی از درایوهای Flash برای داده های فعال با عملکرد بالا , صرف نظر از نوع منبع استفاده می کند. میزان عملکرد برای تمام داده ها در یک Pool در مقایسه با یکدیگر بررسی می شوند و بیشترین اطلاعات مورد استفاده ، در درایو های با کارایی بالا (درایو های Flash) قرار می گیرند. سیاست های Tiering در مقاله های بعد توضیح داده خواهد است.
لایسنس FAST VP :
در Fast VP ، Unity روی سیستم های Unity Hybrid و UnityVSA پشتیبانی می شود. برای سیستم های Unity Hybrid ، FAST VP از طریق بسته ی نرم افزاری EMC Unity Essentials که شامل تمامی سیستم های Unity Hybrid می باشد فعال می شود. FAST VP برای UnityVSA با License نرم افزار پایه فعال می شود. هنگامی که این License ها نصب می شوند، ویژگی های مرتبط FAST VP در دسترس هستند:
توانایی ایجاد Pool با انواع چندین درایو
توانایی تنظیم سیاست های Tiering روی Block LUN ها، File Systems و VMware Datastores.
توانایی دسترسی به تب FAST VP در Pool properties window یا storage resource properties window
[1] Slice : سیستم LUN های شما را به تکه های کوچک (Slice) تقسیم می کند و به این Slice ها یک درجه حرارتی ( با توجه به کارایی ) اختصاص داده می شود. مثلا اگر Slice هایی که به طور مداوم در دسترس باشد را Hot Slice و Slice هایی که به ندرت از آن ها استفاده می شود را Cold Slice گویند و این Slice ها دارای حجم 256MB می باشند.
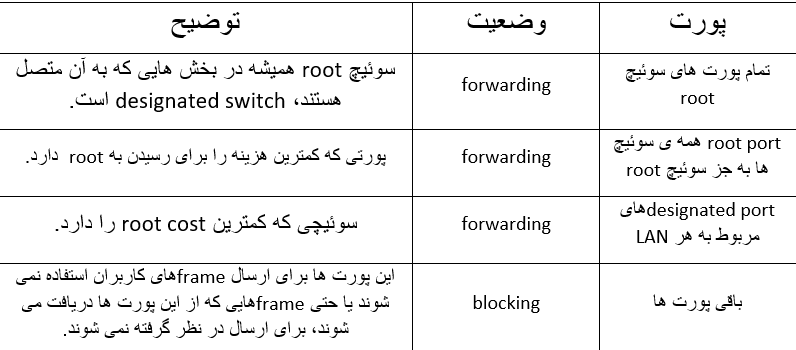
*سوئیچ سیسکو دستگاهی است که در شبکه های مخابراتی مورد استفاده قرار می گیرد. کاری که سوئیچ به انجام می رساند این است که داده های ورودی را از هر یک از پورت های ورودی چندگانه، به پورت خروجی خاص هدایت می کند. به این ترتیب اطلاعات در مقصد مورد نظر دریافت می شوند. در شبکه تلفن سنتی (Circuit-switched)، یک یا چند سوئیچ به کار گرفته می شوند. این سوئیچ ها یک مدار اختصاصی را جهت برقراری اتصال موقت به وجود می آورند که منجر به برقراری ارتباط میان دو یا چند نفر می شود. در شبکه محلی اترنت (LAN)، یک سوئیچ با توجه به فریم ورودی، آدرس فیزیکی ( MAC آدرس ) مقصد را تعیین می کند و فریم حاوی دیتا را به طور مستقیم به سمت مقصد هدایت می کند. در شبکه گسترده مانند اینترنت، سوئیچ آدرس مقصد را با توجه به آدرس IP که در هر بسته دیتا به طور اختصاصی تعریف شده است؛ مشخص می کند.
سوئیچ لایه 2 و سوئیچ لایه 3 :
سوئیچ های لایه 2 : در مدل ارتباطات OSI یک سوئیچ در Layer 2 یا لایه Data-link عمل می کند و توابع سوئیچینگ را انجام می دهد. به عبارت دیگر این مدل از سوئیچ ها “مک آدرس ” را با توجه به Packet or Data Unit تعیین می کنند. سوئیچ های لایه 2 ساده ترین نوع از سوئیچ ها می باشند. از جمله این سوئیچ ها می توان به سوئیچ 2960 اشاره کرد. سوئیچ های لایه 3 : در شبکه های گسترده ای مانند اینترنت، تعیین آدرس مقصد نیازمند جستجو در جدول مسیریابی می باشد. با وجود اینکه این عمل توسط روتر انجام می شود اما برخی از سوئیچ های امروزه قابلیت انجام عمل Routing را نیز پشتیبانی می کنند. این مدل از سوئیچ ها که قادر به انجام توابع مسیریابی هستند در لایه 3 یا لایه شبکه مدل OSI قرار می گیرند. سوئیچ های لایه 3 را می توان سوئیچ های IP نامید. به عنوان مثالسوئیچ سیسکو 6500 Catalyst، سوئیچ سیسکو Catalyst 6800و سوئیچ سیسکو Nexus از این مدل سوئیچ ها می باشند.
متخصصین ما آمادهاند تا در صورت لزوم با حضور در سازمان ضمن تحلیل دقیق نیازهایتان و با در نظر گرفتن محدودیتهای مالی ، بهینهترین راهکار را در خصوص انتخاب سوئیچ سیسکو به شما معرفی نمایند . علاوه بر این می توانید از کارشناسان ما در خصوص قیمت سوئیچ سیسکودر مدل های مختلف و نیز انواع سوئیچ های سیسکو ، مشاوره لازم را دریافت کنید .
در مقاله قبل مقدمه ای از Hyper-V را در اختیارتان قرار دادیم. در این مقاله قصد داریم درباره ی راه اندازی Hyper-V در ویندوز سرور 2016 صحبت کنیم که شامل نصب، مدیریت، تنظیمات ذخیره سازی، پیکربندی شبکه و مدیریت از راه دور است. امتیاز راه اندازی و نصب Hyper-V در ویندوز سرور 2016 این است که میزبان ، ماشین های مجازی می باشند. بنابراین، بیایید بررسی کنیم که چگونه ماشین ها را در Hyper-V از ویندوز سرور 2016 ایجاد و پیکربندی کنیم.
ایجاد یک ماشین جدید :
ابتدا، شما باید از Hyper-V Manager برای اتصال به میزبان Hyper-V استفاده کنید. Hyper-V Manager شامل ابزار Remote Server Administration Tools ( RSAT ؛ دانلود جداگانه ) برای سیستم عامل های کلاینت مانند ویندوز 10 ، یا در بخش Server Manager شامل Install Features از ویندوز سرور 2016 می باشد.
ابتدا به Hyper-V Manager بروید.
برای شروع، بر روی میزبان Hyper-V خود کلیک راست کرده و New> VM را انتخاب کنید.
در این قسمت ، Wizard مربوط به New Virtual Machine راه اندازی می شود.
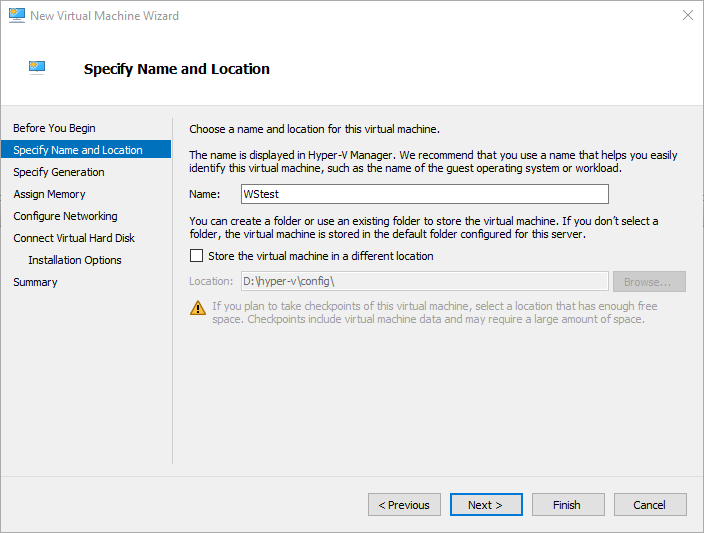
پیکربندی را با انتخاب یک نام برای ماشین شروع کنید.
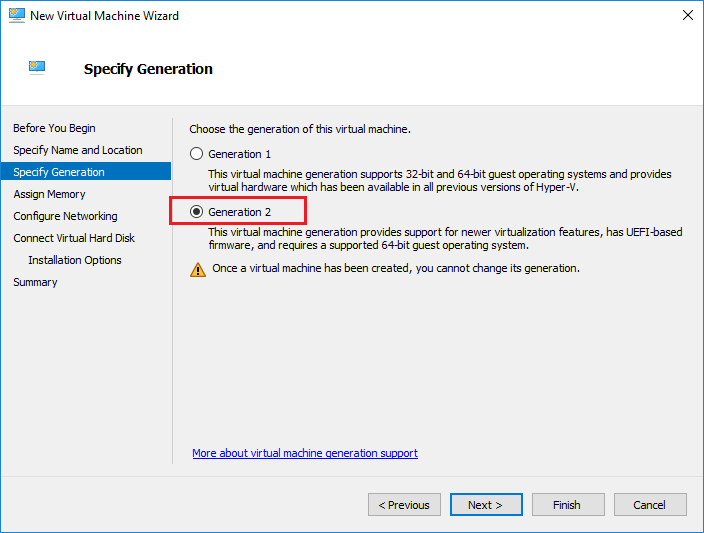
Generation های مختلف ماشین های مجازی
در مرحله بعد از شما خواسته می شود تا نوع Generation ماشین مجازی خود را انتخاب کنید. در اینجا شما دو انتخاب دارید:
Generation 1 و Generation 2 . اما این دو چه تفاوت هایی دارند؟
برای شروع، ماشین های مجازی Generation 2 تنها با Hyper-V 2012 R2 و بالاتر سازگار است. همچنین ویندوز سرور 2012 / ویندوز 8 64 بیتی و بالاتر با Generation 2 پشتیبانی می شود. بنابراین هیچ نسخه 32 بیتی از این سیستم عامل ها کار نخواهند کرد. در حقیقت، اگر یک ماشین مجازی از نوع Generation 2 ایجاد کنید و سعی کنید بوت از یک ISO سیستم عامل 32 بیتی ایجاد کنید ، به سادگی به شما یک ارور می دهد که هیچ مدیایی برای boot نمی تواند پیدا کند. همچنین مایکروسافت در حال پشتیبانی از ماشین های Generation 2 با لینوکس است. در حال حاضر چون تمام سیستم عامل ها توسط Generation 2 پشتیبانی نمی شوند مطمئن شوید که متناسب با نیاز خود Generation ماشین ها را انتخاب می کنید. ملاحظه دیگری نیز وجود دارد: برای کسانی که در فکر انتقال یک ماشین مجازی Hyper-V از پیش ساخته شده به Azure هستند، Gneration 2 آن را پشتیبانی نمی کند.
برای سازگاری بیشتر از جمله انتقال به Azure، ماشین ها باید از نوع Generation 1 انتخاب شوند. اگر هیچ کدام از محدودیت های ذکر شده درست نیست و شما می خواهید از ویژگی هایی مانند بوت امن UEFI استفاده کنید، Generation 2 انتخاب برتر خواهد بود.
هنگامی که یک ماشین ایجاد می شود، شما نمی توانید Generation را تغییر دهید. اطمینان حاصل کنید که قبل از شروع، Generation مناسب را انتخاب کرده اید.
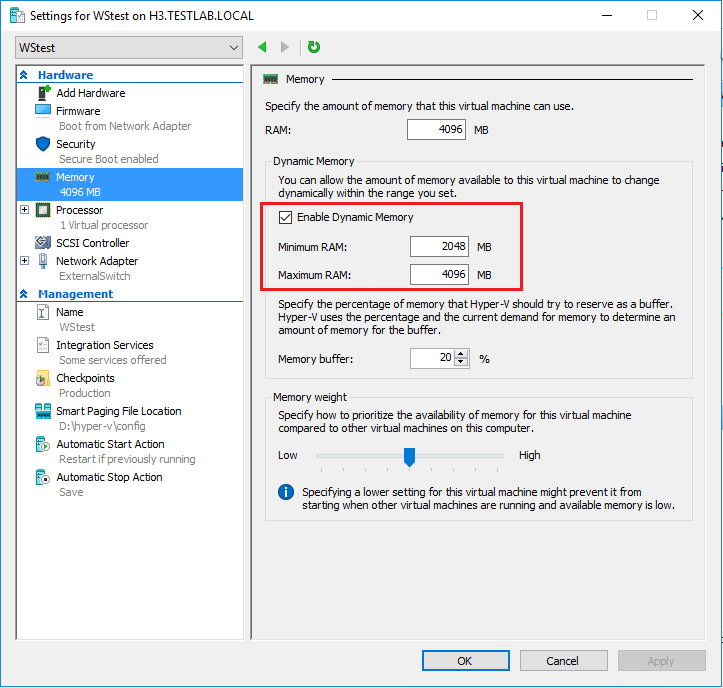
مدیریت حافظه در Hyper –V :
بخش بعدی پیکربندی جایی است که می توانیم حافظه را اختصاص دهیم (Assign Memory). مدیریت حافظه در Hyper-V گزینه ای با نام Memory Dynamic دارد ؛ شما می توانید یک Checkbox را مشاهده کنید که می تواند برای فعال کردن ویژگی Dynamic Memory در این مرحله انتخاب شود. اگر شما این گزینه را فعال کنید، Hyper-V با سیستم عامل ماشین مهمان در مدیریت حافظه سیستم عامل مهمان همکاری می کند.
با استفاده از ویژگی ” hot add “، Hyper-V حافظه سیستم عامل مهمان را گسترش می دهد زیرا request های مهمان در حافظه افزایش می یابد. Dynamic Memory کمک می کند تا به طور پویا و به طور خودکار RAM را بین ماشین های در حال اجرا تقسیم کند، مجددا حافظه را بر اساس تغییرات خواسته های منابع خود تقسیم می کند. این کمک می کند تا به طور موثرتری از منابع حافظه در هاست Hyper-V و نیز تراکم بیشتر ماشین استفاده شود.
هنگامی که شما انتخاب می کنید از Dynamic Memory برای ماشین مجازی خود استفاده کنید ، می توانید حداقل و حداکثر مقدار RAM را به صورت Dynamic به ماشین مجازی اختصاص داده شده، تنظیم کنید.
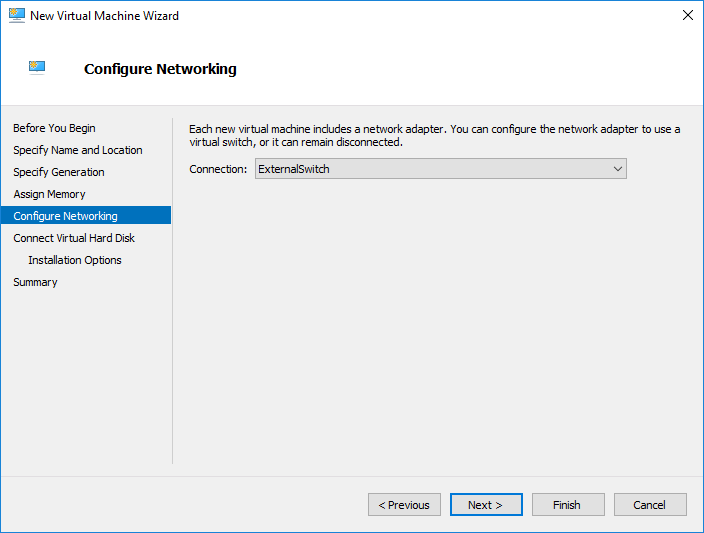
پیکربندی شبکه
گام بعدی در پیکربندی ماشین ما، پیکربندی شبکه است. برای اینکه یک ماشین مجازی خاص اتصال به شبکه داشته باشد، باید یک سوئیچ مجازی که متصل است، پیوست کنید. شما همچنین می توانید ماشین را در وضعیت disconnect قرار دهید؛ اتصال به یک شبکه در تکمیل پیکربندی ماشین مجازی مورد نیاز نیست. در این مثال ما ماشین را به ExternalSwitch متصل می کنیم که یک سوئیچ مجازی است که با شبکه LAN متصل است.
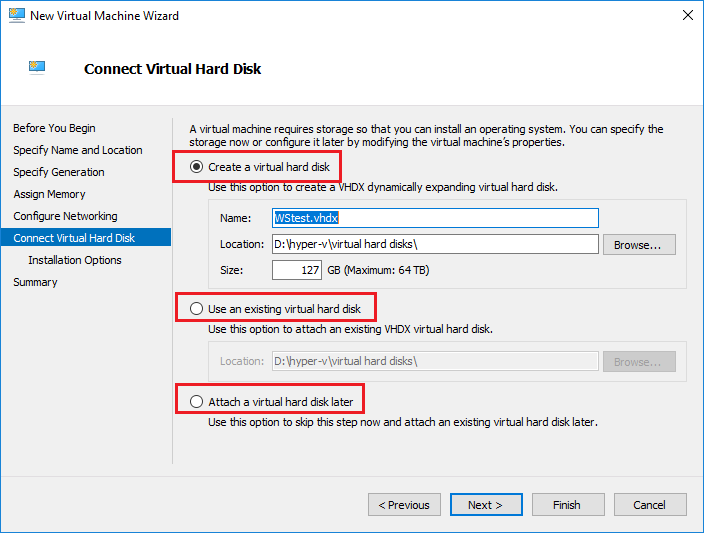
پیکربندی هارد دیسک
گام بعدی پیکربندی هارد دیسک است که به ماشین مجازی شما اختصاص داده شده است. سه گزینه وجود دارد که شما می توانید انتخاب کنید :
اگر شما گزینه “Create a virtual hard disk” را انتخاب کنید ، در واقع شما در حال ایجاد یک VHDX دیسک روی Hyper-V هاست می باشید. شما می توانید اندازه دیسک را تنظیم کنید. این مقدار در Wizard به صورت پیش فرض 127 گیگابایت است که به آسانی قابل تغییر است.
گزینه Use an existing virtual hard disk ، شما می توانید پیکربندی جدید ماشین خود را به یک دیسک مجازی موجود اضافه کنید. شاید شما بیش از یک فایل VHDX کپی کنید که می خواهید با پیکربندی جدید ماشین استفاده کنید. با این گزینه می توانید در Wizard به فایل VHDX مراجعه کنید.
با گزینه سوم – Attach a virtual hard disk later – شما می توانید انتخاب کنید که یک هارد دیسک در wizard را ایجاد کنید و یک دیسک را بعدا اختصاص دهید.
یک هشدار مهم برای گزینه Create a virtual hard disk وجود دارد: در نوع دیسک ایجاد شده هیچ انتخابی ندارید. به صورت پیش فرض Hyper-V دیسک هایی که به طور Dynamic گسترش می یابند را ایجاد می کند، دیسک هایی که thin-provisioned هستند. فضا فقط به مقداری که مورد نیاز است استفاده می شود. با این وجود، در این روش معایبی وجود دارد. درحالیکه Driver استوریج Hyper-V به طور کلی از منابع کارآمد برای بهترین عملکرد استفاده می کند ، بسیاری دیگر ممکن است ترجیح دهند دیسک های thick یا Fixed size در Hyper-V را مورد استفاده قرار دهند. برای انجام این کار، باید گزینه سوم را انتخاب کنید و پس از ایجاد ماشین، یک هارد دیسک Thick مجازی ضمیمه کنید.
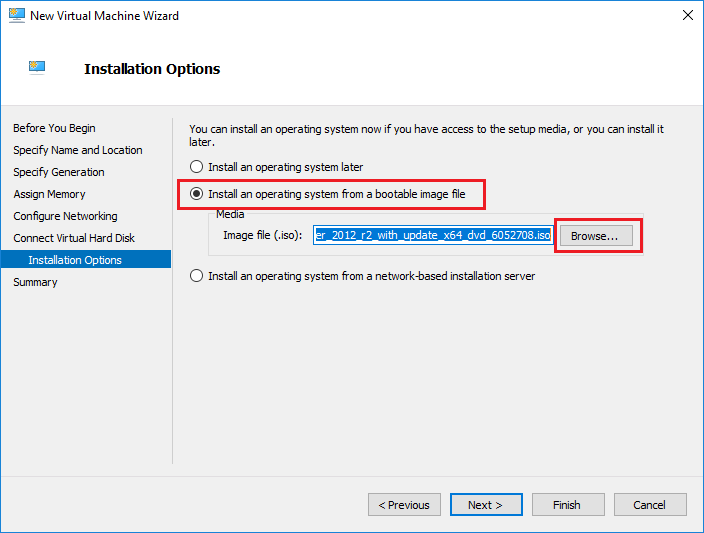
گزینه های نصب و راه اندازی
مرحله بعد در Wizard مربوط به بخش installation option می باشد. به این معنی است که شما چگونه می خواهید سیستم عامل مهمان (OS) خود را در ماشین مجازی جدید نصب کنید.
رایج ترین راه انتخاب گزینه Install an operating system from a bootable image file می باشد. شما باید یک فایل ISO از سیستم عامل داشته باشید که در جایی روی سرورتان ذخیره شده باشد. به سادگی با استفاده از دکمه Browse، wizard را به مکان هدایت کنید.
پیشنهادات دیگر برای انتخاب شما Install an operating system later یا Install an operating system from a network-based installation server می باشد.
شما اکنون به خلاصه ای از گزینه های پیکربندی خود دسترسی پیدا کرده اید. هنگامی که روی دکمه Finish کلیک کنید، ماشین شما با توجه به گزینه هایی که مشخص کرده اید ایجاد می شود.
اکنون که پیکربندی و نصب کامل است، می توانید ماشین خود را روشن کنید. به سادگی روی ماشین کلیک راست کرده و ماشین را Start کنید.
شما می توانید با کلیک راست روی ماشین ایجاد شده و انتخاب گزینه Connect به کنسول وصل شوید.
پس از اتصال به کنسول، اکنون باید بتوانیم ماشین خود را بوت کنیم و سیستم عامل را به طور معمول نصب کنیم.
اندیشه ها
ما تمامی گزینه های پیکربندی در دسترس شما را هنگام ایجاد ماشین های جدید در مدیریت Hyper-V پوشش داده ایم. این مقاله دومین سری از چگونگی استفاده از Hyper-V برای مجازی سازیاست. ما با اصول اولیه شروع کردیم و در حال پیشرفت به سوی موضوعات پیشرفته تر هستیم.
با توجه به افزایش روز افزون حجم داده ها و اطلاعات ، طبیعی است که سازمان ها نیازمند سروری باشند که بتواند در مواجه با هر حجم داده ای ، مقیاس پذیر باشد . سرور HP ProLiant BL660c G9 محصولی از کمپانی HPE می باشد که در رده سرور های Blade روانه بازار شد . این محصول با پشتیبانی از 4 پردازنده جهت استفاده در مجازی سازی ، پایگاه داده و داده هایی که نیازمند پردازش بالایی هستند ، بسیار مناسب است.
قابلیت انعطاف پذیری که سرور BL660c G9 ارائه می دهد ، امکانات ذخیره سازی بیشتر و عملیات I/O سریعتری را به ارمغان می آورد. همچنین توان پردازشی قدرتمندتر در این محصول ، جهت برآورده کردن نیاز انواع بار کاری با TCO کمتر ، عرضه گردیده است .
تمام قابلیت های فوق الذکر این محصول ، توسط HPE OneView مدیریت می شوند که از یک پلت فرم مدیریتی یکپارچه جهت تسریع سرویس ها، برخوردار است .این دستگاه از پردازنده Intel Xeon E5-4600 v3/v4 پشتیبانی می کند که همراه با فن آوری 4 سوکت blade بوده و تراکم بهینه را بدون تغییر عملکرد ارائه می دهد . از جمله دیگر ویژگی های سرور BL660c G9 پشتیبانی از HPE DDR4 SmartMemory است که در مقایسه با نسل قبلی 331% افزایش عملکرد دارد .
از دیگر قابلیت های سرور HP BL660c G9 می توان به موارد زیر اشاره کرد :
**• پشتیبانی از 2 عدد NVMe SSDs
**• پشتیبانی از امکانات Tiered Storage Controller
**• ارائه دادن 12Gb/s SAS
**• فراهم آوردن 20Gb FlexibleLOMs ، M.2 و USB 3.0
1 این سرور از کمپانی HPE با قابلیت پشتیبانی از DDR4 ، عملکرد را 14 تا 33 درصد بهبود بخشیده است .
این سرور یکی از سرور های Rachmount شرکت اچ پی می باشد . کمپانی هیولت پاکارد این محصول را به گونه ای طراحی کرده است که بهترین عملکرد را در زمان اوج مصرف داشته باشد . DL380 G9 برای استفاده در هر محیطی ایده آل است و درصورت قرار گرفتن درون رک ، دو یونیت از فضای آن را اشغال می کند.
زیروکلاینت (به انگلیسی: Zero Client) به سیستمی اطلاق میشود که برای تحقق وظایف محاسباتی خود به سرور (Server) وابسته است. این مفهوم در برابر فت کلاینت (به انگلیسی: Fat Client) و تین کلاینت (Thin Client) قرار میگیرد که طوری طراحی شده تا تمام نیازهای خود را خودش برآورده کند. وظایفی که توسط خدمات دهنده فراهم میشود مختلف است، از فراهم آوردن ساختار پایدار داده (برای مثال برای گرههای بدون دیسک) گرفته تا پردازش اطلاعات.
زیرو کلاینت مانند جزئی از یک زیرساخت کامپیوتری گسترده است، که در این زیرساخت کلاینتهای زیادی قدرت محاسباتی خود را با یک سرور به اشتراک گذاشتهاند.
در اصل زیرو کلاینتها فاقد رم (Ram) و هارد (HDD) به شکل موجود در PCها و TCها هستند و به همین دلیل دارای ظاهری کوچک و سبک بوده و قیمت بسیار نازل تری نسبت به آنها دارد. این سیستمها صرفاً در شبکههایی قابل استفاده خواهند بود که دارای سرور بوده (Server Base) و از طریق سرور برای آنها محدوده کابری تعریف گردد.
یرو کلاینت، تین کلاینت ، مینی پیسی و اکسس ترمینال چه هستند و چه تفاوت هایی با یکدیگر دارند؟
مینی پی سی: یعنی یک کامپیوتر شخصی کوچک و ضعیف که میتواند به تنهایی کار کند و دارای رم و سی پی یو و فضای ذخیره سازی است فقط کوچک شده و ضعیف شده ی یک رایانه ی معمولی است.
تین کلاینت: همان مینی پی سی است ( اغلب، حتی کارشناسان امر و یا تولید کننده ها نیز این دستگاهها را با زیرو کلاینت اشتباه میگیرند)
زیرو کلاینت: یک درگاه (درب و پنجره) است برای متصل شدن به یک رایانه ی مرکزی ، در واقع تمامی برنامه ها و سیستم عامل ها روی رایانه ی مرکزی نصب میشوند و کاربران از طریق این درگاهها به آن رایانه ی مرکزی وصل شده و از آنها استفاده میکنند و منابع سخت افزاری مورد نیاز خود مانند RAM و CPU و فضای ذخیره سازی را از رایانه ی مرکزی میگیرند.
- دقت داشته باشید که منظور از کلمه ی زیرو اینست که این دستگاهها قابلیت ارائه هیچگونه سرویس مناسب برای کاربر را در غیاب یک سرویس دهنده ی اصلی ندارند- و یا به عبارت دیگر بدون وجود سرور قادر نیستند به نیازهای کاربر پاسخ گویند.
تفاوت زیرو کلاینتها با یکدیگر در چیست؟
زیرو کلاینتها بسته به نوع ارتباطی که با کامپیوتر مرکزی برقرار میکنند و نحوه ی عملکردشان در چند خانواده ی متفاوت قرار میگیرند : انواع زیرو کلاینت
زیرو کلاینت های RDP : این زیرو کلاینت ها برای ارتباطشان با رایانه ی مرکزی از استاندارد
مایکروسافتی اتصال از راه ادور به نام RDP استفاده میکنند،
و میتوانند همگی به یک سیستم عامل یا چند سیستم عامل متصل شوند.
زیرو کلاینت های VDI : این زیرو کلاینت ها حتما به سرور و بستر سرور مجازی نیاز دارند
و با استفاده از پروتکل های PCoIP , ICA , HDX به سرور مجازی متصل میشوند
( بستر مجازی سیتریکس و یا وی ام ور) و از این طریق میتوانند میز کار مجازی کاربر
( Virtual Desktop) و یا برنامه های مخصوص هر کاربر را برای وی ارائه دهند.
زیرو کلاینت های DDP : این استاندارد که جدید ترین استاندارد در حوزه ی مجازی سازی
دسکتاپ میباشد، متعلق به کمپانی وی کلود پوینت است
و به اینصورت است که میتوان به یک کاربر یا یک مجموعه از کاربران یک سیستم عامل
اختصاص داد،
با حداقل منابع سخت افزاری مورد نیاز (میتوان یک رایانه ی رومیزی را در اختیار بیش از ۳۰ کاربر
قرار داد) و همینطور کمترین میزان مصرفف پنای باند شبکه.
( تفاوتهای بسیاری با استاندارد RDP دارد که به تفصیل در ادامه شرح داده خواهد شد)
زیرو کلاینت های رسیوری : این خانواده از زیرو کلاینت ها که خانواده ی پر جمعیتی هم هستند از
نظر تنوع برند و امکانات به این صورت عمل میکنند
که دستگاه زیرو کلاینت صرفا یکسری امکانات خاص را در اختیار کاربر قرار میدهد
بعنوان مثال: فقط یک مرورگر اینترنت در ختیار کاربر قرار میدهد –
یا : بر روی رایانه ی مرکزی یک نرم افزاری نصب میشود که آن نرم افزار صرفا تعدادیی برنامه
را در اختیار هر کاربر قرار میدهد.
هماگونه که رایانه های با یکدیگر از نظر قدرت و ظرفیت و اندازه و شکل ظاهری متفاوت هستند، همین تفاوت ها در تین کلاینت ها نیز میباشد
– در واقع تین کلاینت یا مینی پی سی هم همان رایانه ی معمولی هستند که فقط کوچکتر و ضعیف تر شده اند.
و همگی در خانواده ی رایانه های شخصی قرار میگیرند و مقایسه بین آنها همانند مقایسه بین رایانه های رومیزی میباشد یعنی مواردی از قبیل نوع و توان پردازنده، میزان و سرعت رم و مواردی از این دست در آنها مقایسه میشود و کاربری آنها یکسان است.
برای استفاده از راهکار VDI بهتر است از زیرو کلاینت های مبتنی بر ARM استفاده شود یا Tradici ؟
تفاوت پردازنده های ARM و Teradici
– در ابتدا به اختصار به معرفی دو کمپانی مذکور میپردازیم:
کپانی ترادیسی در سال ۲۰۰۴ در زمینه فشرده سازی صوت و تصویر و انتقال آن فعالیت خود را شروع کرده و در سال ۲۰۰۸ اولین چیپست خود را مبتنی بر پروتکل PCoIP به بازار ارائه نمود
که برای اولین بار توسط کمپانی های HP, Dell-Wyseدر تین کلاینتها و زیرو کلاینتها به کار برده شد.
کمپانی آرم از سال ۱۹۸۰ تا کنون مشغول به گسترش پردازنده های مبتنی بر تکنولوژی آرم است
که به دلیل مصرف انرژی پایین بیشتر در دستگاههای قابل حمل استفاده میشود
که با رشد روز افزون دستگاههای موبایل و نیاز به پردازنده های گرافیکی قویتر در آنها، این کمپانی از سال ۲۰۱۴ اقدام به مجتمع سازی پردازنده های قدرتمند گرافیکی در سی پی یو های خود کرده است،
که کمپانی هایی همچون APPLE در تراشههای اختصاصی خود، SAMSUNG در پردازندههای اگزینوس، NVIDIA در پردازشگرهای تگرا و Qualcomm در پردازندههای اسنپدراگون خود از معماری قدرتمند آرم استفاده میکنند.
مقایسه پردازنده های ARM و Teradici
با پیشرفتی که در عرصه ی مجازی سازی در دهه ی اخیر شاهد آن بودیم
و همینطور پیشرفت دستگاههای موبایل، معماری آرم که به جرات میتوان گفت از نظر تعداد فروش، رتبه ی اول در بین تولید کننده های پردازنده ها را به خود اختصاص داده است،
(بیش از ۹۷ درصد از تلفن های هوشمند، بیش از ۹۰ درصد از هارد دیسک ها، بیش از ۶۰ درصد از تلوزیون ها و ستاپ باکس ها و …)
بر روی این موارد مصرف (مجازی سازی و سرور) متمرکز شده است
به طوریکه تا قبل از سال ۲۰۱۴ از نظر کیفیت صوت و تصویر ارسالی کمپانی ترادیسی پیشرو عرصه مجازی سازی دسکتاپ بود
اما پس از آن کمپانی آرم با قرار دادن قاابلیت نئون بر روی پردازنده های خود در کنار پردازش ۳۲ بیتی و استفاده از پردازنده های قدرتمند گراافیکی مالی ( Mali) بصورت مجتمع در پردازنده های خود موفق شد
گوی سبقت را در پردازش و فشرده سازی تصویر، از کمپانی ترادیسی برباید
و عملکرد بسیار خوبی حتی در تصاویر سه بعدی و همچنین صدای با کیفیت از خود نشان دهد،
البته ناگفته نماند که انتظاری غیر از هم این نبود، یعنی با توجه به سایز و قدرت کمپانی آرم چنانچه بازار هدف مناسبی پیدا کند
سعی در تصاحب آن بازار خواهد کرد
که با پیشینه ای که از این کمپانی وجود دارد، سعی آن منجر به نتیجه خواهد شد
، البته لازم بذکر است که در مصرف پهنای باند و فشرده سازی صوت و تصویر همچنان کمپانی ترادیسی با اندک فاصله ای پیشرو است،
یعنی در خصوص فشرده سازی تصویر چند درصدی بهتر عمل میکند، اما نه آنقدر ملموس است و نه آنقدر مهم که از کیفیت بالاتر تصویر آرم بگذریم
و همچنین قیمت بسیار پایین تر پردازنده های آرم که معلول بازار بسیار گسترده آنهاست نیز غیر قابل اجتناب است.
به طوریکه کمپانی مطرح HP در مدل پایین تر خود یعنی T310 از پردازنده Teradici
و در مدلهای بالاتر خود یعنی T410 از پردازنده های ARM استفاده کرده است
تا بتواند به لحاظ گرافیکی تجربه ای بهتر در اختیار مشتریان خود قرار دهد.
طبق گفته ی کمپانی VMware پردازنده های خانواده ARM (دارای ویژگی NEON) و Teradici هر دو میتوانند با بالاترین کیفیت در بستر هورایزن (Horizon) استفاده شوند.
در علم کامپیوتر، مجازیسازی[۱] به ساخت نمونهٔ مجازی (غیر واقعی) از چیزهایی مثل پلتفرم سختافزاری، سیستم عامل، وسایل ذخیرهسازی یا منابع شبکه، گفته میشود.
مجازیسازی از یک نوع تفکر عمیق و اجرا کردن هر آنچه که در فکر و ذهن میگذرد و نهایتاً بدون وجود خارجی پیادهسازی میگردد. در علم کامپیوتر استفاده از تکنولوژی مجازیسازی باعث رشد و پیشرفت بسیار شده است. پیادهسازی دستگاههای سختافزاری به صورت مجازی اما با همان عملکرد مزایای بسیاری را برای ما به به رهاورد کشیده است.
اصولاً نرمفزارها مجازی هستند چون ذات آنها فیزیکی نیست. از اینرو میتوان گفت مجازیسازی در اکثر اوقات شکل نرمافزاری دارد؛ که البته بر روی یک سختافزار خاص اجرا خواهد شد. طراحی و شبیهسازی انواع سوییچها، روترها، سرورها و ... از این دستهاند. شرکتهایی نیز در زمینه تولید سیستمهای مجازی مشغول به کارند نظیر شرکت مایکروسافت با سیستم Hyper-V یا سیستمهای مبتنی بر هسته لینوکس از جمله ESX.
مزایای مجازیسازی
بطور کلی مزایای مجازیسازی شامل موارد ذیل است:
کاهش هزینه خرید تجهیزات سختافزاری زیاد
متمرکز سازی
کاهش هزینههای جاری نظیر برق، نگهداری، تعمیرات
کاهش گرمای تولیدی توسط دستگاهها
عدم نیاز به فضای زیاد به نسبت حالت سنتی
استفاده از بیشترین ظرفیت تجهیزات سختافزاری
جابجایی راحت
پشتیبانگیری راحت از اطلاعات
تسریع امور به خاطر وجود بالقوه دستگاهها و عدم نیاز به صرف زمان برای خرید، نصب و آمادهسازی
امکان تنظیم و نصب سرورها و تجهیزات مجازی با استفاده از الگو و کپی برداری
امروزه بیشتر سازمان ها از محیط هایی استفاده می کنند که در آنها کامپیوتر های فیزیکی و pc ها مستقر هستند. در این محیط ها که به احتمال زیاد همه ی ما با آن آشنا هستیم، وجود pc هایی که هر کدام به طور مستقل قطعات تشکیل دهنده ی خود را دارند (مادربرد، رم، پردازنده، پاور و...) و آسیب هایی که این قطعات با آنها درگیر هستند منجر به مصرف انرژی، هزینه ی نگهداری و استهلاک بالا می شوند در حالی که فضای مدیریت مناسبی را هم ارائه نمی دهند. از طرفی در سمت کاربران تجهیزاتی وجود دارد که هر کدام از آن ها فضای فیزیکی زیادی را اشغال می کنند. اما چه راهکاری برای غلبه بر این معضلات در محیط کاری شما وجود دارد؟
مجازی سازی دسکتاپ چیست؟
یکی از کارآمدترین راهکارهای مجازی سازی، مجازی سازی دسکتاپ (VDI) می باشد. در مجازی سازی دسکتاپ به هر کلاینت یک ماشین مجازی اختصاص داده می شود که متناسب با نیاز کلاینت، منابع پردازشی لازم در اختیار ماشین قرار می گیرد و سیستم عامل بر روی آن نصب می شود. در واقع کاربران روی میز کار خود از این سیستم عامل ها استفاده می کنند، در حالی که پردازش های مربوط به آن ها روی سرور انجام می شود. به عبارتی مجازی سازی دسکتاپ جدا سازی مکان قرارگیری سیستم عامل از محیط کاربری و انتقال آن به دیتاسنتر است.
سرورها برای به کارگیری مجازی سازی دسکتاپ و ساخت ماشین های مجازی که قابلیت های دسکتاپ را به صورت مجازی ارائه می دهند، از Hypervisorاستفاده می کنند.
به سناریو زیر توجه کنید:
فرض کنید سازمان شما به 150 کلاینت نیاز دارد، برای رفع این نیاز دو راه در پیش رو دارید. در رویکرد اول که روشی سنتی است، باید دیوایس هایی مانند کیس، all in one و... تهیه شود که برای این تعداد کلاینت می تواند هزینه ی خرید و پیاده سازی بالایی را به همراه داشته باشد. هزینه های نگهداری و پشتیبانی از تجهیزات و مصرف انرژی آن ها از فاکتور های مهم در محاسبه ی مخارج سازمان می باشد. از طرفی با توجه به مشکلات موجود در تامین انرژی، امروزه یکی از مهم ترین کارهایی که هر شخص باید در انجامش کوشا باشد، صرفه جویی در مصرف انرژی است اما در این رویکرد 150 دستگاه وجود دارد که هر کدام استهلاک، هزینه ی نگهداری و مصرف انرژی خود را دارند. بنابراین اتلاف انرژی زیاد و مقرون به صرفه نبودن از نتایج رویکرد اول خواهد بود. رویکرد دوم، همان راهکار مجازی سازی دسکتاپ است که به شما اجازه خواهد داد، منابع پردازشی خود را در دیتاسنتر گردآورید. اگر سازمان شما از رویکرد دوم استفاده کند، ممکن است هزینه ی پیاده سازی آن برابر با رویکرد اول یا حتی بیشتر از آن شود، اما هزینه ی نگداری کمتری را در آینده به شما تحمیل خواهد کرد. برای دستیابی به درکی بهتر از این مسئله به مثال زیر توجه کنید:
اگر سازمان شما نیازمند ارتقای منابع پردازشی کلاینتها باشد، رویکرد اول برای خرید سخت افزار و نصب آن روی کلاینت به هزینه های بیشتری نیاز دارد، در حالی که در مجازی سازی دسکتاپ، با استفاده از فضای مدیریتی که مجازی سازی در اختیارتان قرار می دهد به راحتی می توانید منابع پردازشی و ذخیره سازی یک کلاینت را ارتقا دهید. با استفاده از مجازی سازی دسکتاپ شما می توانید در مصرف انرژی صرفه جویی کنید، هزینه های نگهداری را کاهش دهید، امنیت بیشتر، مدیریت بهتر و بهینه تری را روی سیستم هایتان داشته باشید.
توجه کنید که مجازی سازی دسکتاپ (bare metal) را با نوعی مجازی سازی که توسط نرم افزار هایی مانند VMware Workstation و Virtual Box در دسکتاپ انجام می شود، اشتباه نگیرید.
مجازی سازی دسکتاپ مزایای زیادی برای فناوری اطلاعات و سازمان ها دارد. برخی از مهم ترین آن ها عبارت اند از:
صرفه جویی در هزینه ها : از منظر فناوری اطلاعات، مجازی سازی دسکتاپ هزینه های مدیریت و پشتیبانی و زمان ایجاد یک دسکتاپ جدید را کاهش می دهد. کارشناسان معتقدند که نگهداری و مدیریت منابع در محیط مجازی سازی شده 50 تا 70 درصد از مجموع هزینه مالکیت (TCO) یک محیط فیزیکی را دربر می گیرد. سازمان ها معمولا برای صرفه جویی در این هزینه ها به مجازی سازی دسکتاپ روی می آورند.
سهولت مدیریت : از آنجایی که در مجازی سازی همه چیز به صورت مرکزی مدیریت، ذخیره و محافظت می شود، مجازی سازی دسکتاپ نیاز به نصب، به روز رسانی، patch کردن برنامه ها، بک آپ گرفتن از اطلاعات و شناسایی ویروس ها در کلاینت های مختلف را از بین می برد. بنابراین مجازی سازی دسکتاپ به ساده سازی مدیریت برنامه های موجود کمک می کند. در مجازی سازی دسکتاپ می توان از کلاینت های قدیمی به عنوان ایستگاه های دریافت کننده سرویس دسکتاپ مجازی (Thin client) استفاده کرد. برخلاف کامپیوتر های شخصی که توان پردازشی، فضای ذخیره سازی و حافظه ی رم مورد نیاز برای اجرای برنامه ها را در داخل خود دارند، thin client ها به عنوان دسکتاپ های مجازی عمل می کنند و در بستر شبکه از توان پردازشی سرور موجود در شبکه بهره می برند.
امنیت بیشتر : مدیریت بهینه ی موجود در دسکتاپ های مجازی، امکان اتصال دستگاه های ذخیره ساز قابل حمل به سیستم های thin client را نمی دهد مگر اینکه دسترسی این عملکرد به کاربران داده شود. به همین خاطر امکان درز اطلاعات، نفوذ بد افزار ها و باج افزار ها به این سیستم ها کاهش پیدا می کند. مطلب دیگری که امنیت محیط مجازی سازی شده را افزایش می دهد این است که تمامی اطلاعات سازمان حتی اطلاعاتی که کاربران در پروفایل خود ذخیره می کنند در دیتاسنتر ذخیره و نگهداری می شود و از آنجایی که داده های کاربر به صورت مرکزی و منظم پشتیبان گیری می شود، مجازی سازی دسکتاپ مزایای یکپارچگی داده را نیز فراهم می کند.
بهره وری بیشتر : مجازی سازی دسکتاپ به کابران این امکان را می دهد که از طریق دستگاه های مختلف مانند دسکتاپ های دیگر، لپتاپ ها، تبلت ها و گوشی های هوشمند به برنامه ها و اطلاعات مورد نیاز دسترسی داشته باشند. این امر بهره وری را با ارائه اطلاعات مورد نیاز به کاربران در هر مکانی، افزایش می دهد. از طرفی اگر دستگاه یکی از کاربران آسیب دید از آنجایی که اطلاعات دسکتاپ به صورت locally ذخیره نمی شود، آن کاربر می تواند از دستگاه های دیگر برای دسترسی به دسکتاپ و رسیدگی به ادامه کارش استفاده کند.
Taipei, Taiwan, 2nd August 2018 – در این روز GIGABYTE به طور رسمی GPU تک پردازنده و سرورهای ذخیره سازی خود را به خانواده AMD EPYC اضافه کرد: سرورهای G291-Z20 با فرم فاکتور 2U و G221-30 GPU و سرور ذخیره ساز S451-Z30 با فرم فاکتور 4U .
AMD EPYC’s Single Socket Strengths
این سه سیستم جدید نشان دهنده مزایای AMD EPYC به عنوان یک سیستم دارای تک CPU است که می تواند، با منابع محاسباتی و I/O قابل توجه از EPYC شامل 32 هسته، 64 threads، بیش از 2TB از ظرفیت حافظه و 128 خط PCIe در هر سوکت، جایگزین مناسبی به ازای سرور های دارای دو CPU باشند.
به همان اندازه که سرور دارای دو CPU کارآمد است یک سرور تک CPU می تواند برای بسیاری از بارهای کاری نیز مفید باشد. بارهای کاریِ کمی وجود دارند که بیش از 16 thread همزمان برای هر کار یا فرآیند برنامه ریزی شده، تولید می کنند در حالی که اکثر آنها بیش از 8 thread را به ازای هر مورد تولید نمی کنند. آنهایی که بیش از 16 thread را در هر فرایند اجرا می کنند، معمولا دارای بار کاری با عملکرد محاسباتی بالا (HPC) هستند که برای انطباق با GPU به جای ارتقا به تعداد cpu های بیشتر مناسب هستند. بیشتر بارهای کاری ، مانند منطق کسب و کارهای در حال اجرا در ماشین مجازی و سرویس های Cloud micro در حال اجرا در containers ، می توانند بر روی سروری با یک عدد CPU با همان سرعتی اجرا شوند که بر روی سروری با 2 عدد CPU فیزیکی اجرا می شوند در حالی که از لحاظ اقتصادی مقرون به صرفه تر نیز هستند”
پشتیبانی AMD Radeon Instinct ™ MI25 GPU
هر دو سرور G291-Z20 و G221-Z30 به طور کامل با Radeon Instinct ™ MI25 GPU جدید AMD ، یکی از سریعترین شتاب دهنده های جهان، سازگار هستند. MI25 می تواند تا 24.6 TFLOPS از FP16 و TFLOPS 12.3 از حداکثر عملکرد FP32 را ارائه کند و ویژگی های بزرگ BAR (Base Address Register) را برای پشتیبانی از چندین پردازنده GPU برای ارتباطات peer to peer فراهم می کند. ترکیب راهکارهای CPU و GPU از AMD همراه با پلت فرم نرم افزار باز ROCm از آن ، اجازه افزایش همکاری و بهینه سازی، ارائه یک راه حل محاسبه قدرتمند با زمان تاخیر پایین برای مقابله با چالش هایی از HPC را فراهم می کند.
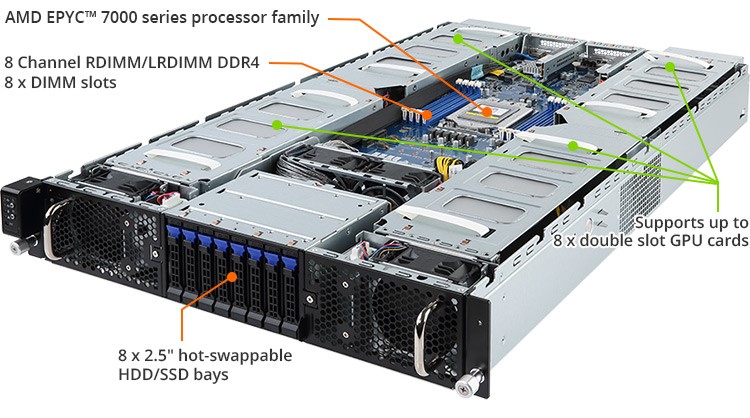
سرور های G291-Z20 :
این یک سرور HPC با تراکم بالا است که تا حداکثر 8 کارت PCIe Gen3 dual slot GPU را پشتیبانی می کند که شامل پشتیبانی از کارت های Radeon Instinct MI25، نیز می باشد. دیگر ویژگی های کلیدی این سرور شامل موارد زیر می باشد.
8 PCIe Gen3 double slot GPU cards
single AMD EPYC™ 7000 series processor family
8-Channel RDIMM/LRDIMM DDR4, 8 x DIMMs
2 x SFP+ 10Gb/s LAN ports (Mellanox® ConnectX-4)
1 x Dedicated management port
8 x 2.5" hot-swappable HDD/SSD bays
2 x M.2 with PCIe Gen3 x4/x2 interface
8 x PCIe Gen3 expansion slots for GPUs
2 x PCIe x16 half-length low-profile slots for add-on cards
Aspeed® AST2500 remote management controller
Dual 2200W 80 PLUS Platinum redundant/hot-swap power supply
با مشخصات فوق، GIGABYTE نشان می دهد که G291-Z20 برای برنامه های HPC مانند تجزیه و تحلیل های بی وقفه، برنامه های شبیه سازی و مدل سازی علمی، مهندسی، مجازی سازی و rendering، داده کاوی و دیگر ویژگی ها مناسب است.
سرور G221-Z30 :
اگر سرعت بالا در GUP برای شما کاربرد ندارد، گیگابایت سرورهای G221-Z30 را به شما پیشنهاد می دهد. GIGABYTE همچنان از یک پردازنده AMD Epyc 7000 استفاده می کند. دیگر ویژگی های کلیدی این سرور شامل موارد زیر می باشد :
Supports up to 2 x double slot GPU cards
AMD EPYC™ 7000 series processor family
8-Channel RDIMM/LRDIMM DDR4, 16 x DIMMs
2 x SFP+ 10Gb/s LAN ports (Broadcom® BCM 57810S)
1 x Dedicated management port
16 x 2.5" hot-swappable HDD/SSD bays
Ultra-Fast M.2 with PCIe Gen3 x4 interface
4 x PCIe Gen3 expansion slots
Aspeed® AST2500 remote management controller
Dual 1200W 80 PLUS Platinum redundant power supply
خریداران سرور G221-Z30 به دنبال یک راهکار چند منظوره HPC انعطاف پذیر و مقرون به صرفه برای تحقیق و توسعه هستند.
سرور ذخیره ساز S451-Z30 :
در اینجا یک گزینه جذاب قابل انعطاف برای خریداران سرور ذخیره ساز وجود دارد.
Single AMD EPYC™ 7000 series processor family
8-Channel RDIMM/LRDIMM DDR4, 16 x DIMMs
2 x SFP+ 10Gb/s LAN ports (Broadcom® BCM 57810S)
1 x dedicated management port
36 x 3.5" SATA/SAS hot-swap HDD/ SSD bays
2 x 2.5" SATA hot-swap HDD/SSD for booting device
SAS expander with 12Gb/s transfer speed
Ultra-Fast M.2 with PCIe Gen3 x4 interface
Up to 4 x PCIe Gen3 x16 slots and 3 x PCIe Gen3 x8 slots
Aspeed® AST2500 remote management controller
Dual 1200W 80 PLUS Platinum redundant power supply
معرفی SDS های شرکت HPE همانطور که می دانید امروزه از SDDC ها استفاده می شود که باعث کاهش هزینه و افزایش سرعت پیاده سازی می شوند. یکی ار مهمترین تکنولوژیهایی که باید در SDDC ها استفاده شود، SDS می باشد (Software Defined Storage) . به عنوان مثال می توان VSAN را در Vmware به عنوان SDS نام برد. شرکت HPE نیز بدین منظور Store Virtual را معرفی می کند، که در دو مدل مختلف تولید و به بازار عرضه می شود. در حالت اول Virtual Storage Appliance می باشد که روی مجازی سازی Hypervisor پیاده سازی می شود. برای راه اندازی این مدل باید لایسنس StorVirtual VSA خریداری شود. در مدل دوم Converged Solution Appliance تولید می شود که یک سخت افزار اختصاصی به منظور راه اندازی SDS می باشد و دستگاههای StoreVirtual در این حوزه قرار می گیرند.به عنوان مثال در این زمینه می توان Converged System 250 را نام برد که پلتفرم این دستگاه Apollo 2000 می باشد. این SDS ها مبتنی بر سیستم عامل Lefthand می باشند که همان SAN iQ نامیده می شود. تکنولوژی SDS مناسب برای مجازی سازی دسکتاپ و مجازی سازیمی باشد و بسیار مقیاس پذیر هستند و باعث افزایش سرعت پیاده سازی می شوند.
اگر شما یک توسعه دهنده نرم افزاری ، یک فرد حرفه ای در فناوری اطلاعات و یا از علاقمندان تکنولوژی هستید ، بسیاری از شما نیاز به اجرا کردن چند نوع سیستم عامل دارید. Hyper-V به شما اجازه می دهد چند سیستم عامل را به عنوان ماشین های مجازی در ویندوز اجرا کنید.
Hyper-V به طور خاص مجازی سازی سخت افزاری را فراهم می کند. این بدان معنی است که هر ماشین مجازی بر روی سخت افزار مجازی اجرا می شود. Hyper-V به شما اجازه می دهد دیسک های سخت افزاری مجازی، سوئیچ های مجازی و تعدادی از دستگاه های مجازی دیگر را که می توانید به ماشین های مجازی اضافه کنید ایجاد کنید.
دلایل استفاده از مجازی سازی
مجازی سازی به شما اجازه می دهد:
اجرای نرم افزار که نیاز به نسخه های قدیمی تر از سیستم عامل های ویندوز و یا غیر ویندوز دارد.
آزمایش با سیستم عامل های دیگر. Hyper-V محیطی بسیار آسان برای ایجاد و حذف سیستم عامل های مختلف ایجاد می کند.
تست نرم افزار روی چند سیستم عامل با استفاده از چندین ماشین مجازی. با Hyper-V ، شما میتوانید همه سیستم عامل ها را روی یک دسکتاپ یا کامپیوتر شخصی اجرا کنید. این ماشین های مجازی را می توان بیرون آورد و سپس وارد سیستم Hyper-V دیگر ، از جمله Azure کرد.
سیستم مورد نیاز :
Hyper-V در نسخه های 64 بیتی ویندوز Professiomal ، Enterprise و Education در ویندوز 8 و بعد از آن ، در دسترس است. این نسخه در ویندوز Home دردسترس نیست.
ارتقا از ویندوز 10 نسخه Home به ویندوز 10 نسخه Professional از طریق Opening Settings> Update and Security> Activation و خریداری یک ارتقا صورت می گیرد.
اکثر کامپیوتر ها Hyper-V را اجرا می کنند هرچند هر ماشین مجازی سازی یک سیستم عامل کاملا جداگانه را داراست. شما معمولا می توانید یک یا چند ماشین مجازی را روی یک کامپیوتر با 4 گیگابایت رم اجرا کنید ، هرچند به منابع بیشتری برای ماشین های مجازی اضافی و یا نصب و اجرای نرم افزارهای سنگین مانند بازی، ویرایش ویدئو و یا نرم افزار طراحی مهندسی نیز دارید.
سیستم عامل هایی که میتوانید در یک ماشین مجازی اجرا کنید :
Hyper-V در ویندوز از بسیاری از سیستم عامل های مختلف در یک ماشین مجازی از جمله نسخه های مختلف لینوکس، FreeBSD و ویندوز پشتیبانی می کند.
به عنوان یادآوری ، شما لایسنس معتبر برای هر سیستم عامل که در VM ها استفاده می کنید باید داشته باشید.
تفاوت های Hyper-V در ویندوز و Hyper-V در ویندوز سرور :
برخی از ویژگی های موجود در Hyper-V در ویندوز متفاوت از Hyper-V در حال اجرا بر روی ویندوز سرور هستند.
تنها ویژگی های Hyper-Vموجوددر ویندوز سرور :
انتقال ماشین های مجازی از یک هاست به دیگر هاست ها.
Hyper-V Replica
Virtual Fiber Channel
SR-IOV networking
Shared .VHDX
تنها ویژگی های Hyper-Vموجود در ویندوز 10 :
Quick Create and the VM Gallery
Default network (NAT switch)
مدل مدیریت حافظه برای Hyper-V روی ویندوز متفاوت است. روی سرور، حافظه Hyper-V مدیریت می شود با فرض این که تنها ماشین های مجازی در حال اجرا روی سرور هستند. در Hyper-V روی ویندوز ، مقداری از حافظه بر اساس نیاز های نرم افزاری ماشین های کاربری و مقداری برای اجرا کردن ماشین مجازی توسط هاست مورد استفاده قرار میگیرد.
محدودیت ها :
برنامه هایی که به سخت افزار خاص نیاز دارند، در یک ماشین مجازی خوب کار نخواهد کرد. به عنوان مثال، بازی ها یا برنامه هایی که نیاز به پردازش با GPU دارند ممکن است به خوبی کار نکنند. همچنین برنامه های وابسته به زمان های زیر 10 میلی ثانیه مثل برنامه های پخش زنده موزیک یا برنامه هایی با زمان دقت بالا ، می توانند در اجرا بر روی ماشین مجازی دچار اشکالاتی شوند.علاوه بر این، اگر شما Hyper-V را فعال کنید، برنامه های دارای حساسیت و دقت بالا نیز ممکن است هنگام اجرای روی هاست دچار مشکلاتی شوند.
این به این دلیل است که با مجازی سازی فعال شده ، سیستم عامل هاست نیز در بالای لایه مجازی سازی Hyper-Vاجرا می شود، همانطور که سیستم عامل مهمان اجرا می شود. با این حال، بر خلاف مهمان ها، سیستم عامل هاست دارای این ویژگی است که به تمام سخت افزارها دسترسی مستقیم دارد، به این معنی که برنامه های کاربردی با نیازهای سخت افزاری خاص همچنان می توانند بدون مشکل در سیستم عامل هاست اجرا شوند.
Virtualization (مجازی سازی) فرایند ایجاد یک نسخه مجازی از چیزی مانند نرم افزار، سرور، استوریج و شبکهاست. این فرایند موثرترین راه برای کاهش هزینه های دنیای فناوری اطلاعات است در حالی که در تمام سطوح کارایی و بهره وری آن را افزایش می دهد.
مزایای مجازی سازی
مجازی سازی می تواند کارایی، انعطاف پذیری و مقیاس پذیری دنیای فناوری اطلاعات را افزایش دهد در حالی که هزینه ها را به طور قابل توجهی کاهش می دهد. جابجایی پویاتر بارهای پردازشی، عملکرد و دسترسی به منابع بهبود یافته و عملیات هایی که به صورت خودکار انجام می شوند. این ها همه مزایایی هستند که توسط مجازی سازی، مدیریت فناوری اطلاعات را ساده تر می کنند و هزینه های راه اندازی و نگهداری را کاهش می دهند. مزایای بیشتر مجازی سازی شامل موارد زیر می شود:
کاهش هزینه های عملیاتی
Downtime ها را کاهش داده و یا از بین برده
افزایش بهره وری، کارایی و پاسخگویی دنیای IT
آماده سازی سریعتر برنامه ها و منابع
تداوم کسب و کار و بهبود بازیابی اطلاعات
ساده سازی مدیریت دیتا سنتر
مجازی سازی چگونه کار می کند؟
با توجه به محدودیت های سرور های x86، سازمان ها باید سرورهای متعددی را تهیه کنند تا سرعتشان را در سطح نیازهای پردازشی و ذخیره سازی امروزه نگه دارند، در حالی که این سرورها از تمام ظرفیت های خود استفاده نمی کنند. نتیجه ی آن ناکارآمدی و صرف هزینه های زیاد است.
Virtualization از نرم افزار استفاده می کند تا عملکرد سخت افزار را شبیه سازی کند و یک سیستم کامپیوتر مجازی بسازد. این موضوع سازمان ها را قادر می سازد که در یک سرور بیش از یک سیستم کامپیوتر مجازی بسازند (که هر کدام می توانند سیستم عامل و نرم افزار های مختلفی را داشته باشند). مزایای آن عبارت اند از مقرون به صرفه بودن و بهره وری بهتر.
Virtual Machine
سیستم کامپیوتری مجازی که به نام ماشین مجازی (VM) شناخته می شود، یک محفظه ی نگهدارنده ی نرم افزار است که می تواند یک سیستم عامل و یا برنامه هایی را داخل خود داشته باشند. ماشین های مجازی کاملا از یک دیگر مستقل هستند. قرار دادن چندین VM در یک سیستم این اجازه را می دهد که سیستم عامل ها و برنامه های مختلفی را فقط در یک سرور فیزیکی و یا یک هاست اجرا کنیم.
یک لایه نازک از نرم افزار به نام “hypervisor” ماشین های مجازی را از هاستی که روی آن نصب شده اند جدا می کند. hypervisor متناسب با نیاز هر ماشین و به صورت پویا، منابع پردازشی را به ماشین ها اختصاص می دهد.
کلمات کلیدی مربوط به مجازی سازی
ماشین های مجازی مشخصات زیر را دارند که هر کدام فواید مختلفی را ارائه می کنند.
Partitioning
اجرا کردن سیستم عامل های مختلف روی یک سرور
تقسیم کردن منابع سیستم بین ماشین های مجازی
Isolation
امنیت و بروز خطا برای هر ماشین مجازی در سطح سخت افزار ایزوله است
حفظ عملکرد ماشین ها با کنترل پیشرفته ی منابع پردازشی
Encapsulation
حالت کلی هر ماشین مجازی در فایل هایی ذخیره می شود
ماشین های مجازی به سادگی جابجایی فایل ها، انتقال می یابند
مجازی سازی سرور این امکان را می دهد که سیستم عامل های مختلفی را روی یک سرور به صورت ماشین های مجازی با بهره وری بالا، اجرا کنیم. فواید کلیدی آن به صورت زیر است:
کارایی بهتر
کاهش هزینه عملیاتی
انجام سریع کار های سنگین
بهبود عملکرد برنامه ها
در دسترس بودن بالای سرور
از بین بردن پیچیدگی سرور و جلوگیری از بی مصرف ماندن سرور
مجازی سازی شبکه
مجازی سازی شبکه ساخت دوباره ی یک شبکه فیزیکی به صورت کامل و منطقی است. مجازی سازی شبکه این امکان را می دهد که برنامه ها دقیقا به همان صورت که در شبکه ی فیزیکی اجرا می شوند در یک شبکه مجازی اجرا شوند که فواید عملیاتی بهتر و استقلال سخت افزاری موجود در مجازی سازی را به همراه دارد. مجازی سازی شبکه، دستگاه ها و سرویس های شبکه را به صورت منطقی ارائه می کند (مانند سوئیچ، روتر، فایروال و vpn)
مجازی سازی دسکتاپ
استقرار دسکتاپ به عنوان یک سرویس مدیریت شده مجازی سازی دسکتاپ این امکان را می دهد که سازمان های IT در مقابل تغییر نیاز ها و فرصت های در حال ظهور سریعتر پاسخ دهند. برنامه ها و Desktopهای مجازی را می توان به سرعت در دسترس کارکنان سازمان قرار داد در حالی که مکان این کارکنان میتواند در داخل سازمان و یا اینکه دور از سازمان باشد. این کارکنان حتی می توانند از ipad و تبلت های اندرویدی خود برای دسترسی به این برنامه ها و desktopها استفاده کنند.
مجازی سازی در مقابل CLOUD COMPUTING
اگرچه مجازی سازی و Cloud Computing هر دو تکنولوژی های فوق العاده ای هستند اما نمی توان آن ها را به جای هم نام برد و استفاده کرد. مجازی سازی یک راهکار نرم افزاری است که محیط محاسبات پردازشی را از زیرساخت های فیزیکی مستقل می کند، در حالی که Cloud Computing سرویسی است که با دریافت تقاضا منابع محاسباتی به اشتراک گذاشته (مانند نرم افزار یا اطلاعات) را از طریق اینترنت در دسترس دریافت کننده ی سرویس قرار می دهد. به عنوان یک راه حل تکمیلی، سازمان ها می توانند با مجازی سازی سرور های خود شروع کنند، سپس به سمت استفاده از Cloud Computing حرکت کنند تا کارایی بهتر و سرویس بهینه تری را داشته باشند.
تعریف Hyper-Converged: با توجه به افزایش سرعت IT امروزه بسیاری از سازمان ها نیاز به راه اندازی مجازی سازیو منابع پردازشی در زمان کمی دارند. منظور از Hyper-Converged استفاده از راه حلی می باشد که بتوان به سرعت منابع پردازشی، ذخیره سازی، شبکه ، مجازی سازی سرور ، مجازی سازی دسکتاپ، مجازی سازی شبکهرا در یک سازمان راه اندازی کرد. در واقع Hyper-converged تمامی موارد فوق را در یک دستگاه جمع آوری نموده است و بصورت Appliance در اختیار ما قرار می دهد و در مدت کمتر از 15 دقیقه می توانیم زیر ساخت های IT را در سازمان راه اندازی کنیم. شرکت HPE امروزه دستگاه 250 و 380 را برای hyper-converged می سازد و به بازار عرضه کرده است.
معرفی پردازنده های EPYC که بر روی سرور های HPE DL385 G10 استفاده می شود.
این پردازنده ها نسبت به پردازنده های قدیمی تر 122 برابر پهنای باند بیشتری را برای Memory پوشش می دهند و 60 برابر I/O بیشتری را Support می کنند و تا 45 برابر هسته های بیشتری نسبت به محصولات مشابه رقبای خود دارند. این پردازنده های طراحی شده و بهینه شده برای مجازی سازی و Cloud می باشند. این پردازنده ها می توانند تا 32 هسته داشته باشند، تا 2 ترابایت RAM را در 8 کانال مجزا پوشش می دهند و برای اسلات های PCIe هم 128 لاین دارند. همچنین از مزیت های دیگر آنها این است که دارای یک سیستم امنیتی یکپارچه هستند که باعث محافظت از پردازش ها خواهد شد. این پردازنده های دارای مدل های زیر می باشند: 7601 7551 7501 7451 7401 7351 7301 7281 7251 که پایین ترین مدل آن یعنی 7251 دارای 8 هسته می باشد و مدل 7601 دارای 32 هسته می باشد .تمامی این پردازنده ها 2 ترابایت Memory را پوشش می دهند و توان مصرفی آنها نیز بسته به مدل بین 120 تا 180 وات می باشد. همچنین Cache آنها نیز بین 32 تا 64 مگا بایت می باشد. از مهمترین مزیت های این پردازنده این این است که فاقد Chipset هستند و در واقع تمامی موارد درون Chipset بصورت یکپارچه درآمده است که همان معنی SOC را می دهد. روی سرور DL385 G10 می توان 2 پردازنده قرار داد. این پردازنده ها همانطور که در بالا ذکر شد بسیار مناسب برای مجازی سازیسرور می باشد و باعث می شود50 درصد کاهش هزینه به ازای هر ماشین مجازی داشته باشیم.
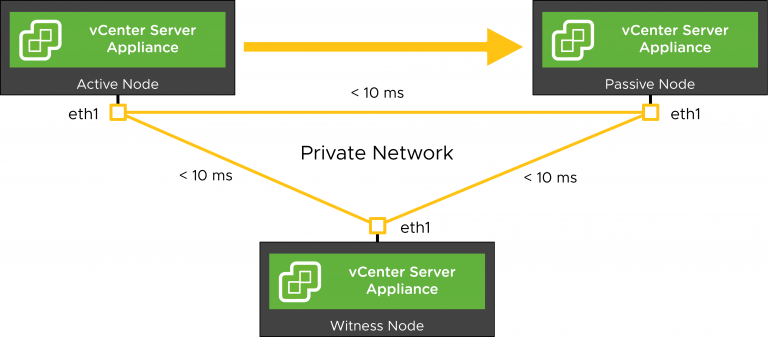
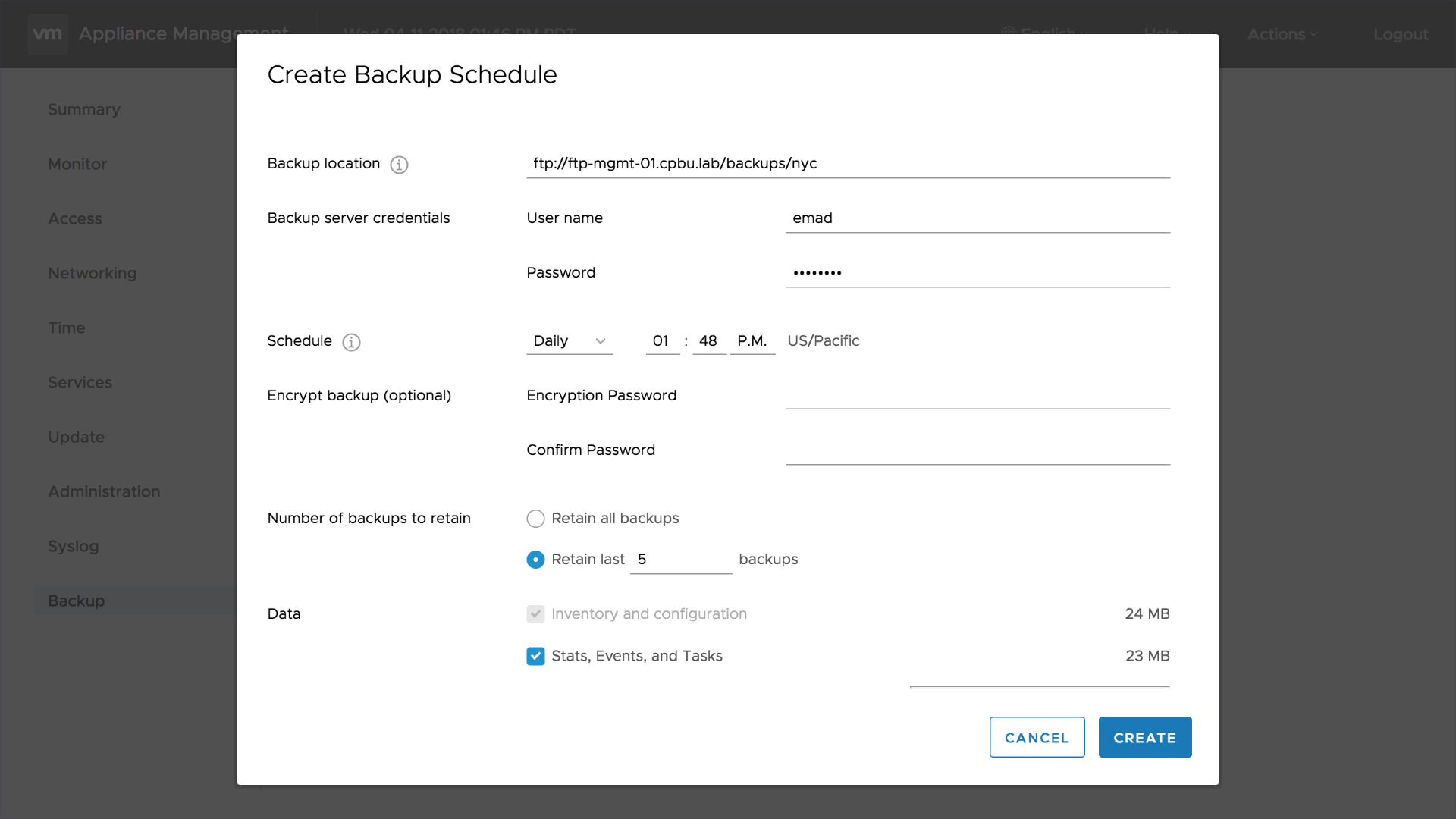
در مقالات قبل درباره ویژگی HA برای شما صحبت کردیم . اما VCHA قابلیتی است که وظیفه دیگری را برعهده دارد. این موضوع احتمالا یکی از مواردی است که بیشتر وقت خود را در هنگام صحبت با مشتریان صرف آن می کنید. قابلیت (vCenter High Availability (VCHA در نسخه vSphere 6.5 در نوامبر 2016 معرفی شد.
قبل از اینکه شروع کنیم چند نکته را باید در نظر داشته باشید .
قابلیت VCHA از 3 نود تشکیل شده است. (Active – Passive – Witness)
برای راه اندازی تنها به یک vCenter Server Instance License نیاز است.
از Tiny Deployment استفاده نکنید. (این مورد برای موارد آزمایشگاهی استفاده میکنند)
از هر دو حالت Embedded PSC و Extended PSC پشتیبانی میکند.
قابلیت VCHA با DR یکی نیست.
بسیار خب ، اولین اقدامی که باید صورت بگیرید ، گرفتن Clone ها میباشد . از نود Active به نود Passive و سپس Witness عملیات Clone گرفتن را طی میکینم. کاری که قبل از گرفتن Clone انجام میدهیم اضافه کردن یک Second Adapter میباشد . و همچنین Primary Adapter را داریم که Management Interface نامیده میشود و شامل FQDN , IP , MAC Address میباشد. این Adapter ها همچنین در نود پسیو وجود دارد اما به صورت آفلاین ، تا تداخلی در شبکه ایجاد نشود و تنها زمانی که نود اکتیو Fail شود و نود پسیو به اکتیو تبدیل شود ، آنلاین میوشد.
هر سه Second Adapter یک شبکه Private که به آن VCHA Network میگوییم تشکیل میدهند . این شبکه از Management Network مجزا است و این 3 نود میتوانند آی پی داشته باشند تا با هم ارتباط داشته باشند . این ارتباط میتواند Layer3 یا Layer2 باشد.
سرور vCenter شامل یک دیتابیس و یک فایل سیستمی که حاوی تنظیمات ، گواهینامه ها و …. است . پس نیاز داریم این دو دسته از اطلاعات را به نود Passive منتقل کنیم ، درنتیجه به یک Replication نیاز است. برای Replicate دیتابیس از مکانیزم Sync و برای فایل سیستمی از مکانیزم Async استفاده میشود.
وقتی نود Active دچار یک Failure شود ، اینترفیس نود Passive آنلاین میشود . از طریق ARP به شبکه اعلام میکند که از این لحظه به عنوان نود اکتیو عمل میکند و Ownership اطلاعات IP و MAC نود اکتیو را میگیرد .
بعد از این اتفاق ما دو انتخاب داریم :
نود Fail شده را Troubleshoot کنیم و دوباره نود را انلاین کنیم ،درنتیجه Replication به روال قبل ادامه میابد .
اما اگر نتوانیم دوباره آنرا اکتیو کنیم ، در تنظیمات VCHA میتوانیم ، در vCenter ماشین قبلی را حذف و نود جدید را دوباره Redeploy کنیم ، تمام این عملیات non-disruptive میباشد.
حال اگر نود Witness دچار Fail شود چه ؟
از دست دادن Witness برای vCenter Server Instance به صورت non-disruptive میباشد اما کلاستر در حالت Degraded State میرود. پس برای اینکه کلاستر به صورت سلامت عمل کند هر 3 نود باید آنلاین و به صورت سالم وجود داشته باشند. و هرکدام از نود های Passive یا Witness مشکل داشته باشند ، کلاستر در حالت Degraded State میرود و در این حالت Automatic Failover از نود Active به Passive انجام نخواهد شد و این این امر به منظور جلوگیری از وجود دو نود فعال در کلاستر میباشد.
وقتی درمورد PSC و VCHA صحبت میکنیم ، ابتدا باید تصمیم بگیرید که آیا از Enhanced linked mode استفاده میکنید؟ اگر پاسخ شما مثبت است ، در نسخه 6.5 شما باید از External PSC استفاده کنید.
پس اگر از External PSC استفاده میکنیم ، به یک Load balancer نیاز داریم . دلیل این امر این است که وقتی VCHA داریم ، نود اکتیو به صورت مشخص به PSC متصل باشد ، وقتی PSC دچار مشکل شود ، ما باید به صورت دستی آنرا به PSC دیگر متصل کنیم وقتی اینکار را انجام دهیم ، مکانیزم Repoint به نود Passive ما Replicate نمیشود ، پس آن نود همچنان به PSC ای که Fail شده اشاره میکند . پس اگر نود Active Fail شود و نود Passive به Active تبدیل شود به مشکل برخواهیم خورد.
حالا سوال اصلی اینجاست ، چرا سرور vCenter را Highly available میکنیم اما Platform services controller را نه ؟! با کمک روش ذکر شده در مثال بالا ما هر دو اینها را Highly available میکنیم و در آن زمان است یک راه حل کامل را ارائه کرده ایم.
در مقالات بعدی سعی خواهد شد مطالب عمیق تری درباره این ویژگی برای شما توضیح داده شود ، پس همراه ما باشید ….
بلاک چین 1 یک سیستم برای نگهداری دفتر حساب های توزیع شده است به طوری که اجازه می دهد سازمانهایی که اعتماد کافی به یکدیگر ندارند بر روی بروزرسانی این دفتر حساب ها به توافق برسند. به جای استفاده از شخص ثالث مرکزی یا فرآیند تطبیق حساب آفلاین، بلاک چین از پروتکل های peer to peer استفاده می کند. بلاک چین به عنوان یک دفتر حساب توزیع شده، یک رکورد پاک نشدنی و آنی را فراهم می کند که در میان شرکت کنندگان آن کپی می شود.
بلاک چین این پتانسیل را دارد که اساسا چگونگی انجام معاملات تجاری جهانی را تغییر دهد. در حال حاضر برخی از معاملات از طریق شخص ثالث انجام و تعیین مسیر می شوند تا صداقت و حفاظت در معامله را تضمین کنند. وجود این اشخاص ثالث می تواند منجر به بروز تاخیرها در پرداخت و حتی افزایش هزینه ها شود. تکنولوژی بلاک چین منجر می شود که شرکت کنندگان در شبکه مورد اعتماد تجاری به طور مستقیم معاملاتشان را انجام دهند در حالی که از اعتبار و ثبات معاملاتشان مطمئن خواهند بود. هنگامی که معاملات پیشنهاد شده اعتبار می یابند و توافق بر روی پیامدهای آن به دست می آید، شرکت کنندگان در تکنولوژی بلاک چین، آنها را در بلاکهایی مرتبط به هم و رمزنگاری شده ثبت می کنند که قابل لغو شدن نیستند.
این تکنولوژی به حل و فصل بسیاری از چالش ها در مقیاس enterprise کمک می کند، همچون:
ایجاد اعتماد در معاملات BTB 2 نظیر به نظیر، به طوری که از هزینه ها و خطرات واسطه ها جلوگیری می شود
کاهش روش های دستی، مبادله اطلاعات در معرض خطا و فرآیندها
پرهیز از هزینه و تاخیرهای تطبیق آفلاین
کاهش تطبیق های cross-ERP که منجر به خطرات واریز اسناد و ثبت های ضعیف می شود
کاهش خطرات بالای تقلب در معاملات میان شرکت ها
بهبود قابلیت رویت اطلاعات به طور آنی در اکوسیستم تجاری
مکانیزم بلاک چین :
سیستم بلاک چین شبکه ای نظیر به نظیر از نودهای معتبر است. هر نود دفتر حسابی حاوی اطلاعات و تاریخچه ای از بروزرسانی ها را نگاه می دارد.
تغییرات درون این دفترحساب ها، از طریق معاملات پیشنهاد شده توسط طرف های خارجی به وسیله کلاینتها راه اندازی می شود. هنگامی که از طریق معاملات تغییرات رخ می دهد، شرکت کنندگان در بلاک چین منطق بیزینس (به اصطلاح قراردادهای هوشمندانه) را اجرا می کند و برای تایید نتایج از پروتکل های اجماع 3 پیروی می کنند.
هنگامی که تحت قوانین شبکه توافق به دست می آید، معاملات و نتایج آنها درون بلاک های داده ای دسته بندی می شوند که به واسطه رمزنگاری ایمن و غیرقابل تغییر هستند و توسط هر کدام از شرکت کنندگان به دفتر حساب اضافه شده اند.
علاوه بر تمام معاملات و نتایج آنها، هر بلاک حاوی هش رمزنگاری از بلاک قبلی است که تضمین می کند، هر گونه سوء استفاده از یک بلاک خاص به راحتی شناسایی شود.
فواید بلاک چین :
بلاک چین فرآیند زمانگیر و پیچیده در معاملات BTB را با روشی که شفاف، قابل بازبینی و تضمین کننده است، جایگزین می کند. فواید آن برای کسب و کارهای امروزی شامل:
واسطه های کمتر
اجتناب از واسطه های متمرکز با استفاده از شبکه کسب و کار نظیر به نظیر
فرآیندهای سریع تر و اتوماتیک تر
فرآیندها و مبادله داده ها را اتوماتیک می کند. مغایرت های آفلاین را حذف می کند. به طور خودکار اقدامات، حوادث و حتی پرداخت ها بر اساس شرایط از پیش تعیین شده فعال می شوند. فرایندهایی که روزها (یا هفته ها) انجام می شد در حال حاضر به طور آنی انجام می شود.
کاهش هزینه ها
هزینه ها به واسطه شتاب بخشیدن به معاملات و حذف فرآیندهای واریز اسناد با استفاده از ساختار اشتراکی قابل اعتمادی از اطلاعات مشترک به جای اتکا بر واسطه های متمرکز یا فرآیندهای تطبیق پیچیده کاهش می یابد.
اتوماسیون سریع تر
به طور خودکار اقدامات، حوادث، و حتی پرداخت بر اساس شرایط از پیش تعیین شده راه اندازی می شوند. از طریق خودکارسازی فرآیندها برای کار خارج از ساعت های کاری، معاملات را سرعت می بخشد.
افزایش شفافیت
شرکت کنندگان بی درنگ معاملات توزیع شده در سراسر شبکه کاری مصوب خود را می توانند مشاهده نمایند. یک سیستم اشتراکی از رکوردها نگهداری می شود که همه در آن به میزان یکسانی از وقایع مطلع هستند.
افزایش امنیت
تقلب را کاهش می دهد در عین حال که با تضمین رکوردهای حیاتی تجاری، پذیرش قوانین تنظیم شده را افزایش می دهد.با استفاده از بلاک های مرتبط رمزنگاری شده داده ها را ایمن نگاه می دارد به طوری که رکوردها نمی توانند بدون شناسایی حذف شوند یا تغییر کنند.
بلاک چین در مقایسه با پایگاه داده مرکزی
بلاک چین یک دفتر حساب توزیع شده است که به طور مستقیم از طریق گروهی از اشخاص که الزاما مورد اعتماد یکدیگر نیستند، به اشتراک گذاشته می شود بدون اینکه به یک ادمین مرکزی شبکه نیازی باشد. در مقابل یک پایگاه داده سنتی (SQL یا NoSQL) به وسیله نهاد واحدی کنترل می شود. این تفاوت مهمی است به این معنا که:
هر نود در بلاک چین به طور مستقل هر معامله را پردازش و بررسی می کند. یک نود از آنجایی این توانایی را دارد که دارای قابلیت رویت کامل به وضعیت فعلی پایگاه داده، تغییرات درخواست شده توسط یک معامله و امضای دیجیتالی است که سرچشمه معامله را ثبت می کند.
معاملات و داده های مبتنی بر بلاک چین، تحمل پذیری بسیار بالایی را به علت افزونگی نهفته در آن دارند.
بروزرسانی ها توسط شرکت کنندگان پیش از انجام آنها توافق شده است، در مقایسه با یک محیط پایگاه داده معمولی که در آن به روز رسانی ها توسط هر طرف انجام می شود و سپس از طریق پردازش های طاقت فرسا (و اغلب آفلاین) تطبیق داده می شوند.
نقش آفرینی بلاک چین تقریبا بی وقفه در حال انجام است چرا که هیچ تاخیری از دفتر مرکزی نقل و انتقال بانکی یا فرآیند های تطبیق وجود ندارد درحالی که پیش از این بررسی ها اغلب در طول شب یا در طول چندین روز یا هفته صورت می گرفت.
Veeam Backup & Replication یک برنامه پشتیبانی و محافظت از داده هاست که برای محیط های مجازی VMware vSphere و Microsoft Hyper-V hypervisors توسط شرکت Veeam ساخته شده است.این نرم افزار قابلیت پشتیبان گیری ، replication و Restore کردن ، برای ماشین های مجازی ارائه نموده است. عملکرد: Veeam Backup & Replication برای محیط های مجازی سازی شده طراحی گردیده است. به وسیله snapshots گرفتن از ماشین ها و استفاده از این snapshots برای گرفتن بکاپ که به دو صورت Full و Incremental است. برای بازگردانی داده ها می توان نسخه پشتیبان گرفته شده را در محل ذخیره شده قبلی یا در مکانی دیگر بازیابی نمود .
گرفتن Snapshots به وسیله VMware vSphere میتواند بار سنگینی بر عملکرد ماشین های مجازی بگذارد و مدیران IT را به چالش بکشد.Veeam به طرز چشمگیری این روند را بهبود بخشیده است.با استفاده از Snapshots گرفتن در سطح استوریج حتی در ساعات کاری با کمترین تاثییر بر عملکرد می توانید از داده های خود بکاپ تهیه نمایید.Veeam می تواند با ادغام با replication در سطح استوریج در صورتی که استوریج اصلی در دسترس نباشد و دچار مشکل شده باشد به سرعت داده شما را بازیابی نماید.
Storage partners for every business در زیر لیست شرکت های تولید کننده استوریج که از Veeam Backup & Replication پشتیبانی نموده، آورده شده است. به وسیله این استوریج ها می توان سریع تر نسخه پشتیبانی از ماشین ها را تهیه نمود و سرعت باز گردانی اطلاعات را افزایش داد.
Recovery نرم افزار veeam backup برای بازگردانی اطلاعات انتخاب های مختلفی را به کاربران ارائه می دهد. Instant VM Recovery به وسیله Instant VM Recovery کاربران veeam backup می توانند ماشین هایی که از آن بکاپ تهیه نموده اند را به سرعت در محل ذخیره بکاپ بالا بیاورند.
Full VM Recovery به وسیله Full VM Recovery میتوانید آخرین وضعیت ماشین ها را در بازه های مشخص زمانی در هاست اصلی یا هاست دیگر، بازیابی نمایید. VM رامی توان در مکان اصلی که از آن بکاپ گرفته شده است ، در صورتی که آن ماشین خاموش باشد یا پاک شده باشد بازیابی نمود. و یا بازیابی در هاست جدید صورت گیرد که در این صورت تنظیمات ماشین باید قابل دسترسی باشد. (تنظیمات شبکه ، دیتا سنتر) VM File Recovery به وسیله Instant File-Level Recovery (IFLR) شما می توانید هر فایل مورد نظرتان را در بازه زمانی مشخص بازیابی نمایید. همچنین veeam از فایل سیستم های ویندوزی و لینوکسی پشتیبانی می نماید.
وحتی می توانید فایل های ماشین را مانند VMDK را بازگردانی نمایید. Application-item recovery: با استفاده از veeam backup می توانید به صورت مستقیم برای بازیابی Application های زیر استفاده نمایید. Microsoft Active Directory
Microsoft Exchange Microsoft SharePoint
Microsoft SQL Server
Oracle با توجه به مختصر توضیحات بالا و با استناد به گزارش سال 2017 از Gartner ، veeam backup and replication توانسته جز 5 شرکت پیشرو در صنعت بکاپ و ریکاوری باشد.
در زیر نقاط قوت و ضعف آن را مشاهده می کنید که توسط Gartner اعلام شده است: نقاط قوت: Veeam قابلیت های بسیاری با گزینه های بازیابی ساده برای محیط VMware و Hyper-V ارائه نموده است. برای چندمین سال پیاپی یکی از سریع ترین شرکت های در حال رشد در صنعت پشتیباتی بوده است. نقاط ضعف: بسیاری از مشتریان به این نکته اشاره کرده اند که سیاست قیمت گذاری لایسنس اغلب دیگر رقابتی نیست در حالی که مدیریت و ریکاوری در Veeam ساده می باشد. اندازه مناسب برای ذخیره سازی بکاپ و پیکربندی در مرحله نصب ممکن است توجه بیشتری نیاز داشته باشد زیرا نرخ تغییرات در ماشین های مجازی بسیار بالا می باشد. Veeam فقط به طور رسمی اعلام نموده است که از سرور فیزیکی پشتیبانی می کند ولی هنوز به طور کامل این ویژگی را ادغام و اثبات ننموده است . نتیجه گیری: امروزه تداوم کسب و کار معنای جدیدی به خود گرفته است . زمانی که داده ها به عنوان منبع حیاتی کسب و کار شما است حفظ اطلاعات شما و اطمینان از صحت و در دسترس بودن آن یک اولویت است. به دلیل کاهش سرور های فیزیکی و افزایش ماشین های مجازی مدیران فناوری اطلاعات با یک سری جدید از مسائل محافظت از داده ها و چالش های پشتیبانی مواجه شده اند.این چیزی بیش از یک کپی از فایل های مهم است. وضعیت هر VM نیز باید محافظت شود و به راحتی قابل دسترس باشد. هر سازمان باید نیاز های بکاپ گیریش را در چهارچوب زیر ساخت مجازی مجددا ارزیابی نماید و سپس مناسب ترین فن اوری ها را برای ارائه بهتر محافظت از داده ها انتخاب کند. Veeam با توجه به ویژگی هایی که برای محیط مجازی ارائه نموده است می تواند یکی از بهترین انتخاب ها برای محیط مجازی باشد.
سوئیچ های سیسکو با استفاده از پروتکل STP، از به وجود آمدن loop در شبکه جلوگیری می کنند. در یک LAN که دارای مسیر های redundant می باشد، اگر پروتکل STP فعال نباشد، باعث به وجود آمدن یک loop نامحدود در شبکه می شود. اگر در همان LAN پروتکل STP را فعال کنید، سوئیچ ها برخی از پورت ها را بلاک می کنند و اجازه نمی دهند اطلاعات از آن پورت ها عبور کنند.
پروتکل STP با توجه به دو معیار پورت ها را برای بلاک کردن انتخاب می کند: • تمامی deviceهای موجود در LAN بتوانند با هم ارتباط برقرار کنند. درواقع STP تعداد پورت های کمی را بلاک می کند تا LAN به چند بخش که نمی توانند با هم ارتباط برقرار کنند، تقسیم نشود. • Frame ها بعد از مدتی drop می شوند و به طور نامحدود در loop قرار نمی گیرند. پروتکل STP تعادلی را در شبکه به وجود می آورد بطوریکه frame ها به هر کدام از device ها که لازم باشد می رسند بدون اینکه مشکلات loop به وجود آید. پروتکل STP با چک کردن هر interface قبل از اینکه از طریق آن اطلاعات ارسال کند، از به وجود آمدن loop جلوگیری می کند. در این روند چک کردن اگر آن پورت داخل VLAN خود در وضعیت STP forwarding باشد، از آن پورت در حالت عادی استفاده می کند، اما اگر در وضعیت STP blocking باشد، ترافیک تمام کاربران را بلاک می کند و هیچ ترافیکی در آن VLAN را از آن پورت عبور نمی دهد. توجه کنید که وضعیت STP یک پورت، اطلاعات دیگر مربوط به پورت را تغییر نمی دهد. برای مثال با تغییر وضعیت خود تغییری در وضعیت trunk/access و connected/notconnect ایجاد نمی کند. وضعیت STP یک مقدار جدا از وضعیت های قبلی دارد و اگر در حالت بلاک باشد پورت را از پایه غیر فعال می کند.
نیاز به پروتکل STP پروتکل STP از وقوع سه مشکل رایج در LANهای Ethernet جلوگیری می کند. در نبود پروتکل STP ، بعضی از frame های Ethernet برای مدت زیادی (ساعت ها، روز ها و حتی برای همیشه اگر deviceهای LAN و لینک ها از کار نیوفتند) در یک loop داخل شبکه قرار می گیرند. سوئیچ های سیسکو به طور پیش فرض پروتکل STP را اجرا می کنند. توصیه می کنیم پروتکل STP را تا زمانی که تسلط کامل به آن ندارید، غیر فعال نکنید.
اگر یک frame درloop قرار بگیرد Broadcast storm به وجود می آید. Broadcast storm زمانی به وجود می آید که هر نوعی از frameهای Ethernet (مانند multicast frame،broadcast frame و unicast frameهایی که مقصدشان مشخص نیست) در loop بی نهایت داخل LAN قرار بگیرند. Broadcast stormها می توانند لینک های شبکه را با کپی های به وجود آمده از یک frame اشباع کنند و باعث از بین رفتن frameهای مفید شوند، و نیز با توجه به بار پردازشی مورد نیاز برای پردازش broadcast frameها، تاثیر قابل ملاحظه ای روی عملکرد deviceهای کاربران دارند. تصویر 1-2 یک مثال ساده از Broadcast storm را نشان می دهد که در آن سیستمی که Bob نام دارد یک broadcast frame ارسال می کند. خط چین ها نحوه ارسال frameها توسط سوئیچ ها را در نبود STP نمایش می دهند.
در تصویر 1-2، frameها در جهت های مختلفی می چرخند، برای ساده تر شدن مثال فقط در یک جهت آنها را نمایش داده ایم.
در مفاهیم سوئیچ، سوئیچ ها در ارسال کردن broadcast farmeها، frameها را به تمام پورت ها به جز پورت فرستنده آن frame، ارسال می کنند. در تصویر 1-2، سوئیچ SW3، frame را به سوئیچ SW2 ارسال می کند، سوئیچ SW2 آن را برای سوئیچ SW1 ارسال می کند، سوئیچ SW1 نیز آن را برای SW3 ارسال می کند و به همین ترتیب این frame به سوئیچ SW2 ارسال می شود و داخل یک loop می چرخد. زمانی که یک Broadcast storm اتفاق می افتد، frame ها مانند مثال بالا به چرخیدن ادامه می دهند تا زمانی که تغییراتی به وجود آید (شخصی یکی از پورت ها را خاموش کند، سوئیچ را reload کند یا کاری کند که loop از بین برود). Broadcast storm همچنین باعث به وجود آمدن مشکل نا محسوسی به نام MAC table instability یا ناپیوستگی جدول مک می شود. MAC table instability بدین معنا است که جدول مک آدرس پیوسته در حال تغییر کردن می باشد، و علت آن این است کهframe هایی با مک آدرس یکسان از پورت های مختلفی وارد سوئیچ ها می شوند. به مثال زیر توجه کنید: در تصویر 1-2 در ابتدا سوئیچ SW3 مک آدرس باب را که از طریق پورت Fa0/13 وارد سوئیچ شده، به جدول مک آدرس خود اضافه می کند: 0200.3333.3333 Fa0/13 VLAN 1 حالا فرایند switch learning را در نظر بگیرید در زمانی که frame در حال چرخش از سوئیچSW3 به سوئیچ SW2 ، سپس به سوئیچ SW1 و بعد از آن از طریق پورت G0/1 وارد سوئیچ SW3 می شود. سوئیچ SW3 می بیند که مک آدرس مبداء 0200.3333.3333 می باشد و از پورت G0/1 وارد سوئیچ شده است، جدول مک آدرس خود را به روز می کند: 0200.3333.3333 G0/1 VLAN 1 در این مورد سوئیچ SW3 هم دیگر نمی تواند به درستی frameها را به مک آدرس باب برساند. اگر در این حالت یک frame (خارج از frameهایی که در داخل loop افتاده اند) به سوئیچ SW3 برسد که مقصد آن باب باشد، سوئیچ SW3 اشتباها frame را روی پورت G0/1 به سوئیچ SW1 ارسال می کند، که این موضوع ترافیک زیادی را به وجود می آورد. سومین مشکلی که Frame های در حال چرخش در یک broadcast storm ایجاد می کنند این است که کپی های مختلفی از یک frame به دست گیرنده می رسد. در تصویر 1-2 فرض کنید که باب یک frame را برای لاری ارسال کند در حالی که هیچ کدام از سوئیچ ها مک آدرس لاری را نمی دانند. سوئیچ ها frameها را به صورت unicast هایی که مک آدرس مقصدشان مشخص نیست، ارسال می کنند. زمانی که باب یک frame که مک آدرس مقصدش لاری است را ارسال می کند، سوئیچSW3 یک کپی از آن را به سوئیچ های SW1 و SW2 ارسال می کند. سوئیچ های SW1 و SW2 نیز frame را broadcast می کنند، این کپی ها باعث می شود که آن frame در داخل یک loop قرار گیرد. سوئیچ SW1 همچنین یک کپی از frame را به پورت Fa0/11 برای لاری ارسال می کند. در نتیجه لاری کپی های مختلفی از آن frame را دریافت می کند، که می تواند باعث از کار افتادن برنامه ای در سیستم لاری و یا مشکلات شبکه ای شود.
جدول زیر خلاصه ای از سه مشکل اساسی در شبکه ای که دارای redundancy است و STP در آن اجرا نمی شود را نشان می دهد:
پروتکل (STP (IEEE 802.1D دقیقا چه کار می کند؟ پروتکلSTP با قرار دادن هر یک از پورت های سوئیچ در وضعیت های forwarding و blocking از به وجود آمدن loop جلوگیری می کند. پورت هایی که در وضعیت forwarding هستند به صورت عادی فعالیت می کنند، frameها را ارسال و دریافت می کنند. اما پورت هایی که در وضعیت blocking قرار دارند به جز پیام های مربوط به پروتکل STP (و برخی دیگر از پیام هایی که برای پروتکل ها استفاده می شوند) ، هیچ frame دیگری را پردازش نمی کنند. این پورت ها frameهای کاربران را ارسال نمی کنند، مک آدرس frameهای ورودی را ذخیره نمی کنند و frameهای دریافتی از کاربران را نیز پردازش نمی کنند. تصویر 2-2 راه حل استفاده از پروتکل STP (قرار دادن یکی از پورت های سوئیچ SW3 در وضعیت blocking) در مثال پیشین را نمایش می دهد:
همانطور که در مراحل زیر نشان داده شده، زمانی که باب یک broadcast را ارسال می کند، دیگر loop به وجود نمی آید: • مرحله اول: باب frame را به سوئیچ SW3 ارسال می کند. • مرحله دوم: سوئیچ SW3 این frame را فقط به سوئیچ SW1 ارسال می کند، دیگر به سوئیچ SW2 ارسال نمی شود چون پورت G0/2 در وضعیت blocking قرار دارد. • مرحله سوم: سوئیچ SW1 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند. • مرحله چهارم: سوئیچ SW2 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند. • مرحله پنجم: سوئیچ SW3 به صورت فیزیکی یک frame را دریافت می کند، اما frame دریافتی از SW2 را به دلیل اینکه پورت G0/2 در سوئیچ SW3 در وضعیت blocking قرار دارد، نادیده می گیرد. با استفاده از توپولوژی STP در تصویر 2-2، سوئیچ ها از لینک موجود بین SW2 و SW3 برای انتقال ترافیک استفاده نمی کنند. با این حال، اگر لینک بین SW3 و SW1 دچار مشکل شود، پروتکل STP پورت G0/2 را از وضعیت blocking به وضعیت forwarding تغییر می دهد و سوئیچ ها می توانند از آن لینکredundant استفاده کنند. در این موقعیت ها پروتکل STP با انجام فرایند هایی متوجه تغییرات در توپولوژی شبکه می شود و تشخیص می دهد که پورت ها نیاز به تغییر در وضعیتشان دارند و وضعیت آن ها را تغییر می دهد.
سوالاتی که احتمالا زهن شما را نیز مشغول کرده: پروتکل STP چگونه پورت ها را برای تغییر وضعیت انتخاب می کند و چرا این کار را می کند؟ چگونه وضعیت blocking را برای بهره مندی از مزایای لینک های redundant، به وضعیت forwarding تغییر می دهد؟ در ادامه به این سوالات پاسخ خواهیم داد. پروتکل STP چگونه کار می کند؟ الگوریتم STP یک درخت پوشا (spanning tree) از پورت هایی که frameها را ارسال می کنند تشکیل می دهد. این ساختار درختی، مسیرهایی را برای رسیدن لینک های ethernet به هم مشخص می کند. (مانند پیمودن یک درخت واقعی که از ریشه درخت شروع می شود و تا برگ ها ادامه دارد) توجه: STP قبل از اینکه در سوئیچ های LAN استفاده شود، در Ethernet bridgeها به کار رفته بود. STP از فرایندی که بعضا spanning-tree algorithm)STA) نامیده می شود، استفاده می کند که در آن پورت هایی که باید در وضعیت forwarding قرار بگیرند را انتخاب می کند. STP پورت هایی که برای forwarding انتخاب نشدند را در وضعیت blocking قرار می دهد. در واقع پروتکل STP پورت هایی که در ارسال کردن اطلاعات باید فعال باشند را انتخاب می کند و پورت های باقی مانده را در وضعیت blocking قرار می دهد. پروتکل STP برای قرار دادن پورت ها در حالت forwarding از سه مرحله استفاده می کند: • پروتکل STP یک سوئیچ را به عنوان root انتخاب می کند و تمام پورت های فعال در آن سوئیچ را در وضعیت forwarding قرار می دهد. • در هر کدام از سوئیچ های nonroot (همه ی سوئیچ ها به جز root)، پورتی که کمترین هزینه را برای رسیدن به سوئیچ root دارد (root cost)، به عنوان root port(RP) انتخاب می کند و آن ها را در وضعیت forwarding قرار می دهد. • تعداد زیادی سوئیچ می توانند به یک بخش از Ethernet متصل شوند، اما در شبکه های مدرن، معمولا دو سوئیچ به هر لینک (بخش) متصل می شوند. در بین سوئیچ هایی که به یک لینک مشترک متصل هستند، پورت سوئیچی که root cost کمتری دارد در وضعیت forwarding قرار می گیرد. این سوئیچ ها را designated switch می نامند و پورت هایی که در وضعیت forwarding قرار گرفته را designated port)DP) می نامند. باقی پورت ها در وضعیت blocking قرار می گیرند.
خلاصه ای از علت قرار گرفتن پورت ها در وضعیت های blocking و forwarding توسط پورتکل STP
Bridge و Hello BPDU فرایند STA با انتخاب یک سوئیچ به عنوان root شروع می شود. برای اینکه روند انتخاب را بهتر متوجه شوید، شما باید با مفهوم پیام هایی که بین سوئیچ ها تبادل می شود به خوبی آشنا شوید و با فرمت شناساگری که برای شناسایی هر سوئیچ استفاده می شود آشنا باشید. (STP bridge ID (BID یک مقدار 8 بایتی برای شناسایی هر سوئیچ می باشد. Bridge ID به دو بخش 2 بایتی که مشخص کننده اولویت و حق تقدم است و 6 بایتی که system ID نامیده می شود و همان مک آدرس هر سوئیچ است، تقسیم می شود. استفاده از مک آدرس این اطمینان را می دهد که bridge ID هر سوئیچ یکتا خواهد بود. پیام هایی که برای تبادل اطلاعات مربوط به پروتکل STP بین سوئیچ ها استفاده می شود، bridge protocol data units )BPDU) نام دارد. رایج ترین BPDU ، که hello BPDU نام دارد، تعدادی از اطلاعات که شامل BID سوئیچ ها نیز می شود را لیست می کند و ارسال می کند. با استفاده از BID درج شده روی هر پیام، سوئیچ ها می توانند تشخیص دهند که هر پیام Hello BPDU از طرف کدام سوئیچ است. جدول زیر اطلاعات کلیدی مربوط به Hello BPDU را نشان می دهد:
انتخاب سوئیچ root سوئیچ ها با استفاده از BIDهای موجود در پیام های BPDU، سوئیچ root را انتخاب می کنند. سوئیچی که عدد BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. با توجه به اینکه بخش اول عدد BID مقدار اولویت می باشد، سوئیچی که مقدار اولویت پایین تری داشته باشد به عنوان سوئیچ root انتخاب می شود. برای مثال اگر سوئیچ های اول و دوم به ترتیب دارای اولویت های 4096 و 8192 باشند، بدون در نظر گرفتن مک آدرس سوئیچ ها که در به وجود آمدن BID هر سوئیچ موثر است، سوئیچ اول به عنوان سوئیچ root انتخاب خواهد شد. اگر مقدار اولویت دو سوئیچ برابر شد، سوئیچی که مک آدرس آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. در این حالت به علت یکتا بودن مک آدرس، حتما یک سوئیچ انتخاب خواهد شد. پس اگر مقدار اولویت دو سوئیچ برابر باشد و مک آدرس آنها 0200.0000.0000 و 0911.1111.1111 باشد، سوئیچی که دارای مک آدرس 0200.0000.0000 است، به عنوان سوئیچ root انتخاب می شود. مقدار اولویت مضربی از 4096 است و به صورت پیش فرض برای همه ی سوئیچ ها مقدار 32768 را دارد. از آنجایی که مک آدرس سوئیچ ها معیار مناسبی برای انتخاب سوئیچ root نمی باشد بهتر است به صورت دستی مقدار اولویت را تغییر دهیم تا سوئیچی که می خواهیم به عنوان سوئیچ root انتخاب شود. در فرایند انتخاب سوئیچ root، سوئیچ ها از طریق فرستادن پیام های Hello BPDU که BID خود را در این پیام ها به عنوان root BID قرار داده اند، سعی می کنند خود را به عنوان سوئیچ root به سوئیچ های مجاور خود معرفی کنند. اگر یک سوئیچ پیامی را دریافت کند که BID کمتری نسبت به BID خودش داشته باشد، آن سوئیچ دیگر خود را به عنوان سوئیچ root معرفی نمی کند، به جای آن شروع به ارسال پیام دریافتی که دارای BID بهتری است می کند (مانند رقابت های انتخاباتی که یک نامزد به نفع نامزد هم حزبش که موقعیت بهتری دارد، از رقابت در انتخابات خارج می شود). در نهایت تمامی سوئیچ ها به یک نظر نهایی می رسند که کدام سوئیچ BID کمتری دارد و همه آن سوئیچ را به عنوان سوئیچ root انتخاب می کنند. توجه : در مقایسه دو پیام Hello با هم، پیامی که BID کمتری دارد، superior Hello و پیامی که BID بیشتری دارد، inferior Hello نام دارد.
تصویر 3-2 آغاز فرایند انتخاب سوئیچ root را نشان می دهد، در ابتدای این فرایند SW1 همانند باقی سوئیچ ها خود را به عنوان سوئیچ root معرفی می کند. SW2 پس از دریافت Hello مربوط به SW1 متوجه می شود که SW1 شرایط بهتری را برای root بودن دارد، پس شروع به ارسال Hello دریافتی از SW1 می کند. در این حالت سوئیچ SW1 خود را به عنوان root معرفی می کند و SW2 نیز با آن موافقت می کند اما سوئیچ SW3 هنوز سعی می کند که خود را به عنوان سوئیچ root معرفی کند و Hello BPDUهای خود را ارسال می کند.
دو نامزد هنوز باقی ماندند:SW1 و SW3. از آنجایی که SW1 مقدار BID کمتری دارد، SW3 پس از دریافت BPDU مربوط به SW1، SW1 را به عنوان سوئیچ root می پذیرد و به جای BPDU خود، BPDU دریافتی از SW1 را به سوئیچ های مجاور ارسال می کند.
پس از اینکه فرایند انتخاب تکمیل شد، فقط سوئیچ root به تولید پیام های Hello BPDU ادامه می دهد. سوئیچ های دیگر این پیام ها را دریافت می کنند و BID فرستنده و root costرا تغییر می دهند و به باقی پورت ها ارسال می کنند. در تصویر 4-2، در قدم اول سوئیچ SW1 پیام های Hello را ارسال می کند، در قدم دوم سوئیچ های SW2 و SW3 به صورت مستقل تغییرات را روی پیام های دریافتی اعمال می کنند و آن ها را روی پورت های خود ارسال می کنند. برای اینکه بخواهیم مقایسه BID را خلاصه کنیم، BID را به بخش های تشکیل دهنده ان تقسیم می کنیم، سپس به صورت زیر مقایسه می کنیم: • اولویتی که کمترین مقدار را دارد • اگر مقدار اولویت آن ها برابر باشد، سوئیچی که مک ادرسش کمترین مقدار را دارد
انتخاب Root Port برای هر سوئیچ در مرحله ی بعدی، پس از انتخاب سوئیچ root، پروتکل STP برای سوئیچ های nonroot (همه ی سوئیچ ها به جز سوئیچ root) یک root port )RP) انتخاب می کند. RP هر سوئیچ، پورتی است که کمترین هزینه را برای رسیدن به سوئیچ root دارد. احتمالا عبارت هزینه برای همه ی ما در انتخاب مسیر بهتر، روشن و مشخص باشد. اگر به دیاگرام شبکه ای که در آن سوئیچ root و هزینه ارسال اطلاعات روی هر پورت مشخص باشد توجه کنید، می توانید هزینه برقراری ارتباط با سوئیچ root را برای هر پورت به دست آورید. توجه کنید که سوئیچ ها برای به دست آوردن هزینه برقراری ارتباط با سوئیچ root، از دیاگرام شبکه استفاده نمی کنند، صرفا استفاده از آن برای درک این موضوع به ما کمک می کند. تصویر 5-2 همان سوئیچ های مثال پیشین که در آن سوئیچ root و هزینه ی رسیدن به سوئیچ root را برای پورت های سوئیچ SW3 نشان می دهد.
سوئیچ SW3 برای ارسال frameها به سوئیچ root، می تواند از دو مسیر استفاده کند: مسیر مستقیم که از پورت G0/1 خارج می شود و به سوئیچ root می رسد، و مسیر غیر مستقیمی که از پورت G0/2 خارج می شود و از طریق SW2 به سوئیچ root می رسد. برای هر یک از پورت ها، هزینه ی رسیدن به سوئیچ root برابر است با مجموع هزینه ی خروج از پورت هایی که frame ارسالی، برای رسیدن به سوئیچ root از آن ها عبور می کند (در این محاسبه، هزینه ورود آن frame به پورت ها حساب نمی شود). همانطور که مشاهده می کنید، مجموع هزینه ی مسیر مستقیم که از پورت G0/1 سوئیچ SW3 خارج می شود برابر 5 است، و مسیر دیگر دارای مجموع هزینه ی 8 می باشد. از آنجایی که پورت G0/1، بخشی از مسیری است که هزینه ی کمتری برای رسیدن به سوئیچ root دارد، سوئیچ SW3 این پورت را به عنوان root port انتخاب می کند. سوئیچ ها با سپری کردن فرایندی متفاوت به همین نتیجه می رسند. آنها هزینه خروج از پورت خود را به root cost موجود در Hello BPDU ورودی از همان پورت اضافه می کنند و هزینه رسیدن به سوئیچ root از طریق آن پورت را به دست می آورند. هزینه خروج از هر پورت در پروتکل STP یک عدد صحیح (integer) می باشد که به هر پورت در هر VLAN اختصاص می یابد، تا پروتکل STP با استفاده از این مقیاس اندازه گیری بتواند تصمیم بگیرد که کدام پورت را به توپولوژی خود اضافه کند. در این فرایند سوئیچ ها، root cost سوئیچ های مجاور را که از طریق Hello BPDUهای دریافتی به دست می آورند، بررسی می کنند.
تصویر 6-2 یک مثالی از چگونگی محاسبه بهترین root cost و سپس انتخاب آن به عنوان root port را نشان می دهد. اگر به تصویر توجه کنید، خواهید دید که سوئیچ root پیام هایی(Hello) که root cost آن ها برابر صفر می باشد را ارسال می کند. هزینه رسیدن به سوئیچ root از طریق پورت های سوئیچ root برابر با صفر است. در ادامه به سمت چپ تصویر توجه کنید که سوئیچ SW3، root cost دریافتی از طریق SW1 را (که برابر صفر است) با هزینه ی خروج از پورت G0/1 که آن Hello را دریافت کرده (5) جمع می کند و هزینه ارسال اطلاعات از طریق این پورت را به دست می آورد. در سمت راست تصویر، سوئیچ SW2 متوجه شده که root cost آن برابر با 4 است. پس زمانی که SW2 یک Hello برای SW3 ارسال می کند، مقدار root cost آن را 4 قرار می دهد. در سمت دیگرهزینه ارسال اطلاعات از طریق پورت G0/2 در سوئیچ SW3 برابر 4 است، از اینرو سوئیچ SW3 این دو مقدار را با هم جمع می کند و به این نتیجه می رسد که هزینه ی رسیدن به سوئیچ root از طریق پورت G0/2 برابر 8 است. با توجه به نتایج به دست آمده از آنجایی که پورت G0/1 نسبت به پورت G0/2 هزینه ی کمتری برای رسیدن به سوئیچ root دارد، پس سوئیچ SW3 پورت G0/1 را به عنوان RP انتخاب می کند. سوئیچ SW2 نیزبا گذراندن همین فرایند پورت G0/2 را به عنوان RP انتخاب می کند. سپس تمام سوئیچ ها، root port های خود را در وضعیت forwarding قرار می دهند.
انتخاب Designated Port در هر LAN segment (پورت کاندید) پس از انتخاب سوئیچ root، در سوئیچ های nonroot، تمام root portها را مشخص کردیم و آنها را در وضعیت forwarding قرار دادیم. مرحله نهایی پروتکل STP برای تکمیل توپولوژی STP، انتخاب designated port در هر LAN segment است. در هر بخش(segment) از LAN، پورت سوئیچی که کمترین root cost را دارد و به آن بخش از LAN متصل است Designated port )DP) نامیده می شود. زمانی که یک سوئیچ nonroot می خواهد که یک Hello را ارسال کند، هزینه رسیدن به سوئیچ root را در root cost آن پیام قرار می دهد و ارسال می کند. دراینصورت پورت سوئیچی که کمترین هزینه را برای رسیدن به root دارد، در میان تمام سوئیچ هایی که به آن بخش متصل هستند، به عنوان DP در آن بخش شناخته می شود. در این مرحله اگر هزینه سوئیچ ها برای رسیدن به سوئیچ root برابر بود، پورت سوئیچی که BID کمتری دارد را به عنوان DP انتخاب می کنیم. در تصویر 4-2 پورت G0/1 در سوئیچ SW2 که به سوئیچ SW3 متصل است، به عنوان DP انتخاب می شود. پس از انتخاب DPها، تمام آن ها را در وضعیت forwarding قرار می دهیم. مثالی که در تصاویر 3-2 تا 6-2 به نمایش گذاشته شد، تنها پورتی که نیازی ندارد تا در وضعیت forwarding قرار بگیرد، پورت G0/2 در سوئیچ SW3 است. درنهایت فرایند پروتکل STP کامل شد و جدول زیر وضعیت نهایی هر پورت و علت قرار گرفتن در آن وضعیت را نشان می دهد:
به صورت خلاصه اگر بخواهیم توضیح دهیم، در فرایند اجرای پروتکل STP: • در قدم اول سوئیچ root انتخاب می شود که ابتدا تمام سوئیچ ها سعی می کنند خود را به عنوان root معرفی کنند، سپس سوئیچی که رقم BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب خواهد شد. • در قدم دوم برای هر سوئیچ، پورتی که کمترین هزینه برای رسیدن به سوئیچ root دارد را به عنوان root port انتخاب می شود. سپس همه ی root portها را در وضعیت forwarding قرار می گیرند. • در قدم سوم پورت های کاندید انتخاب می شوند و در وضعیت forwarding قرار می گیرند. در نهایت پورت هایی که وضعیتشان مشخص نشده در وضعیت blocking قرار می گیرند.
vSphere 6.7 معرفی شد ! و vCenter Server Appliance اکنون به صورت پیش فرض deploy میشود . این نسخه پر از پیشرفت های جدید برای vCenter Server Appliance در تمام زمینه ها است . اکنون مشتریان ابزارهای بیشتری برای کمک به مانیتورینگ دارند. vSphere Client) HTML5) پر از جریان های کاری جدید و نزدیک به ویژگی های آینده نگرانه است. معماری vCenter Server Appliance به سمت مدل پیاده سازی ساده تر حرکت می کند. همچنین File-Based backup درونی که با یک scheduler همراه است . و رابط گرافی کاربر vCenter Server Appliance که از تم Clarity پشتیبانی میکند . اینها فقط بخشی از ویژگی های جدید در vCenter Server Appliance 6.7 هستند .این مقاله به جزئیات بیشتری از پیشرفت های ذکر شده در بالا وارد خواهد شد.
Lifecycle
Install
یکی از تغییرات مهم در vCenter Server Appliance، ساده سازی معماری است . در گذشته تمام سرویس های vCenter Server در یک instance قرار داشت . اکنون میتوانیم دقیقا همان کار را با vCenter Server Appliance 6.7 انجام دهیم . vCenter Server با Embedded PSC به همراه Enhanced Linked Mode ارائه میشود. بیایید نگاهی به مزایایی که این مدل پیاده سازی ارائه می دهد بیندازیم:
برای ایجاد high availability نیازی به load balancer نیست و به طور کامل از native vCenter Server High Availability پشتیبانی میکند .
حذف SSO Site boundary ، پیاده سازی را با انعطاف پذیری بیشتری همراه کرده است.
پشتیبانی از حداکثر مقیاس vSphere
میتوانید تا 15 دامنه برای استفاده از vSphere Single Sign-On اضافه کنید
تعداد گره ها را برای مدیریت و نگهداری کاهش می دهد
Migrate
vSphere 6.7 همچنین آخرین نسخه برای استفاده از vCenter Server برای ویندوز را داراست ، که در گذشته نبود. مشتریان می توانند با ابزار داخلی Migration Tool به vCenter Server Appliance مهاجرت کنند. در vSphere 6.7 می توانید نحوه وارد کردن داده های تاریخی و عملکرد را در هنگام Migrate انتخاب کنیم.
Deploy & import all data
Deploy & import data in the background
مشتریان همچنین زمان تخمین زده شده از مدت زمانی که طول میکشد تا Migrate انجام شود را میبینند . زمان تخمین زده شده بر اساس اندازه داده های تاریخی و عملکرد در محیط شما متفاوت است. در حالی که مشتریان میتوانند در زمان وارد کردن داده ها در پس زمینه عملیات را pause یا resume کنند . این قابلیت جدید در رابط مدیریت vSphere Appliance موجود است. یکی دیگر از بهبود ها پشتیبانی از پورت های custom در زمان عملیات Migrate است . مشتریانی که پورت پیش فرض Windows vCenter Server را تغیرداده اند دیگر مسدود نمیشوند.
Upgrade
vSphere 6.7 فقط از upgrades یا migrations از vSphere 6.0 یا 6.5پشتیبانی میکند . vSphere 5.5 مسیر مستقیم بروزرسانی به vSphere 6.7 ندارد. مشتریانی با vSphere 5.5 باید ابتدا به vSphere 6.0 یا 6.5بروزرسانی کنند و بعد به vSphere 6.7 بروزرسانی انجام دهند . هم چنین vCenter Server 6.0 یا 6.5 که هاست ESXi 5.5 دارند نمیتوانند بروزرسانی یا migrations انجام دهند ، تا زمانی که حداقل به نسخه ESXi 6.0 یا بالاتر بروز کنند .
یادآوری : vSphere 5.5 در تاریخ September 19, 2018. به پایان پشتیبانی general میرسد.
نظارت و مدیریت
سرمایه گذاری بسیاری جهت بهبود وضعیت Monitoring در vCenter صورت گرفته است. ما شروع این بهبود را از VSphere 6.5 دیدیم و در VSphere 6.7 شاهد چندین پیشرفت جدید نیز می باشیم. بیاییم به پنل مدیریتی vSphere VAMI بر روی پورت 5480 متصل شویم. اولین چیزی که مشاهده می کنیم این است که VAMI به محیط کاربری Clarity آپدیت شده است. ما همچنین می بینیم که در مقایسه با vSphere 6.5 تعدادی تب جدید در پنل سمت چپ قرار گرفته است. یک تب اختصاصی برای مانیتورینگ قرار داده شده است، که در آن ما می توانیم میزان مصرف و وضعیت سی پی یو، رم، شبکه و Database ها را مشاهده نمائیم. بخش جدیدی در تب مانیتورینگ تحت عنوان Disks قرار داده شده است. مشتریان می توانند پارتیشن هر یک از دیسک های vCenter سرور، فضای باقیمانده و مصرف شده را مشاهده نمایند.
بکآپ های File-Based اولین بار در vSphere 6.5 در زیرمجموعه تب summary قرار گرفتند و اکنون تب مخصوص خود را دارند. اولین گزینه ی در دسترس در تب بکآپ تنظیم scheduler می باشد. مشتریان می توانند بکآپ های vCenter را برنامه ریزی زمانی نموده و انتخاب نمایند که چه تعداد بکاپ حفظ گردد. یک قسمت جدید دیگر در بکـاپ های File-Based ، Activities می باشد. هنگام که یک job بکآپ کامل می شود اطلاعات با جزییات این رویداد در قسمت Activity به عنوان گزارش قرار می گیرد. ما نمی توانیم بدون در نظر گرفتن Restore کردن در مورد بکآپ صحبت کنیم. روند کاری Restore ، اکنون شامل مرورگر آرشیو بکآپ ها می باشد. این مرورگر تمام بکاپ های شما بدون نیاز به دانستن مسیر های بکآپ نشان می دهد.
تب جدید دیگر Services می باشد که در VAMI قرار گرفته است. زمانی درون vSphere Web Client بود و اکنون در VAMIبرای عیب یابی out of band هست . تمام سرویس های vCenter Server Appliance ، نوع راه اندازی، سلامت و وضعیت آنها در اینجا قابل مشاهده است . ما همچنین گزینه ای برای شروع، متوقف کردن و راه اندازی مجدد این سرویس ها در صورت نیاز داریم. در حالی که تب های Syslog و Update در VAMI جدید نیستند ، اما در این زمینه ها پیشرفت نیز وجود دارد. Syslog اکنون تا سه syslog forwarding targets پشتیبانی میکند. پیش از این vSphere 6.5 فقط از یکی پشتیبانی میکرد . اکنون انعطاف پذیری بیشتری در پچ کردن و به روز رسانی وجود دارد. از برگه Update، اکنون گزینه ای برای انتخاب اینکه کدام پچ یا به روز رسانی اعمال شود وجود دارد. مشتریان همچنین اطلاعات بیشتری از جمله نوع ، سطح لزوم و همچنین در صورت نیاز به راه اندازی مجدد را مشاهده میکنند. با باز کردن پنجره نمایش پچ یا به روز رسانی ، اطلاعات بیشتر در مورد آنچه که شامل است نمایش داده خواهد شد و در نهایت ، اکنون می توانیم پچ یا به روز رسانی را از VAMI نصب واجرا کنیم. این قابلیت قبلا تنها از طریق CLI در دسترس بود.
(vSphere client(HTML5
از ویژگی هایی که در vSphere 6.7 روی آن سرمایه گذاری قابل توجه ای شده است VSphere client میباشد. VMware با معرفی vSphere 6.5 نسخه vSphere Client (HTML5) را معرفی کرد که در vCenter server Application از قابلیت های جزئی برخوردار بود. تیم فنی vSphere به سختی بر روی آن کار می کنند تا از ویژگی های بیشتری پشتیبانی نماید و بر اساس باز خورد مشتریان عملکرد و ویژگی آن بهبود چشم گیری یافته است. برخی از ویژگی های جدیدی که در نسخه vSphere client به روز شده شامل موارد زیر است:
vSphere Update Manager
Content Library
vSAN
Storage Policies
Host Profiles
vDS Topology Diagram
Licensing
بعضی از به روز رسانی هایی که در بالا ذکر شده دارای تمام ویژگی های عملکردی نیست . VMware به روز رسانی های vSphere Client را ادامه خواهد داد تا با ارائه (patch/update) این موارد بهبود یابد.
اکنون در منوی مدیریت ، گزینه های PSC بین دو زبانه تقسیم می شوند. Certificate management دارای برگه خاص خود است و تمام تنظیمات مدیریتی دیگر زیر برگه configuration هستند.
CLI Tools
CLI در vCenter Server Appliance 6.7 نیز دارای برخی از پیشرفت های جدیدی است . اولین پیشرفت Repoint با استفاده cmsso-util است. در حالی که این یک ویژگی جدید نیست ، این قابلیت در vSphere 6.5 موجود نبود و در Vsphere 6.7 دوباره اجرایی شده است . ما در مورد vCenter Server Appliance که به صورت مجزا با SSO Vsphere هست صحبت می کنیم.
کاربران می توانند vCenter Server Appliance خود را از طریق vSphere SSO domains ، ریپوینت کنند. قابلیت Repoint فقط از external deployments که vSphere 6.7 دارد پشتیبانی میکند . قابلیت Repoint داخلی ویژگی pre-check دارد که من ترجیح میدهم استفاده نکنم ! ویژگی pre-check دو دامنه SSO را با هم مقایسه میکند و لیست اختلافات آنها را در یک فایل JSON ذخیره میکند. این فرصتی است که هر یک از این اختلافات را قبل از اجرای domain repoint tool حل کنید. ابزار repoint میتواند لایسنس ها ، تگ ها ، دسته بندی ها و permissions ها را از یک دامنه vSphere SSO به دیگری منتقل کند .
یکی دیگر از بهبود های CLI ، استفاده از cli installer ، برای مدیریت lifecycle در vCenter Server Appliance است .
vCenter Server Appliance ISO معمولا با JSON template examples همراه است. این JSON templates راهی برای اطمینان از سازگاری در طول نصب، ارتقاء و migrate است . معمولا ما باید یک JSON template را از cli installer در همان زمان و به روش صحیح اجرا کنیم . این پیاده سازی دستی per-node در حال حاضر با عملیات دسته ای ، از گذشته باقی مانده است. به عملیات دسته ای چندین JSON templates می تواند به طور متوالی از یک دایرکتوری بدون مداخله اجرا شود. برای تایید الگوها در دایرکتوری که شامل توالی است از گزینه pre-checks استفاده کنید.
جمع بندی
خب ، vCenter Server Appliance 6.7 اکنون استاندارد جدیدی برای اجرای vCenter Server است . ما سعی خواهیم کرد چند مورد از ویژگی های برجسته این نخسه را بررسی کنیم .
با منتشر شدن vSphere 6.7 به عموم مردم، طبیعی است که بحث های زیادی در اطراف ارتقا به آن وجود دارد. چگونه می توانیم ارتقا دهیم یا حتی چرا باید ارتقاء دهیم از سوالات پرطرفدار اخیرا بوده است. در این پست من این سؤالات و همچنین ملاحظاتی را که باید قبل از ارتقاء vSphere بررسی شود را پوشش خواهم داد. این ارتقاء دادن یک کار ترسناک یا غم انگیز نیست .
چرا ؟
خب بیاید با چرا شروع کنیم . چرا باید به vSphere 6.7 ارتقاء دهیم ؟ با VMware vSphere 6.7 سرمایه گذاری خود را در VMware تقویت می کنید. از آنجا که vSphere در قلب SDDC VMware قرار دارد ، ارائه و بنیاد ساختار اساسی برای استراتژی cloud شما ارائه میکند ، ارتقاء دادن باید اولویت اصلی ذهن شما باشد اما تنها پس از دقت و توجه به ویژگی ها و مزایا و اینکه چگونه آنها را به نیازهای کسب و کار بر گردانید. شاید تیم های امنیتی برای یکپارچگی دقیق تر برای هر دو سیستم Hypervisor و سیستم عامل مهمان درخواست کرده باشد بنابراین استفاده از vSphere 6.7 و پشتیبانی از Trusted Platform Module (TPM) 2.0 یا Virtual TPM 2.0 اکنون مورد نیاز است. اگر امنیت نباشد ، شاید انعطاف پذیری برنامه ای در vSphere 6.7 که آن پیشرفت های تکنولوژی NVIDIA GRID ™ vGPU ، اجازه می دهد تا مشتریان قبل از vMotion آنرا را متوقف کند و از VM های فعال شده با vGPU خلاص شوند. صرف نظر از خود ویژگی ها، مهم این است که اطمینان حاصل شود ویژگی های مورد نیاز به طور مناسب به شرایط کسب و کار برمی گردند.
چرا
یکی دیگر از دلایل اینکه چرا باید ارتقاء پیدا کنیم به علت پایان پشتیبانی محصول یا کار آن است. اگر قبلا شنیده باشید، VMware vSphere 5.5 به سرعت به پایان عمر خود نزدیک می شود. تاریخ دقیق پایان کلی پشتیبانی برای vSphere 5.5 در روز 19 سپتامبر 2018 است. با در نظر داشتن این موضوع، ارتقاء باید در خط مقدم طرح های شما باشد. اما خبر خوب در مورد پایان سافتن vSphere 5.5 ، این است که VMware پشتیبانی عمومی از vSphere 6.5 را تا پنج سال کامل از تاریخ انتشار آن تا تاریخ 15 نوامبر 2021 گسترش داده است. اگر شما از من بپرسید این نکته بسیار شگفت انگیزی است. نقطه عطف بعدی درک چگونگی به ارتقاء به vSphere 6.5 /6.7 است که مشتریان را قادر می سازد تا مزایای یک راه حل نرم افزاری SDDC که کارآمد و امن است را داشته باشند .
چگونه
خب اجازه دهید در مورد چگونگی صحبت کنیم. چگونه ارتقا دهیم؟ برای شروع ، VMware انواع بسیاری از مستندات را برای کمک به نصب یا ارتقاء VMware vSphere با استفاده از VMware Docs فراهم می کند. سایت VMware Docs به رابط بسیار ساده تر که شامل قابلیت جستجو بهتر در نسخه ها و همچنین یک گزینه برای ذخیره اسناد در MyLibrary برای دسترسی سریع برای بعد به روز شده است . vSphereCentral یک مخزن غظیم از منابع vSphere است از جمله وبلاگ ها، KB ها، فیلم ها، و walkthroughs ها که برای کمک به مشتریان است تا به سرعت اطلاعات مورد نیاز خود را پیدا کنند. بعدا، هر گونه راه حل VMware که با محیط شما مرتبط باشد را بررسی کنید ، مانند مدیریت بازیابی سایت SRM)، Horizon View Composer) ، یا VMware NSX . قبل از شروع ، همچنین تعیین کنید که آیا تنظیم فعلی شما از معماری جاسازی شده یا خارجی برای SSO / PSC استفاده می کند، به این دلیل که ممکن است مسیر ارتقا شما را تحت تاثیر قرار دهد.
یک عامل کلیدی در کمک به اینکه چگونه به ارتقاء محیط vSphere بپردازد، بررسی در محدوده سازگاری های نسخه میباشد . همه نسخه های vSphere قادر به ارتقا به vSphere 6.7 نیستند. به عنوان مثال، vSphere 5.5 یک مسیر ارتقاء مستقیم را به vSphere 6.7 ندارد. اگر شما در حال حاضر vSphere 5.5 را اجرا می کنید، قبل از ارتقا به vSphere 6.7 ابتدا باید به vSphere 6.0 یا vSphere 6.5 ارتقا دهید. بنابراین قبل از اینکه شما به نصب جدیدترین نسخه vSphere 6.7 ISO خود بپردازید ، یکبار مسیر خود را اینجا انجام دهید و هر محیطی را که ممکن است در نسخه پایین تر از vSphere 6.0 اجرا کنید در نظر داشته باشید. قبل از شروع ارتقاء vSphere 6.7 ، این محیط قدیمی را به یک نسخه سازگار vSphere ارتقا دهید. پس از بحث درباره چگونگی ارتقاء، ما باید به طور طبیعی در مورد برنامه ریزی ارتقاء صحبت کنیم.
یادآوری:روش های پشتیبانی شده برای ارتقاء میزبان های vSphere شما عبارتند از: با استفاده از ESXi Installer، دستور ESXCLI از داخل (ESXi Shell، vSphere Update Manager (VUM و Auto Deploy.
برنامه ریزی
راز ارتقاء موفق با شروع برنامه ریزی شده است. ما درباره نحوه شروع آماده سازی برای ارتقاء vSphere با درک چگونگی و چرایی آن بحث کرده ایم. گام های منطقی بعدی شروع برنامه ریزی است. این جایی است که شما خود را در حال بررسی یافته ها در محیط خود و همچنین جمع آوری فایل های نصب و راه اندازی آنها برای ارتقاء. آماده میکنید . بسیار مهم است که ترتیب و مراحل سایر محصولات VMware را مشخص کنید بنابراین شما کاملا درک می کنید که باید قبل یا بعد از vCenter Server و ESXi باید چه کنید. ارتقاء برخی محصولات غیرمجاز ممکن است نتایج بدی داشته باشد که می تواند یک مشکل را در برنامه ارتقاء شما قرار دهد. برای مشاهده جزئیات بیشتر با بررسی vSphere 6.7 Update Sequence KB Article شروع کنید. در طول برنامه ریزی مشتریان باید تمام محصولات ، نسخه ها و واحدهای تجاری را در نظر بگیرند که ممکن است در طول و یا بعد از ارتقاء تحت تاثیر قرارگیرند. برنامه ریزی باید شامل تست آزمایشگاهی ارتقا باشد تا اطمینان حاصل شود که روند و نتایج را درک کنید. انجام یک بررسی سلامتی vSphere ممکن است بهترین پیشنهادی باشد که میتوانم بدهم . ارزیابی vSphere می تواند به کشف منابع هدر رفته، مشکلات محیطی و حتی مواردی ساده مانند تنظیم نادرست NTP یا DNS کمک کند. در نهایت تمام اطلاعات محاسباتی ، ذخیره سازی ، شبکه ایی و بک آپ های vendors را برای سازگاری با vSphere 6.7 جمع آوری کنید. هیچ چیز بدتر از آن نیست که بعد از ارتقاء محیط خود متوجه شوید که یک rd party vendor3 نسخه سازگار با vSphere را ارائه نکرده باشد.
ملاحظات ارتقاء
برای کمک بیشتر به مشتریان در ارتقاء vSphere ، من مجموعه کاملی از ملاحظات ارتقا را برای کمک به شما در شروع برنامه ارتقاء به vSphere 6.7. جمع آوری کرده ام.
ملاحظات vSphere
از آنجا که vSphere پایه ای برای SDDC است، بسیار مهم است که قابلیت همکاری آن را با نسخه های فعلی نصب شده در پایگاه داده های شما بررسی شود .
An Upgrade from vSphere 5.5 to vSphere 6.7 GA directly is currently not supported
vSphere 6.0 will be the minimum version that can be upgraded to vSphere 6.7
vSphere 6.7 is the final release that requires customers to specify SSO sites.
In vSphere 6.7, only TLS 1.2 is enabled by default. TLS 1.0 and TLS 1.1 are disabled by default.
Due to the changes done in VMFS6 metadata structures to make it 4K aligned, you cannot upgrade a VMFS5 datastore inline or offline to VMFS6, this stands true for vSphere 6.5 & vSphere 6.7. (See KB2147824)
ملاحظات سرور vCenter
(vCenter Server Appliance (VCSA در حال حاضر به طور پیش فرض برای سرور vCenter استفاده می شود. vCenter Servers topology deployment باید در مرکز برنامه ریزی ارتقاء vSphere شما باشد. چه از یک (external Platform Services Controller (PSC یا embedded استفاده کنید ، به یاد داشته باشید که توپولوژی را نمی توان در vSphere 6.0 یا 6.5 تغییر داد. اگر از vSphere 5.5 ارتقا می دهید ، تغییرات توپولوژی و ادغام SSO Domain Consolidation پشتیبانی می شود ، اما قبل از ارتقا به vSphere 6.x باید انجام شود.
vCenter Server 6.7 does not support host profiles with version less than 6.0 (See KB52932)
vCenter Server 6.7 supports Enhanced Linked Mode with an Embedded PSC (Greenfield deployments only)
If vCenter High Availability (VCHA) is in use within your vSphere 6.5 deployment, you must remove the VCHA configuration before attempting an upgrade.
معیارهای سازگاری محصولات VMware
گاهی اوقات با انتشار نرم افزارهای جدید، دیگر محصولاتی که بر پایه اجزای ارتقا یافته قرار دارند، ممکن است در روز از اول محصولات GA کاملا پشتیبانی نشوند یا سازگار نباشند. راهنمای سازگاری VMware باید یکی از اولین توقف های شما در طول مسیر ارتقاء vSphere باشد. با استفاده از این راهنما ها مطمئن میشوید که اجزای شما و همچنین مسیر ارتقاء مورد نظر شما ، پشتیبانی می شود.
با این محصولات زیر در حال حاضر سازگار با vSphere 6.7 GA نیستند.
VMware Horizon
VMware NSX
VMware Integrated OpenStack (VIO)
VMware vSphere Integrated Containers (VIC)
ملاحظات سخت افزاری
ارتقاء vSphere نیز می تواند توسط سخت افزار ناسازگار متوقف شود . با توجه به این موضوع، قبل از ارتقاء ، بایستی BIOS سخت افزار و سازگاری پردازنده را بررسی و مشاهده کنید. برای مشاهده لیست کامل CPU های پشتیبانی نشده، مقالهvSphere 6.7 GA Release Notes منتشر شده در بخشی تحت عنوان “Upgrades and Installations Disallowed for Unsupported CPUs“ را مرور کنید.
vSphere 6.7 no longer supports certain CPUs from AMD & Intel
These CPUs are currently supported in the vSphere 6.7 release, but they may not be supported in future vSphere releases;
Intel Xeon E3-1200 (SNB-DT)
Intel Xeon E7-2800/4800/8800 (WSM-EX)
Virtual machines that are compatible with ESX 3.x and later (hardware version 4) are supported with ESXi 6.7
Virtual machines that are compatible with ESX 2.x and later (hardware version 3) are not supported
سازگاری سخت افزار و نسخه hypervisor و سطح ماشین مجازی باید به عنوان بخشی از برنامه ریزی شما نیز در نظر گرفته شود. به یاد داشته باشید نسخه سخت افزاری VM اکنون به عنوان سازگاری VM شناخته می شود. توجه: ممکن است لازم باشد سازگاری ماشین مجازی را قبل از استفاده از آن در vSphere 6.7ارتقا دهید.
جمع بندی
جهت یاد آوری باید خاطر نشان کنیم که بخش چرا و چگونه را با تمرکز و دقت بالا مطالعه کنید. بدون داشتن تمرکز بر اینکه چه چیزی ارتقاء را در شرایط رضایت بخش به ارمغان می آورد یا درک تمام مزایای یکپارچه، در حقیقت آنها به راحتی می توانند از بین بروند. برنامه ریزی بخش بسیار مهم در مسیر ارتقاء است و بدون برنامه ریزی ممگن است در سازگاری ورژن ها به مشکل بر بخورید. اجرا ؛ بدون داشتن تمرکز و درک ویژگی ها یا روش ها و همچنین برنامه ریزی پیاده سازی ارتقاء vSphere ، شما قادر نخواهید بود که با موفقیت این کار را انجام دهید.
پس به یاد داشته باشید : تمرکز، برنامه ریزی، اجرا !
در این مقاله میخواهیم درباره آخرین نسخه از Vsphere نسخه 6.7 صحبت کنیم.
6.7 Vsphere توانایی های کلیدی را ارائه میکند که واحدهای فناوری اطلاعات را قادر می سازد تا به روند قابل توجه خواسته های جدید در عرصه فناوری اطلاعات در زیرساخت سازمان خود توجه کنند.
رشد انفجاری در تعدد و انواع برنامه های کاربردی ، از برنامه های مهم کسب و کار تا بارهای کاری هوشمند
رشد سریع محیط های ابری هیبرید و موارد استفاده آنها
رشد و گسترش مراکز داده مستقر در سرار جهان ، از جمله در لایه Edge
امنیت زیرساخت ها و برنامه های کاربردی که اهمیت فوق العاده ای را نیازدارند
مدیریت ساده و کارآمد در مقیاس
Vsphere 6.7 بر اساس نوآوری های تکنولوژی به کار رفته در Vsphere 6.7 ساخته شده و تجربه مشتری را به سطح کاملا جدیدی ارتقا داده است. سادگی مدیریت ، بهبود عملیاتی ، زمان عملکرد همه در یک مقیاس .
Vsphere 6.7 یک تجربه استثنائی برای کاربر با استفاده از vCenter Server Appliance) vCSA) به همراه دارد . این نسخه چندین APIs جدید را معرفی میکند که باعث بهبود کارایی و تجربه در راه اندازی vCenter ، راه اندازی چندین vCenter براساس یک قالب آماده میشود ، مدیریت vCenter Server Appliance و پشتیبان گیری و بازنشانی را به مراتب راحت تر میکند. همچنین به طور قابل توجهی توپولوژی vCenter Server را از طریق vCenter با embedded platform services controller را در حالت enhanced linked ساده تر کرده است که مشتریان را قادر میسازد تا چند vCenter را به هم پیوند دهند تا دسترس پذیری بدون مرز را در سرار محیط بدون نیاز به external platform services controller یا load balancers داشته باشند.
علاوه بر اینها ، با vSphere 6.7 vCSA بهبود عملکرد فوق العاده ای ارائه میشود . (تمام معیارها در مقایسه با vSphere 6.5 مقایسه شده است) :
2X faster performance in vCenter operations per second
این بهبود عملکرد از داشتن تجربه کاربری سریع برای کاربران vSphere اطمینان حاصل میکند ، ارزش قابل توجه و همچنین صرفه جویی در وقت و هزینه در موارد استفاده متنوع همچون VDI ، Scale-out apps ، Big Data ، HPC ، DevOps distributed cloud native apps و غیره دارد.
vSphere 6.7 بهبود هایی در مقایس و کارایی در زمان بروزرسانی ESXi هاست ها دارد. با حذف یکی از دو بار راه اندازی مجدد که به طور معمول برای ارتقاء نسخه اصلی مورد نیاز است ، زمان تعمیر و نگهداری را به طور قابل توجهی کاهش میدهد (Single Reboot) . علاوه بر آن Quick boot یک نوآوری جدید است که ESXi hypervisor را بدون راه اندازی مجدد هاست فیزیکی ، و حذف زمان سپری شده برای بوت شدن ، از سر میگیرد.
یکی دیگر از مولفه های کلیدی vSphere 6.7 رابط کاربر گرافیکی است که تجربه ایی ساده و کارآمد را ارائه می دهد ، می باشد. vSphere Client مبتنی بر HTML5 یک رابط کاربری مدرن ارائه میکند که پاسخگوی هر دو نیاز واکنشگرایی و سهولت در استفاده برای کاربر است. با vSphere 6.7 که شامل قابلیت های اضافه شده برای پشتیبانی از نه تنها جریان های کاری معمولی مشتریان ، بلکه سایر قابلیت های کلیدی مانند مدیریت NSX ، vSAN ، VUM و همچنین اجزای third-party است.
vSphere 6.7 بر روی قابلیت های امنیتی در vSphere 6.5 ایجاد شده و موقعیت منحصر به فرد آن را به عنوان hypervisor ارائه می دهد تا امنیت جامع را که از هسته شروع می شود، از طریق یک مدل مبتنی بر سیاست عملیاتی ساده هدایت کند.
vSphere 6.7 ابزارهای سخت افزاری Trusted Platform Module (TPM) 2.0 و همچنین Virtual TPM 2.0 را پشتیبانی می کند و به طور قابل توجهی امنیت و یکپارچگی را در hypervisor و سیستم عامل مهمان به همراه دارد.
این قابلیت از VM ها و هاست ها در برابر tampered شدن جلوگیری ، از بارگیری اجزای غیر مجاز ممانعت و ویژگی های امنیتی سیستم عامل مهمان را که توسط تیم های امنیتی درخواست شده فعال می کند.
رمزگذاری داده ها همراه با vSphere 6.5 معرفی شد و به خوبی جا افتاد. با vSphere 6.7 ، رمزگذاری VM بهبود بیشتری یافته و عملیات مدیریت را آسان تر کرده است. vSphere 6.7 جریان های کاری را برای رمزگذاری VM ساده می کند ، برای محافظت در داده ها در حالت سکون و جابجایی طراحی شده ، ساخت آن را به آسانی با یک راست کلیک و همچنین افزایش امنیت وضعیت رمزگذاری VM و دادن کنترل بیشتری برای محافظت به کاربر در برابر دسترسی به داده های غیر مجاز میدهد.
vSphere 6.7 همچنین حفاظت از داده ها را در حرکت با فعال کردن vMotion رمزگذاری شده درinstances های مختلف vCenter و همچنین نسخه های مختلف ارائه میدهد ، ساده تر کردن عملیات migrations دیتاسنتر را ایمن میکند ، داده ها را در یک محیط (hybrid cloud (between on-premises and public cloud ، و یا در سراسر دیتاسنتر ها با موقعیت های مختلف جغرافیای انتقال می دهد.
vSphere 6.7 از تمام رنج تکنولوژی ها و فن آوری های امنیتی مبتنی بر مجازی سازی مایکروسافت پشتیبانی می کند. این یک نتیجه همکاری نزدیک بین VMware و مایکروسافت است تا مطمئن شود ماشین های ویندوزی در vSphere از ویژگی های امنیتی in-guest در حالی که همچنان در حال اجرا با عملکرد مناسب و امنیت در پلت فرم vSphere هستند ، پشتیبانی میکند.
vSphere 6.7 امنیت داخلی جامعی را ارائه میکند که قلب SDDC ایمن است ، که این ادغام عمیق و یکپارچه با سایر محصولات VMware مانند vSAN، NSX و vRealize Suite برای ارائه یک مدل کامل امنیتی برای مرکز داده است.
Universal Application Platform
vSphere 6.7 یک پلتفرم کاربردی عمومی است که ظرفیت های کاری جدید مانند (تصاویر گرافیکی 3 بعدی، اطلاعات حجیم، HPC، یادگیری ماشینی، (In-Memory و Cloud-Native) را به خوبی mission critical applications موجود ، پشتیبانی میکند. همچنین برخی از آخرین نوآوری های سخت افزاری در صنعت را پشتیبانی میکند و عملکرد استثنایی را برای انواع کار های مختلف ارائه میدهد.
vSphere 6.7 پشتیبانی و قابلیت های معرفی شده برای GPU را از طریق همکاری VMware و Nvidia ، با مجازی سازی GPUهای Nvidia حتی برای non-VDI و موارد غیر محاسباتی مانند هوش مصنوعی ، یادگیری ماشینی، داده های حجیم و موارد دیگر افزایش میدهد.
با پیشرفت تکنولوژی به سمت Nvidia GRID™ vGPUدر vSphere 6.7 ، به جای نیاز به خاموش کردن بارهای کاری بر روی GPUها ،مشتریان میتوانند به راحتی این ماشین ها را موقتا متوقف کنند و یا اینکه از سر گیرند، به این ترتیب مدیریت بهتر چرخه حیاط هاست ، و به طور قابل توجهی باعث کاهش اختلال برای کاربران نهایی میشود. Vmware همچنان با هدف ارائه تجربه کامل Vsphere به GPU ها در نسخه های آینده در این زمینه سرمایه گذاری میکند.
vSphere 6.7 با افزودن پشتیبانی از نوآوری های کلیدی صنعت ، که آماده است تا تاثیر قابل توجهی بر چشم انداز، که حافظه پایدار است ، همچنان رهبری تکنولوژی Vmware و همکاری پربار با شرکای کلیدی خود را به نمایش میگذارد . با حافظه پایدار vSphere، مشتریان با استفاده از ماژول های سخت افزاری پشتیبانی شده، مانند آنهایی که از Dell-EMC و HPE موجود هستند، می تواند آنها را به عنوان ذخیره سازی های فوق سریع با IOPS بالا، و یا به سیستم عامل مهمان به عنوان حافظه non-volatile قرار دهند این به طور قابل توجهی عملکرد سیستم عامل را در برنامه ها برای کاربرد های مختلف ، افزایش میدهد و برنامه ای موجود را سریعتر و کارآمدتر میکند و مشتریان را قادر میسازد تا برنامه های با عملکرد بالا بسازند که میتواند از حافظه مداوم vSphere استفاده کند.
شما میتوانید مجله Virtual Blocks Core Storage 6.7 را نیز ببینید که در آن اطلاعات بیشتری را در مورد استوریج جدید و ویژگی های شبکه ای مانند Native 4Kn disk support ، RDMA support و Intel VMD برای NVMe که بیشتر برنامه های سازمانی را در vSphere اجرا میکند، مشاهده کنید.
تجربه Hybrid Cloud) Seamless Hybrid Cloud)
با پذیرش سریع vSphere-based public clouds از طریق شرکاری VMware Cloud Provider Program ، VMware Cloud در AWS، و همچنین دیگر ارائه دهندگان cloud ، VMware متعهد به ارائه یک cloud ترکیبی یکپارچه برای مشتریان است. vSphere 6.7 قابلیت vCenter Server Hybrid Linked Mode را معرفی میکند که آن را برای مشتریان به منظور داشتن نمایش پذیری unified و قابلیت مدیریتی on-premises محیط vSphere در حال اجرا بر روی یک نسخه و محیط vSphere-based public cloud ، مانند VMware Cloud در AWS، در حال اجرا بر روی نسخه های مختلف از vSphere را آسان و ساده کرده است. این قابیت از افزایش سرعت نوآوری و معرفی قابلیت های جدید در vSphere-based public clouds اطمینان حاصل میکند و مشتری را مجبور نمی کند تا به طور مداوم محیط محلی vSphere را به روز رسانی و ارتقا دهد.
vSphere 6.7 همچنین قابلیت Migration در حالت Cold وHot در محیط Cross-Cloud میدهد ، علاوه بر افزایش سهولت مدیریت ، تجربه seamless و non-disruptive hybrid cloud را ارائه میدهد. همانطور که ماشین های مجازی بین مراکز داده های مختلف مهاجرت می کنند ، یا از یک مرکز داده محلی به cloud و بلعکس منتقل میشوند ، آنها احتمالا در میان انواع پردازنده های مختلف حرکت می کنند. vSphere 6.7 قابلیت جدیدی را فراهم می کند که کلیدی برای محیط های hybrid cloud است که به نام Per-VM EVC نامیده می شود. Per-VM EVC قابلیت EVC) Enhanced vMotion Compatibility) را به یک ویژگی ماشین تبدیل میکند ، که به جای استفاده از نسل خاصی از پردازنده که در cluster بوت شده ، از آن استفاده کند. این قابلیت seamless migration را در سراسر CPU های مختلف با حفظ حالت EVC در هر ماشین در طول migrations در سراسر کلاستر ها اجازه میدهد.
پیش از این vSphere 6.0 قابلیت provisioning را بین vCenter instances معرفی کرده بود که اغلب به نام ” cross-vCenter provisioning ” یاد می شود. استفاده از دو مورد vCenter این احتمال را می دهد که نمونه ها در نسخه های مختلف انتشار قرار داشته باشند. vSphere 6.7 مشتریان را قادر می سازد تا از نسخه های مختلف vCenter استفاده کنند، در حالی که اجازه می دهد cross-vCenter, عملیات provisioning مانند: (vMotion, Full Clone , cold migrate) را به طور یکپارچه ادامه دهد . این به خصوص برای مشتریانی که توانایی استفاده از VMware Cloud را در AWS به عنوان بخشی از hybrid cloud خود دارند، مفید است.
آدرس IP شناسه ای یکتا برای مشخص شدن یک device در یک شبکه می باشد. یکتا بودن آدرس IP بدین معناست که آدرس IP یک device داخل شبکه ای که در آن قرار دارد فقط به آن سیستم اختصاص دارد . تا زمانی که یک device آدرس IP نداشته باشد نمی تواند با device های دیگر ارتباط برقرار کند .
آدرس های IP به دو دسته تقسیم می شوند . دسته ی اول IPv4 می باشد که اکثر ما با آن برخورد داشته ایم و تا حدودی با آن آشنا هستیم. آدرس IP ورژن 4 یک آدرس 32 بیتی است که به صورت 4 عدد در مبنای ده که با نقطه از هم جدا شده اند، نمایش داده می شود (مانند : 192.168.1.1 ). این ورژن از IP به تعداد 2 به توان 32 آدرس را ارائه می کند. در حال حاضر بیش از 90 درصد آدرس ها در جهان ، IPv4 می باشد.
از آنجایی که استفاده از پروتکل TCP/IP در سال های اخیر بیش از حد انتظار بوده، در آدرس دهی IPv4 ، محدود هستیم و آدرس های IPv4 رو به اتمام است. این یکی از دلایلی است که TCP/IP یک ورژن جدید از آدرس های IP را طراحی کرد که با نام IPv6 شناخته می شود.
بعضی از مزیت هایی که IPv6 دارد :
هزینه ی کمتر پردازشی : packet های IPv6 باز طراحی شده اند تا header های ساده تری را تولید و استفاده کنند که این موضوع فرایند پردازش packet ها توسط سیستم های فرستنده و گیرنده را بهبود می دهد.
آدرس های IP بیشتر : IPv6 از ساختار آدرس دهی 128 بیتی استفاده می کند در حالی که IPv4 از ساختار آدرس دهی 32 بیتی استفاده می کند . این تعداد آدرس IP این اطمینان را می دهد که حتی بیشتر از آدرس های مورد نیاز در سال های آینده ، آدرس موجود است.
Multicasting: درIPv6 از Multicasting به عنوان روش اصلی برقرار کردن ارتباط استفاده می شود. IPv6 بر خلاف IPv4 روش broadcast را ارائه نمی دهد. روش broadcast از پهنای باند شبکه به صورت غیر بهینه و نامناسب استفاده می کند.
IPSec: پروتکل Internet Protocol Security)IPSec) در درون IPv4 وجود نداشت اما IPv4 از آن پشتیبانی می کرد در حالی که IPv6 این پروتکل را به صورت built in در درون خود دارد و می تواند تمامی ارتباطات را رمز گذاری (encrypt) کند.
آدرس دهی در IPv6
در IPv6 تغییرات عمده ای نسبت به IPv4 وجود دارد. IPv4 از ساختار آدرس دهی 32 بیتی استفاده می کند در حالی که IPv6 از ساختار آدرس دهی 128 بیتی استفاده می کند. این تغییر می تواند 2 به توان 128 آدرس یکتا را ارائه دهد . این میزان آدرس IP، پیشرفت بسیار زیادی را نسبت به تعداد آدرس IP که IPv4 ارائه می کند(2 به توان 32) دارد.
آدرس IPv6 دیگر از 4 بخش 8 بیتی استفاده نمی کند. آدرس IPv6 به 8 قسمت 16 بیتی که هر قسمت ارقامی در مبنای 16 هستند و با (:) از هم جدا می شوند تقسیم میشود. مانند:
65b3:b834:45a3:0000:0000:762e:0270:5224
در مورد آدرس های IPv6 یک سری نکته هایی وجود دارد که باید آنها را بدانید:
این آدرس ها نسبت به بزگی حروف حساس نیستند
صفر های سمت چپ هر بخش را میتوان حذف کرد
بخش هایی که پشت سر هم صفر هستند را میتوان به صورت (::) خلاصه نویسی کرد (روی هر آدرس فقط یک بار می توان این کار را کرد)
مثال: آدرس loopback در IPv6 به صورت زیر است :
0000:0000:0000:0000:0000:0000:0000:0001
از آنجایی که می توان صفرهای سمت چپ هر بخش را حذف کرد آدرس را بازنویسی می کنیم :
0:0:0:0:0:0:0:1
بعد از حذف کردن صفرهای سمت چپ ، می توانیم صفرهای پشت سر هم را نیز خلاصه نویسی کنیم :
1::
همانطور که اشاره کردیم ، فقط یک بار می توانیم صفرهای پشت سر هم را خلاصه نویسی کنیم ، علت این موضوع این است که اگر چند بار این خلاصه نویسی را روی بخش های مختلف آدرس انجام دهیم ، آدرس اصلی بعد از خلاصه نویسی مشخص نخواهد بود . به مثال زیر توجه کنید:
0000:0000:45a3:0000:0000:0000:0270:5224
در این مثال دو سری صفر های پشت سر هم وجود دارد . اگر هر دو را خلاصه نویسی کنیم به صورت زیر می شود :
45a3::270:5224::
در این حالت مشخص نیست که هر سری چه تعداد صفر پشت سر هم داشته ایم ، پس بهتر است که آن سری که تعداد صفر های بیشتری پشت سر هم دارد را خلاصه نویسی کنید.
0:0:45a3::270:5224
ساختار آدرس دهی در IPv6 به کلی تغییر کرده است ، به طوری که 3 نوع آدرس وجود دارد :
Unicast: آدرس Unicast برای ارتباطات یک به یک استفاده می شود.
Multicast: آدرس Multicast برای ارسال data به سیستم های مختلف در یک لحظه استفاده می شود. آدرس های Multicast با پیشوند FF01 شروع می شوند. برای مثال FF01::1 برای ارسال اطلاعات به تمام node ها در شبکه استفاده می شود ، در حالی که FF01::2 برای ارسال اطلاعات به تمام روترهای داخل شبکه استفاده می شود.
Anycast: آدرس Anycast برای گروهی از سیستم ها که سرویسی را ارائه می کنند استفاده می شود.
توجه کنید که آدرس broadcast در IPv6 وجود ندارد.
آدرس های Unicast خود به سه دسته تقسیم می شود :
Global unicast: آدرس های Global unicast ، آدرس های public در IPv6 میباشد و قابلیت مسیریابی در اینترنت دارد. این آدرس ها معادل آدرس های public در IPv4 می باشد.
Site-local unicast: آدرس های Site-local unicast ، آدرس های private هستند و مشابه آدرس های private در IPv4 می باشند و فقط برای ارتباطات داخل شبکه ای استفاده می شوند. این آدرس ها همیشه با پیشوند FEC0 شروع می شوند.
Link-local unicast: آدرس های Link-local unicast مشابه APIPA در IPv4 هستند و فقط می توانند برای ارتباط با سیستمی که به آن متصل هستند ، استفاده شوند. این آدرس ها با پیشوند FE80 شروع می شود.
نکته دیگری که باید به آن اشاره کنیم ، IPv6 ازClassless Inter-Domain Routing (CIDR) که در سال های اخیر متداول شده اند( برای تغییر بخش net ID روی IPv4 )،استفاده می کند.برای مثال آدرس 2001:0db8:a385::1/48 بدین معناست که 48 بیت اول آدرس تشکیل دهنده ی net ID است.
IPv6 به 3 بخش تقسیم می شود:
Network ID: معمولا 48 بیت اول آدرس تشکیل دهنده ی net ID آن می باشد. در آدرس های global address ، net ID توسط ISP به سازمان شما اختصاص داده می شود.
Subnet ID: این بخش از 16 بیت تشکیل شده و با استفاده از آنها می توانید شبکه ی IPv6 خود را به subnet های مختلف تقسیم کنید. برای مثال شبکه ای با net ID 2001:ab34:cd56 /48 می تواند به دو زیرشبکه 2001:ab34:cd56:0001/64 و 2001:ab34:cd56:0002/64 تقسیم شود.
(Unique Identifier(EUI-64: نیمه ی دوم آدرس (64 بیت آخر) را unique identifier می نامند، این بخش مشابه host ID در IPv4 است (یک سیستم را در شبکه مشخص می کند). این بخش تشکیل می شود از مک آدرس آن سیستم (48 بیت)که به دو قسمت تقسیم شده و عبارت FFFE که میان آن دو قسمت قرار می گیرد.
Auto configuration
یکی از مزیت های IPv6 قابلیت auto configuration است ، که در آن سیستم یک آدرس IPv6 برای خود انتخاب می کند ، سپس با ارسال پیام neighbor solicitation به آن آدرس بررسی میکند که این آدرس در شبکه برای سیستم دیگری استفاده نشده باشد. اگر این آدرس توسط سیستم دیگری استفاده شده باشد ، به پیام جواب می دهد و سیستمی که قصد انتخاب آدرس را داشت متوجه می شود که از آن آدرس نمی تواند استفاده کند. قابل ذکر است احتمال اینکه یک آدرس به دو سیستم اختصاص داده شود خیلی کم است چون مک آدرس سیستم ها در آدرس دهی auto configuration استفاده می شود (مک آدرس یک آدرس یکتا است).
با توجه به تکنولوژی های پیش روی دنیای اطلاعات به ویژه IOT یا اینترنت اشیاء که به واسطه آن میتوان تعداد زیادی از اشیاء که در طول روز با آن ها سر و کار داریم (مانند سیستم های گرمایشی و سرمایشی، لوازم خانگی، ملزومات اداری و ...)، که به صورت هوشمند کنترل می شوند را با یکدیگر در بستر اینترنت ارتباط خواهند داشت. این امر بدین معناست که به میلیاردها آدرس IP نیاز خواهیم داشت و ملزم به استفاده از IPv6 می باشیم .
ما بسیار خوشحالیم که در این مقاله ، ویژگی های جدید امنیت در vSphere 6.7 را به شما معرفی خواهیم کرد. اهداف امنیتی در ورژن 6.7 به دو جزء تقسیم میشوند . معرفی ویژگی های جدید امینتی با قابلیت راحتی در استفاده و برآورده شدن نیازهای مشتریان و تیم های امنیت آی تی .
پشتیبانی از TMP 2.0 در ESXi
همانطور که همه شما میدانید ، (TPM (Trusted Platform Module یک دیوایس بر روی لب تاپ ، دسکتاپ یا سرور میباشد و برای نگه داری اطلاعات رمزگذاری شده مثل (keys, credentials, hash values) استفاده میشود . TPM 1.2 برای چندین سال در ESXi موجود بود اما عمدتا توسط پارتنر ها مورد استفاده قرار می گرفت. TPM 2.0 با 1.2 سازگار نیست و نیاز به توسعه تمام درایور های دستگاه و API جدید دارد. ESXi از TPM 2.0 بر اساس تلاش های ما بر روی 6.5 با Secure Boot ، استفاده میکند. به طور خلاصه ما تایید میکنیم که سیستم با Secure Boot فعال ، بوت شده است و ارزیابی را انجام میدهیم و در TPM ذخیره میکنیم . vCenter این ارزیابی ها را میخواند و با مقادیری که توسط خود ESXi گزارشگیری شده مقایسه میکند. اگر مقادیر مطابقت داشته باشند، سیستم با Secure Boot فعال ، بوت شده است وهمه چیز خوب است و فقط کد های تایید شده اجرا میشوند و مطمئن هستیم که کد های تایید نشده وجود ندارد . vCenter یک گزارش تایید در vCenter web client که وضعیت هر هاست را نشان میدهد ارائه میکند.
TMP 2.0 مجازی در ماشین ها
برای پشتیابنی از TPM برای ماشین های مجازی ، مهندسین ما دیوایس مجازی TPM 2.0 را ایجاد کرده اند که در ویندوز مانند یک دستگاه معمولی نمایش داده میشود و مانند TPM فیزیکی ، می تواند عملیات رمزنگاری را انجام دهد و مدارک را ذخیره کند. اما چگونه داده ها را در TPM مجازی ذخیره می کنیم؟ ما این اطلاعات را در فایل nvram ماشین ها مینویسیم و آنرا با VM Encryption ایمن میکنیم . این عملیات اطلاعات را در vTPM ایمن میکند و همراه با ماشین جابجا میشود . اگر این VM را به یک دیتاسنتر دیگر کپی کنیم و این دیتاسنتر برای صحبت با KMS ما پیکربندی نشده باشد ، آن وقت دیتا در vTPM ایمن خواهد بود. نکته : فقط فایل های “home” ماشین رمزگذاری میشود نه VMDK’s ، مگر اینکه شما انتخاب کنید که آنها را نیز رمزگذاری کنید.
چرا از TMP سخت افزاری استفاده نکردیم ؟
یک سخت افزار TPM محدودیت هایی هم دارد . به دلیل اینکه یک دستگاه serial هست پس کمی کند است. یک nvram ایمن که ظرفیت ذخیره سازی آن با بایت اندازه گیری میشود دارد . توانایی تطبیق با بیش از 100 ماشین در یک هاست را ندارد و قادر به نوشتن تمام اطلاعات TPM آنها در TPM فیزیکی نیست و به یک scheduler برای عملیات رمزنگاری نیاز دارد . فرض کنید 100 ماشین در حال تلاش برای رمزنگاری چیزی هستند و وابسته به یک دستگاه serial که فقط میتواند 1 رمزنگاری در آن واحد انجام دهد ؟ اوه…. حتی اگر بتواند اطلاعات را فیزیکی ذخیره کند ، عملیات vMotion را در نظر بگیرید ! مجبور است داده ها را به طور ایمن از یک TPM فیزیکی حذف و آن را به دیگری کپی کند و با استفاده از کلیدهای TPM جدید دوباره داده ها را امضا کند. تمام این اقدامات در عمل بسیار آهسته است و با مسائل امنیتی و الزامات امنیتی اضافی همراه است.
توجه داشته باشید: برای اجرای TPM مجازی، شما به VM Encryption نیاز دارید. این بدان معناست که شما به یک زیرساخت مدیریت کلید سوم شخص در محیط خود هستید .
پشتیبانی از ویژگی های امنیتی مبنی بر مجازی سازی مایکروسافت
تیم امنیتی شما احتمالا درخواست یا تقاضای پشتیبانی “Credential Guard” میدهد. این همان است . در سال 2015 ، مایکروسافت ویژگی های امنیتی مبنی بر مجازی سازی را معرفی کرد . ما نیز همکاری بسیار نزدیکی با مایکروسافت داشتیم تا این ویژگی ها را در vSphere 6.7 پشتیبانی کنیم . بیایید یک نمای کلی از آنچه در زیر این پوشش انجام دادیم تا این اتفاق بیافتد رامشاهده کنیم . وقتی VBS را بر روی لپتاپتان با ویندوز 10 فعال میکنید ، لپ تاپ ریبوت میشود و به جای بوت مستقیم به ویندوز 10 ، سیستم Hypervisor مایکروسافت را بوت می کند. برای vSphere این به معنای این است که ماشین مجازی که ویندوز 10 را به طور مستقیم اجرا می کرد در حال حاضر در حال اجرا hypervisor مایکروسافت است که در حال حاضر ویندوز 10 را اجرا می کند. این فرآیند ” nested virtualization” نامیده می شود که چیزی است که VMware تجربه بسیارزیادی با آن را دارد. ما از nested virtualization در Hands On Lab’s برای سال ها است که استفاده میکنیم. هنگامی که VBS را در سطح vSphere فعال می کنید، این یک گزینه تعدادی از ویژگی های زیر را فعال میکند.
و کاری که نمیکند هم این است که VBS را در ماشین سیستم عامل میهمان فعال نمیکند. برای انجام این کار از راهنمایی مایکروسافت پیروی کنید. این کار را می توانید با اسکریپت های PowerShell، Group Policies و غیره انجام دهید. نکته در اینجاست که نقش vSphere این است که سخت افزار مجازی را برای پشتیبانی از فعال سازی VBS فراهم کند. در کنار TPM مجازی شما هم اکنون می توانید VBS را فعال کنید و ویژگی هایی مانند Gredential Guard را فعال کنید. اگر شما امروز در حال ساخت ویندوز 10 یا ویندوز سرور 2016 VM هستید، من به شدت توصیه می کنم آنها را با EFI firmware فعال نصب کنید. انتقال از BIOS / MBR سنتی به EFI (UEFI) firmware پس از آن برخی از چالش ها را بعدا به همراه دارد که در خطوط پایین نشان می دهیم.
بروزرسانی UI
در vSphere 6.7 ما بهبود های زیادی در عملکرد وب کلاینت HTML)5) ایجاد کرده ایم . هم اکنون در تمام مدت ازآن استفاده میکنیم . این محیط سریع است و بخوبی ایجاد شده و هرکاری در آزمایشگاهم میخواهم انجام میدهد . ما برخی تغییرات به منظور ساده تر کردن همه چیز برای ادمین ها در سطح رمزنگاری ماشین ایجاد کرده ایم. در پس زمینه ما هنوز از Storage Policies استفاده میکنیم ، اما تمام توابع رمزنگاری را (VM Encryption, vMotion Encryption) در یک پنل VM Options ترکیب کرده ایم.
چندین هدف SYSLOG
این چیزی است که من شخصا مدت زیادی منتظرش بودم . یکی از درخواستهایی که من داشته ام این است که توانایی کانفیگ چندین هدف SYSLOG از محیط UI را داشته باشم . چرا ؟ برخی از مشتریان می خواهند جریان SYSLOG خود را به دو مکان منتقل کنند. به عنوان مثال، تیم های IT و InfoSec. . کارمندان IT عاشق VMware Log Insight هستند ، تیم های InfoSec معمولا از Security Incident و Event Management system که دارای وظایف تخصصی هستند برای اهداف امنیتی استفاده میکنند . در حال حاضر هر دو تیم ها می توانند یک جریان غیر رسمی از رویدادهای SYSLOG برای رسیدن اهداف مربوطه خود داشته باشند. رابط کاربری VAMI در حال حاضر تا سه هدف مختلف SYSLOG پشتیبانی می کند.
FIPS 140-2 Validated Cryptographic Modules – By Default
این خبر بزرگ برای مشتریان ایالات متحده است . در داخل vSphere) vCenter و ESXi) دو ماژول برای عملیات رمزنگاری وجود دارد. ماژول VM Kernel Cryptographic توسط VM Encryption و ویژگی های Encrypted vSAN و ماژول OpenSSL برای مواردی مانند ایجاده کننده گواهینامه ها (certificate generation) و TLS connections استفاده میشود . این دو ماژول گواهی اعتبارسنجی FIPS 140-2 را کسب کرده اند. خب ، این به این معنیست که vSphere تاییده FIPS را دارد ؟! خب بعضی از اصطلاحات در جای نادرستی به کاربرده شده است . برای کسب “FIPS Certified” در واقع به یک راه حل کامل از سخت افزار و نرم افزار که با هم تست شده و پیکربندی شده نیاز است. آنچه در VMware انجام دادیم این است که فرایند FIPS را برای اعتبار سنجی vSphere توسط شرکایمان ساده تر کرده ایم. ما منتظر دیدن این اتفاق در آینده نزدیک هستیم. آنچه مشتریان معمولی vSphere باید بداند این است که تمام عملیات رمزنگاری در vSphere با استفاده از بالاترین استانداردها انجام می شود زیرا ما تمامی عملیات رمزنگاری FIPS 140-2 را به صورت پیش فرض فعال کرده ایم.
جمع بندی
بسیاری از موارد امنیتی جدید وجود دارد.آنچه که اینجا مطالعه کردید این است که ما ویژگی های جدید مانند Secure Boot برای ESXi و VM Encryption و بالاتر از همه آنها قالبیت های های لایه جدید مانند TPM 2.0 و virtual TPM . امیدواریم که این روند به همین ترتیب ادامه داشته باشد . ما تعهد داریم که بهترین امنیت درنوع خود ، در حالی که هم زمان برای ساده سازی اجرا و مدیریت آن تلاش میکنیم ، ارائه دهیم . من می خواهم از تمام تیم های تحقیق و توسعه VMware تشکر کنم برای کار متمایزی که در این نسخه انجام داده اند. آنها سخت کار میکنند تا امنیت شما را برای اجرای و مدیریت آسان تر کنند! آینده در سرزمین vSphere بسیار درخشان است .
فایروال ها دیواره هایی هستند که برای ایمن نگاه داشتن شبکه در برابر هکرها، بدافزارها و دیگر مهاجمان استفاده می شوند. فایروال ها هم به فرم سخت افزار و هم نرم افزار وجود دارند و همه آنها امنیت را بین شبکه و تهدیدهای بیرونی برقرار می سازند. مدیران شبکه، به گونه ای فایروال ها را برای نیازمندی های سیستم مورد نظر خود تنظیم می کنند که عدم وجود داده های آسیب پذیر را تضمین کند. شرکت های کوچک و کامپیوترهای شخصی به ندرت به فایروال های سخت افزاری نیاز خواهند داشت اما شرکت ها و واحدهای تجاری بزرگ از فایروال های سخت افزاری درون سیستم های خود استفاده می کنند تا دسترسی های بیرون از شرکت و مابین دپارتمان ها را محدود کنند. مشتری ها با توجه به نیازمندی های شبکه خود و ویژگی های ارائه شده در فایروال ها، آنها را از میان شرکت های سازنده مختلفی می توانند برگزینند. یکی از برجسته ترین سازندگانفایروال های NGFW کمپانی سیسکو است که در جدول زیر به مقایسه فایروال های NGFW خود با فایروال های NGFW از شرکت های Palo alto، Fortinet و Check Point می پردازد.
ویژگی های امنیت :
CISCO
PALO ALTO NETWORKS
FORTINET
CHECK POINT SOFTWARE TECHNOLOGIES
تحلیل مستمر و شناسایی با نگاه به گذشته
سیسکو تحلیل مستمری را خارج از point-in-time به کار می بندد، و با نگاهی به گذشته می تواند شناسایی کند، هشدار دهد، پیگردی کند، تحلیل کند و بدافزارهای پیشرفته ای را اصلاح کند که ممکن است با ظهورشان در همان ابتدا پاک شوند یا اینکه از دفاع اولیه سرباز زند و پس از آن به عنوان مخرب تعیین شوند.
تنها تحلیل و شناسایی point-in-time را انجام خواهد داد. تحلیل های point-in-time ایجاب می کند که در لحظه ای که برای اولین بار فایل دیده می شود، داوری بر روی وضعیت آن انجام شود. اگر فایلی به تدریج تغییر یابد یا اینکه بعدا شروع به فعالیت مخرب کند، هیچ کنترلی در محل وجود ندارد که نشانی از چیزی که اتفاق افتاده یا جایی که بدافزار به آن منتهی شده را نگاه دارد.
تنها تحلیل و شناسایی point-in-time را انجام خواهد داد. همان توضیحاتی که در این مورد برای palo alto آورده شده است، برای این برند نیز صدق می کند.
تنها تحلیل و شناسایی point-in-time را انجام خواهد داد. همان توضیحاتی که در این مورد برای palo alto آورده شده است، برای این برند نیز صدق می کند.
مسیر حرکت فایل شبکه
سیسکو طرح ریزی می کند که چگونه هاست ها فایل هایی که شامل فایل های مخرب هستند را در سراسر شبکه شما انتقال دهند. فایروال سیسکو می تواند ببیند که انتقال یک فایل مسدود یا فایل قرنطینه شده است. در این فایروال میانگینی از میدان دید، ارائه کنترل هایی همه گیر و تشخیص مشکل اولیه را فراهم می کند
مسیر حرکت به تحلیل مستمر وابسته است. به دلیل نبود تحلیل مستمر پشتیبانی نمی کند.
مسیر حرکت به تحلیل مستمر وابسته است. به دلیل نبود تحلیل مستمر پشتیبانی نمی کند.
مسیر حرکت به تحلیل مستمر وابسته است. به دلیل نبود تحلیل مستمر پشتیبانی نمی کند.
برآورد اثرات
Cisco Firepower همه رویدادهای نفوذ را به اثرات حمله مرتبط می کند تا به اپراتور بگوید که چه چیزی به توجه فوری نیاز دارد.
محدود اثرات تنها در مقابل شدت تهدید ارزیابی می شوند. هیچ اطلاعات پروفایلی از هاست برای تعیین آسیب پذیری در مقابل تهدید در اختیار نمی گذارد.
محدود اثرات تنها در مقابل شدت تهدید ارزیابی می شوند. هیچ اطلاعات پروفایلی از هاست برای تعیین آسیب پذیری در مقابل تهدید در اختیار نمی گذارد.
محدود اثرات تنها در مقابل شدت تهدید ارزیابی می شوند. هیچ اطلاعات پروفایلی از هاست برای تعیین آسیب پذیری در مقابل تهدید در اختیار نمی گذارد.
اتوماسیون امنیت و مدیریت تطبیق پذیر تهدید
سیسکو به طور خودکار دفاع ها را با تغییرات پویا در شبکه، در فایل ها، یا با هاست ها منطبق می کند. اتوماسیون عناصر دفاعی کلیدی همچون تنظیم مقررات NGIPS و سیاست فایروال شبکه را پوشش می دهد.
همه سیاست ها به تعاملات سرپرست نیاز دارد. سیاست ها به تنظیمات پایه محدود می شود. خطاهای false positive به طور غیرخودکار شناسایی و کاهش داده می شوند.
همه سیاست ها به تعاملات سرپرست نیاز دارد. سیاست ها به تنظیمات پایه محدود می شود. خطاهای false positive به طور غیرخودکار شناسایی و کاهش داده می شوند.
سیاست ها به تعاملات سرپرست نیاز دارند.
Behavioral indicators of compromise IoCs
Cisco Firepower عملکرد فایل و شهرت سایت ها را بررسی می کند، و شبکه و فعالیت endpoint را با استفاده از بیش از 1000 شاخص عملکردی به هم مرتبط می کند. بیلیون ها مصنوعات بدافزاری را برای ارتقا و پوشش بی نظیر در برابر تهدیدهای جهانی ارائه می دهد.
استاندارد، nonbehavioral IoCs در محصولی مجزا در دسترس است.
IoC مبتنی بر شدت تهدید است نه عملکرد.
IoC مبتنی بر شدت تهدید است نه عملکرد.
آگاهی از وضعیت کاربر، شبکه و endpoint
Cisco Firepower تحلیل کاملی از تهدیدها و محافظت در برابر آنها را با آگاهی نسبت به کاربران، پیشینه کاربر بر روی هر ماشین، دستگاه های موبایل، اپلیکیشن های سمت کلاینت، سیستم عامل ها، ارتباطات ماشین به ماشین مجازی، آسیب پذیری ها، تهدیدها و URL ها فراهم می کند.
تنها آگاهی از کاربران را پشتیبانی می کند.
تنها آگاهی از کاربر را پشتیبانی می کند. مگر اینکه نرم افزار endpoint مجزایی استفاده شود.
تنها آگاهی از کاربر را پشتیبانی می کند. مگر اینکه نرم افزار endpoint مجزایی استفاده شود.
NGIPS
Next-gen -سیستم IPS با آگاهی بی وقفه و نگاشت شبکه
Signature-based
Signature-based
Signature-based
حفاظت پیشرفته جامع در برابر تهدید
پوشش می دهد -قابلیت های sandboxing پویای توکار (AMP-ThreatGrid)، بدافزارهای آگاه از sandbox و evasive را شناسایی می کند. وابستگی رویدادهای قابل تعقیب، behavioral IoCs >1000، بیلیون ها مصنوعات مخرب و درک آسان محدوده تهدیدها را فراهم می کند.
محدود است -Sandbox به صورت cloud به اشتراک گذاشته می شود یا بر روی دستگاه نصب است
محدود است -Sandbox به صورت cloud به اشتراک گذاشته می شود یا بر روی دستگاه نصب است
محدود است -Sandbox به صورت cloud به اشتراک گذاشته می شود یا بر روی دستگاه نصب است
اصلاح بدافزارها
پوشش می دهد -اتوماسیون هوشمند که از جمله قابلیت های Cisco AMP است به شما اجازه می دهد که به سرعت محدوده بدافزار را بفهمید، و یک حمله فعال را حتی پس از رخدادش، مهار کنید
محدود است - برای یک محدوده تهدید ناشناخته هیچ علتی ریشه ای یا نتایجی از مسیر حرکت ارائه نمی دهد. -در اینجا اصلاح، فرآیندی غیرخودکار در طی واکنش به حادثه پس از نفوذ است.
محدود است - برای یک محدوده تهدید ناشناخته هیچ علتی ریشه ای یا نتایجی از مسیر حرکت ارائه نمی دهد. -در اینجا اصلاح، فرآیندی غیرخودکار در طی واکنش به حادثه پس از نفوذ است.
محدود است - برای یک محدوده تهدید ناشناخته هیچ علتی ریشه ای یا نتایجی از مسیر حرکت ارائه نمی دهد. -در اینجا اصلاح، فرآیندی غیرخودکار در طی واکنش به حادثه پس از نفوذ است.
مشکل و ارور Server’s certificate cannot be checked در پنل مدیریتی VMware Horizon View
یکی از رایج ترین ارور هایی که در پنل مدیریتی VMware Horizon View میبینیم ، ارور Server’s certificate cannot be checked است و در این پنل آیکون Security Server \ Connection Server به رنگ قرمز نشان داده میشود. با کلیک بر روی Connection Server پیغام Connection Server certificate is not trusted نمایش داده میشود. با کلیک بر روی Security Server پیغام Server’s certificate cannot be checked نمایش داده میشود.
Document Id : 2000063
این مشکل زمانی رخ میدهد که (Certificate Revocation List (CRL شامل آدرسURL از Connection Server جفت شده با Security Server قابل دسترسی نیست.
برای حل این مشکل ، اطمینان حاصل کنید Connection Server که با Security Server جفت شده قادر به بررسی URL که داخل Certificate Revocation List (CRL) باشند ، اگر محیط شما شامل پروکسی سروری که دسترسی به اینترنت را کنترل میکند است.
برای برطرف کردن مشکل ، فایل CertificateRevocationCheckType را در رجیستری ویندوز ایجاد کنید
نکته: این مراحل شامل ایجاد تغیر در رجیستری ویندوز است . قبل از ایجاد تغیر اطمینان حاصل کنید که بک آپ از رجیستری و ماشین خود داشته باشید .
برای ایجاد CertificateRevocationCheckType مراحل زیر را دنبال کنید:
نکته: اگر شما از چندین Connection Server استفاده میکنید باید تغیرات را در همه آنها ایجاد کنید.
به مسیر HKEY_LOCAL_MACHINE\Software\VMware, Inc.\VMware VDM\Security\ بروید.
اخطار: مطمئن شوید که تغیرات را در Connection Server اعمال میکنید ، نه در Security Server.
دستور رجیستری CertificateRevocationCheckType را با نوع (REG_SZ) و مقدار 1 ایجاد کنید.
نیازی به ریبوت برای اعمل این تغییرات نیست .
برای مشاهده مشکلات ، پیغام های ارور دیگر و دیدن راه حل آنها ، از این مقاله استفاده کنید.
VMware View پیشرفت ها و ویژگی های بسیاری دارد. در این مقاله ما به بررسی پیشرفت های ارتباطات HTTP بین اجزای View خواهیم پرداخت . در View 5.0 ، VMware از مخرن گواهینامه های فایل بیس JKS و PKCS12 در اجزای View پشتیبانی میکرد ، اما از View 5.1 به بعد ، VMware از مخرن گواهینامه های ویندوزی پشتیبانی میکند . این تغیرات اجازه ادغام بهتری با ساز و کار مدیریت گواهینامه ها میدهد. زمانی که شما به View 5.1 آپگرید میکنید ، مخرن گواهینامه های JKS و PKCS12 به صورت خودکار به مخرن گواهینامه ویندوز انتقال داده میشوند .
استفاده از SSL در حال حاضر برای ارتباطات HTTP بین اجزای View است . هرچند که یک مکانیزم Trust-on-first-use دخیل است ، بهترین راه درج گواهینامه های معتبر تایید شده توسط Certificate Authority (CA) مورد اعتماد در تمام اجزای View است . در View ، پنل مدیریتی View به شما وضعیت سلامت گواهینامه ها مربوط به اجزاء مناسب را نشان میدهد .
شکل 1 ارتباطات امن SSL بین اجزای مختلف View را نشان میدهد. در مورد vCenter Server و View Composer ، ادمین ها این انتخاب را دارند تا گواهینامه های self-signed یا invalid را بعد از تاید هویت گواهینامه ، از محیط کاربری ادمین اضافه کنند .
مکانیزم احرازهویت SSL
احراز هویت SSL اساسا در مبنای پروتکل لایه امنیتی ترنسپورت TLS است . هدف اصلی TLS ارائه امنیت و تعاملات بین ارتباط دو نرم افزار است . پروتکل TLS Handshake ، سرور را با کلاینت ، و کلاینت را با سرور در صورت انتخاب ، احراز هویت میکند . همچنین TLS قبل از اینکه پروتکل اپلیکیشن (سرور و کلاینت) اولین بایت دیتا را ارسال یا دریافت کند درمورد الگوریتم رمزنگاری و کلید های رمزنگاری مذاکره میکند . پروتکل Handshake یک کانال امن با موارد زیر میسازد:
Authenticating peers (client or server) using asymmetric (public-private) keys
Agreeing upon cryptographic protocols to be used, such as 3DES, RSA
Negotiating a shared secret
وقتی پروتکل handshake بین peers ها تکمیل شود ، peers شروع به برقراری ازتباط با مد کانال امن از طریق الگوریتم های رمزنگاری و کلید رمزنگاری مذاکره شده ، که حملات مردی در میان و استراق سمع را مسدود میکند.
این بخش جریان اعتبارسنجی گواهینامه X.509 ، فرم استاندارد گواهینامه های public key را توضیح میدهد. این تنظیمات در Connection Server و Security Server و View Composer و vCenter Server اعمال میشود. وضعیت سلامت هرکدام از این اجزا در پنل مدیریتی View مطابق شکل زیر نشان داده میشود .
یک گواهینامه پیش فرض برای هرکدام از اینها ساخته میشود ، اما best practice میگوید که این گواهینامه ها را با یک گواهینامه صادر شده از یک CA سرور trusted جایگزین کنید .
هر Connection Server گواهینامه های دیگر اجزای متصل شده به آن را اعتبارسنجی میکند . در فلوچارت شکل زیر مراحل بررسی آنها نمایش داده شده :
Hostname match
Connection Server بررسی میکند که نام سرور بخشی از URL کانکشن باشد (در مواردی که Security Server ، برای URL های خارجی کانفیگ شده باشد) با یکی از اسم های subject در گواهینامه معرفی شده ، همخوان باشد. اگر این مقدار همخوان نباشد ، وضعیت کامپوننت موردنظر در پنل مدیریت View پیغام Server’s Certificate does not match the URL را نشان میدهد.
Certificate issuer’s verification
Connection Server اعتبار صادرکننده گواهینامه و trusted بودن آن را بررسی میکند.
Certificate Expired/Not Yet Valid
اعتبار گواهینامه در زنجیره گواهینامه ها بررسی میشود تا مدت اعتبار و زمان گواهینامه صادر شده مشخص شود – اگر اعتبار نداشته باشند وضعیت کامپوننت موردنظر در پنل مدیریت View پیغام Server’s either Certificate Expired or Certificate Not Yet Valid را نشان میدهد.
Certificate revocation checking
VMware View از Revocation Checking پشتیبانی می کند ، تکنیکی که اطمینان حاصل میکند از اینکه صادرکننده گواهینامه بنا به دلیلی گواهینامه را باطل نکرده باشد. View از دو روش بررسی اعتبار گواهینامه ها ، CRLs (Certificate Revocation Lists) و OCSPs (Online Certificate Status Protocols) پشتیبانی میکند. اگر گواهینامه بدون اعتبار یا در دسترس نباشد وضعیت کامپوننت موردنظر در پنل مدیریت View پیغام Server’s either Revocation status cannot be checked را نشان میدهد.
نکته : عملیات revocation برای تمام اجزاء بررسی میشود به استثنای روت. یعنی گواهینامه روت بررسی نمیشود ؛ زیرا مدیریت فعال مخزن گواهینامه روت ، فقط باید مطئن شود که موجود است . گواهینامه های unrevoked شده مورد تایید است. اگر شما مطمئن نیستید که مخزن گواهینامه کاملا بروز است ، توصیه میشود تا اسکوپ revocation checking را تا خود روت افزایش دهید . اگر هرکدام از گواهینامه ها revocation check را fail شوند ، در پنل مدیریت View پیغام Server Certificate has been revoked نشان داده خواهد شد.
تنظیمات گواهینامه ها X.509در هر جزء متفاوت و یکپارچگی آن با VMware View
گواهینامه X.509 ، صادر شده از Trusted Certification Authority ، تنظیمات در اجزای Secure Gateway
در طول نصب VMware View Connection Server و Security Server، یک گواهینامه پیش فرض ساخته و تنظیم میشود . توصیه میشود که این گواهینامه را با یک گواهینامه صادر شده از یک CA سرور trusted جایگزین کنید .
نکته: زمانی که اجزای Secure Gateway بروز شوند ، و ورژن قبل توسط یک CA سرور trusted تنظیم شده باشد ، آن گواهینامه ها در زمان نصب به صورت خودکار به مخرن گواهینامه ویندوز انتقال داده میشوند .
گواهینامه X.509 ، صادر شده از Trusted Certification Authority ، تنظیمات در اجزای View Composer
در طول نصب VMware View Composer ، یک گواهینامه پیش فرض ساخته و تنظیم میشود . توصیه میشود که گواهینامه پیش فرض را با یک گواهینامه صادر شده از یک CA سرور trusted جایگزین کنید .
گواهینامه X.509 ، صادر شده از Trusted Certification Authority ، تنظیمات در اجزای vCenter Server
در طول نصب VMware vCenter Server، یک گواهینامه پیش فرض ساخته و تنظیم میشود . توصیه میشود که گواهینامه پیش فرض را با یک گواهینامه صادر شده از یک CA سرور trusted جایگزین کنید .
Revocation Checking
VMware View 5.1 از revocation checking گواهینامه های SSL ، که میتوان از طریق رجیستری یا توسط تنظیمات GPO policy تنظیم شوند ، پشتیبانی میکند. برای تنظیم انواع revocation check ، گزینه های رجیستری زیر را ویرایش یا روی Connection Servers ، GPO policy اعمال کنید :
کلید رجیستری CertificateRevocationCheckType را در مسیر زیر اضافه کنید :
None – Set CertificateRevocationCheckType = 1. No revocation checking is done if this option is set.
EndCertificateOnly – Set CertificateRevocationCheckType = 2.Revocation checking is done only for the end certificate in the chain.
WholeChain – Set CertificateRevocationCheckType = 3. A complete path is built for the certificate, and a revocation check is done for all certificates in the path
WholeChainButRoot – Set CertificateRevocationCheckType = 4. A complete path is built for the certificate, and a revocation check is done for all certificates in the path except for the Root CA certificate (default value).
Cumulative timeout across all revocation check intervals in milliseconds. If not set, default is set to ‘0’, which means Microsoft defaults are used.
انواع گواهینامه ها و استفاده آنها در VMware View
View از انواع مختلف گواهینامه ها برای تحقق انواع سناریو ها در سایت مشتری پشتیبانی میکند. گواهینامه در دو دسته گواهینامه های single-server name و گواهینامه های multiple-server name گنجانده میشوند .
یک گواهینامه single-server name شامل یک آدرس URL است که تشخیص میدهد سرور برای کدام گواهینامه صادر شده . این نوع گواهینامه زمانی صادر میشود که connection broker فقط از طریق شبکه داخلی یا فقط از طریق شبکه خارجی در دسترس است. به این معنی که ، سرور یک نام FQDN دارد.
گواهینامه های Multiple-server name در محیط هایی که View Connection Server قابلیت دسترسی از هر دو مسیر شبکه داخلی و خارجی ، که نیاز دارد تا connection server چند نام FQDN داشته باشد ، کاربرد دارد. به عنوان مثال ، یکی برای شبکه داخلی و یکی برای شبکه خارجی .
گواهینامه های Multiple-server name از بیشتر از یک SAN (Subject Alternative Name) برای هر یک گواهینامه تکی پشتیبانی میکنند . این نوع از گواهینامه نیز زمانی استفاده می شود که اگر SSL offloaders بین View clients و connection server قرار داده شود و یا هنگامی که یک اتصال تونل شده با Security server فعال شود.
یک گواهینامه wildcard ، گواهینامه ای است که برای تمام سرور های داخل دامین صادر میشود . FQDN داخل گواهینامه wildcard معمولا به این فرمت نوشته میشود *.organization.com. یک گواهینامه wildcard امنیت کمتری از گواهینامه SAN دارد ، اگر یک سرور یا ساب دامین در معرض خطر باشد ، کل محیط در معرض خطر است .
سیستم HC 250 مناسب برای راه اندازی مجازی سازی در محیط های کوچک و متوسط می باشد و پلی می باشد برای راه اندازی SDS درون سازمان ها، روی این سیستم VMware Vsphere 5.6 و یا 6 بصورت Built in وجود دارد. روی این سیستم سرورهای Apollo قرار دارد که مدل XL 170 می باشند و روی آنها از پردازنده های عملکرد استوریج HP MSA 2052, استوریج HP MSA 2052, استوریج MSA 2050, MSA 2052 , قیمت استوریج , انواع استوریج , نصب استوریجE5-2600 قراردارد. در واقع اگر بخواهیم از 4 سرور DL380 استفاده کنیم نیاز به 8 یونیت فضا درون رک خواهیم داشت حال آنکه در صورت استفاده از این سیستم فقط نیاز به 2 یونیت خواهیم داشت و در واقع باعث کاهش فضا و در نتیجه کاهش هزینه خواهد شد. با توجه به اینکه روی این سیستم StoreVirtual VSA قرار دارد می توان SDS را پیاده سازی نمود و از قابلیت Network RAID استفاده کرد. بدین معنی که RAID بین چندین دستگاه مختلف پیاده خواهد شد. همچنین این سیستم قابلیت Multi System HA را نیز پوشش می دهد و می توان یکدستگاه را در سایت دیگری قرارداد تا چنانچه یک سیستم دچار مشکل شود سیستم دیگر در سایت دیگر ادامه کار را انجام خواهد داد. همچنین این سیستم قابلیت Adaptive Optimization و Remote Copy را نیز پوشش می دهد که در پست های بعدی این قابلیت ها توضیح داده خواهد شد. روی هر سرور که در این سیستم قرار می گیرد می توان 512 گیگا بایت RAM قرار داد و کارتهای شبکه نیز می تواند 10 گیگا بیت بر ثانیه باشد. در صورتیکه نیاز به GPU داشته باشیم می توانیم روی این سیستم از XL190 استفاده کنیم.
اکثر دیتابیس ها مانند اوراکل و SQL شامل تعداد زیادی فایل های کوچک می باشند که معمولا در یک Container فایل بزرگ قرار گرفته اند. معمولا این فایل های شکسته شده و کوچک حاوی اطلاعات کاربران هستند و بین بازه های Backup گیری بصورت مداوم در حال تغییر هستند. در حالت استاندارد که Incremental Backup تهیه می شود، تمامی Container توسط نرم افزار backup گیری کپی می گردد در حالیکه ممکن است درون آن تغییرات بسیار کم باشد در نتیجه I/O زیادی تولید شده و فضای زیادی روی Tape اشغال خواهد شد. بوسیله BLIB (Block Level Incremental Backup) فقط بلاک هایی Backup گرفته می شوند که تغییر نموده است. در واقع در این روش نرم افزار مربوطه با فایل سیستم ارتباط برقرار نمی کند بلکه مستقیما وارد بلاک های دیسک شده از آنهایی نسخه پشتیبان تهیه می کند که تغییر کرده اند.
برای اینکه این اتفاق رخ دهد نیاز می باشد نرم افزار Backup گیری مانند Veritas این قابلیت را پشتیبانی کند.
لازم بذکر است در صورت نیاز به Restore کردن اطلاعات مانند حالت استاندارد نیاز به آخرین Full Backup و تمامی Incremental ها می باشد.
معمولا این قابلیت در Agent نرم افزارهای Backup گیری که امروزه به بازار عرضه شده است وجود دارد.
مزیت های BLIB:
- باعث کاهش Backup windows می شود.
- باعث می شود بتونیم تعداد بیشتر Backup job را اجرا کنیم.
- تمامی Backup set ها دارای دیتاهای بروز می باشند.
فایروال سری Firepower 2100 از جمله محصولات امنیتی کمپانی سیسکو می باشد که شامل مجموعه ای چهار تایی از پلتفرم های امنیتی Threat-focused NGFW هستند. زمانی که توابع پیشرفته Threat فعال می شود این فایروال کارایی پایدار فوق العاده ای را ارائه می دهد. در نتیجه دیگر امنیت در غیاب کارایی شبکه به دست نمی آید بلکه هر دو همزمان حفظ می شوند. در این پلتفرم ها معماری CPU چند هسته ای جدیدی ضمیمه شده است که همزمان فایروال، رمزنگاری و توابع نفوذ تهدید ها را بهینه می کند. با توجه به محدوده توان عملیاتی فایروال های سری 2100، موارد استفاده ای از Edge اینترنت تا مرکز داده را در بر می گیرد.
ویژگی های فایروال های سری 2100:
Threat-focused NGFW
این سری از محصولات، با دفاعی قوی تر در برابر تهدیدها انعطاف پذیری را بهبود می بخشند، کارایی را حفظ می کنند، کنترل اپلیکیشن Granular را به کار می بندد، در برابر بدافزارها از شبکه محافظت می کنند، زمان لازم برای تشخیص و اصلاح را کاهش می دهند و با استفاده از رابط مدیریتی On-device پیچیدگی را کاهش می دهند.
کارایی و تراکم پورت بهینه شده
توان عملیاتی این فایروال ها از 2Gbps تا 8.5Gbps می باشد. 16 پورت 1GE را در مدل های Low-end پشتیبانی می کند همچنین در مدل های High-end حداکثر 24 پورت 1GE یا 12 پورت 10GE فراهم می کند. تمام محصولات در این رده در فرم فاکتور 1 RU ارائه می شوند.
معماری نوین
زمانی که از طریق مسیریابی بارهای کاری مختلف به تراشه های گوناگون میرسند، بررسی تهدید فعال می شود. فایروال سری 2100 به واسطه Dual-CPU منحصر به فردی که ارائه می دهد، معماری چند هسته ای و کارایی را حفظ می کند. فعال کردن ویژگی های حفاظت از تهدید تاثیری بر روی توان عملیاتی فایروال ندارد.
مدیریت برای پاسخگویی به نیازهای شما
Cisco Firepower NGFW، برای کانفیگ کردن زمان کمتری را جهت پیکربندی صرف می کند و از لحاظ مدیریت نیز هزینه کمتری دارد.
ما در شرکت بهبود سامانه های اطلاعاتی فاراد پس از بررسی و آزمودن این استوریج و با استفاده از منابع دیگر به تحیلی کامل از این ذخیره ساز رسیدیم که به شرح ذیل می باشد.
تابستان امسال hpe از نسل 5 استوریج MSA 2050 و 2052 رو نمایی کرد. سیستم های ذخیره ساز جدید MSA با توجه به قیمتی که خریدار پرداخت می کند، و ویژگی های بسیاری که این مدل از استوریج دارا می باشد. توانسته سهم بزرگی را از استوریج های entry level را به خود اختصاص دهد (با بیش از 500000 فروش). استوریج های MSA مدت زمان طولانی است در بین استوریج های entry level به قابل اعتماد بودن و استفاده آسان شناخته شده است. استوریج خانواده MSA 2050 با توجه به ویژگی هایی که دارا می باشد ، می تواند بیش از 200k IOPS را پشتیبانی نماید که MSA 2050 قطعا میتواند با استوریج های خارج از کلاس خود رقابت نماید.
Hpe ویژگی های جدیدی را نسبت به نسخه های قدیمی MSA در همان شاسی ارائه نموده است. در استوریج MSA 2050 می توان درایو های HDD به همراهSSD Pools یا SSD caching استفاده نمود. در حالی که MSA 2052 همراه با لایسنسی که شامل دو درایو SSD برای استفاده از performance tiering می باشد ارائه میشود . در سناریو cache ، مشتریان به طور معمول از دو درایو SSD و معمولا از چهار SSDs برای teiring استفاده می نمایند . فاراد در این برسی تمرکز خود را در MSA 2052 با چهار SSDs برای Tiering قرار میدهیم.
MSA 2052 تمام اتصالات مورد نیاز برای یک کسب کار دارا می باشد می تواند با ارائه Fibre Channel (8/16) یا iSCSI 10GbE ports برای هر کنترلر پشتیبانی نماید. با توجه به طراحی و نیاز شما میتوان همه پورتها FC و یا iSCSI باشد. HPE به مشتریان خود پیشنهاد می دهد که به صورت متناوب از ترکیبی FC و iSCSI استفاده نمایند. از دو پورت FC برای local FC و دو پورت iSCSi برای remote replication استفاده می شود. درقسمت میانی دستگاه کنترل ها به صورتActive/Active قرار گرفته است. شاسی ما دارای 24-bay 2.5″ SAS backplan ، که نسبتا معمول است .
اگر فضای مورد نیاز شما زیاد است می توانید از گزنیه های LFF استفاده نمایید. خانواده MSA با JBODs (enclosure) که میتواند LFF یا SFF باشد .در ضمن می توان هارد دیسک های LFF را در Auto teiring استفاده نمود به این صورت که داده هایی که استفاده بیشتری دارند (hot data) در درایو های SSD و داده های که از آنها استفاده کمتری میشود (cold data) برای صرف جویی در هزینه از هارد دیسک های LFF استفاده نمود.
در MSA 2052 ، 1.6 TB فضای ذخیر سازی SSD و تمام لایسنس های نرم افزاری در آن قرار داده شده و برای استفاده اماده است. اگر برای MSA 2050 نیاز به درایو های SSD ، برای cache و auto tiering باشد، نیاز به تهیه لایسنس های مرتبط می باشید . این کار بسیار ساده می باشد درایو های SSD را به دستگاه اضافه نموده و لایسنس Caching و Auto tierin را به آن اضافه می کنیم. تمای این فرایند ها به صورت خودکار می باشد.MSA تمامی این کارها ( تغییر workload ) به صورت اتوماتیک انجام می دهد و کاربر نیاز به هیچ گونه طراحی برای استفاده از این ویژگی ندارد. همچنین MSA دارای virtualized snapshots برای ریکاوری سریع و محافظت از داده ها می باشد. MSA همچنین از remote replication برای disaster recovery در site های متفاوت پشتیبانی میکند.
MSA 2052 ای که در حال برسی آن هستیم با 800GB SSD و 1.2TB 10K HDD پیکربندی شده است. درایو ها در دو pools پیکربندی شده اند که هر pool متعلق به یک کنترلر میباشد. Pool ها شامل 10 HDDs و 2 درایو SSDs برای Tier performance میباشند.
HPE MSA 2052 Specifications
Drive description: Up to 192 SFF SSD/SAS/MDL SAS or 96 LFF SSD/SAS/MDL SAS maximum including base array and expansion, depending on model
Max. drive type:
10 TB 12G 7.2K LFF dual-port MDL SAS HDD
1.8 TB 12G 10K SFF dual-port SAS HDD
2 TB 12G 7.2K SFF dual-port MDL SAS HDD
3.2 TB SFF SSD
Max. raw capacity:
Supported 614 TB SFF/960 TB LFF maximum raw capacity
Including expansion, depending on model
Storage expansion options:
HPE MSA 2050 LFF Disk Enclosure
HPE MSA 2050 SFF Disk Enclosure
Host interface options:
8 Gb/16 Gb FC 8 ports per system or
1GbE/10GbE iSCSI 8 ports per system
Storage controllers: 2 controllers, active/active
SAN backup support
RAID levels: 1, 5, 6, 10
HPE Systems Insight Manager (SIM) support
Compatible operating systems
Microsoft Windows Server 2016
Microsoft Windows Server 2012
VMware
HP-UX
Red Hat Enterprise Linux
SUSE Linux
Clustering support: Windows, Linux, HP-UX
Form factor: 2U base array, 2U LFF or SFF disk enclosures
طراحی و ساخت:
استوریج ، MSA 2052 که برای بررسی انتخاب شده 2U از فضای رک شما را اشغال می کندو می توان از 24 عدد درایو 2.5 اینچی بر روی آن استفاده نمود.
در فضای پشت دستگاه دو کنترلر در وسط قرار گرفته اند و در طرفین دو کنترلر منبع های تغذیه قرار گرفته است. بر روی کنترلر ها از سمت چپ 4 پورت با سرعت بالا برای ارتباط با هاست ، وجود دارد که می تواند فیبر یا 10GbE یا ترکیبی از هردو ( 2 FC و iSCSI 2) باشد. و در زیر این پورت های miniUSB CLI قرار گرفته .در سمت راست پورت miniUSB پورت های اترنت برای مدیریت استوریج و یک پورت SAS expansion برای اضافه کردن enclosure وجود دارد.مدیریت :
رابط گرافیکی MSA هنوز هم برای کسانی که در گذشته مدیریت استوریج را انجام داده اند آشنا می باشد. حتی برای کسانی که در زمینه استوریج تازه کار هستند متوجه می شوند که محیط HTML5 آن بسیار ساده و به دور از پیچیدگی می باشد. در صفحه اصلی مدیریت کاربران تمام اطلاعات لحظه ای سیستم را به صورت خلاصه مشاهده می نمایند که شامل هاست های متصل ، سرعت لحظه ای انتقال ، پورت متصل ،فضای ذخیره سازی ، و همچنین بهره وری سیستم است . این رابط گرافیکی با طیف گستره ای از مرور گر ها سازگار است و نیاز به نصب هیچ برنامه ای اضافی نیست. کاربران حرفه ای همچنین می توانند در محیط CLI با طیف گسترده ای از دستورات استورج را مدیریت نمایند.
با نگاهی به رابطه کاربری ،در سربرگ هاست اجازه دسترسی به تمام هاست های قابل مشاده را دارید . از اینجا میتوانید LUN ها را به هاست های مورد نظر باپورت های scsi یا fc Map, نمود یا به سادگی ان را تغییر داده یا به اشتراک بگذارید.
با استفاده از سربرگ POOLS کاربر میتواند storage pools ها را مشاهده ، تغییر یا مدیریت نماید ، که در مثال ما دو storage pool (تقسیم شده بین هر کنترلر) و هر POOL شامل یک گروه از درایو های SSD با RAID1 و همچنین گروهی از هارد ها با RAID6 میباشد.
در پایین صفحه مدیریت میتوانید سلامت درایو هایی که در disk group ها قرار گرفته اند مشاهده نمود . و همچنین میتوان فضای مورد استفاده را به تفکیک tire level ها مشاهده و محل قرار گیری فعلی دیتا را مشخص نمود.
در سربرگ Volumes (همانطور که از نامش بر می آید) جایی که شما قادر به ایجاد و ذخیره سازی اطلاعات هستید. شما قادر به ایجاد Volume(LUN) های مختلف و اختصاص دادن ان به pool مورد نظر در همان لحظه می باشید.
تقریبا تمام امکانات در نسخه مرور گرهای موبایل نیز ارائه شده که در این مورد مرورگر گوشی ایفون مورد بررسی قرار گرفته است. با توجه به اینکه رابط کاربری کوچک شده ولی همچنان تمامی گزینه ها به خوبی قابل مشاهده می باشد . توجه داشته باشید که به طور معمول MSA از مرور گرهای موبایل پشتیبانی نمی کند اما بیشتر قابلیت آن در اینجا به خوبی قابل استفده می باشد.
عملکرد استوریج MSA 2052 با برنامه Microsoft SQL Server OLTP به همراه بار کاریه TPC-C شبیه سازی شده است. در هر سناریو LUN بر روی مجموعه از دیسک ها که روی آن دو درایو SSD با RAID 1 ، است قرار دارد. دو LUNs بر روی دو کنترلر بالانس می شوند.در هر POOL به صورت اختصاصی SSD پیکر بندی شده است تا سرعت پردازش داده در این تست را بهبود ببخشد. تمامی تست ها بر روی دو پورت 16 Gb FC انجام می شود. در این آزمایش ما دو تنظیم متفاوت برای درایو های SSD قرار دادیم. اولین تنظیم شامل 3.2 TB (1.6TB قابل استفاده) فضای خام چهار SSD 800GB است.
دومین تنظیم شامل 6.4 TB ( 3.6 TB قابل استفاده) فضای خام چهار SSD 1600GB است. با توجه به قیمت درایور های SSD اکثر کاربران استوریج MSA از درایو های با فضای کمتر استفاده می کنند . ما از هر دو SSD برای نشان دادن توانای کنترلر ها استفاده می کنیم. اوج بار کاری بر روی 6 VMs قرار دارد و CPUs کنترلرها در حال استفاده از حدود 80 درصد از توان خود هستند.
HPE MSA 2052 از هر دو SSD cache و tiering SSD ساپورت می نماید . در این بررسی تمرکز ما به طور کامل بر عملکرد tiering است. cache SSD فقط خواندنی است، بنابراین فقط فعالیت خواندن سریعتر می شود. tiering از تسریع خواندن و نوشتن پشتیبانی می کند. همانطور که ممکن است انتظار داشته باشید، حافظه cache در هر pool را فقط با یک SSD میتوان فعال کنید، در حالیکه R / W tiering نیاز به حداقل دو SSD در RAID1 (یا 3-4 SSD برای RAID5 / 6). SSD های اضافی هزینه قابل توجه ای را به قیمت کلی SAN اضافه می کنند.
SQL Server Performance
هر ماشین SQL server بر روی دو vDisk تنظیم شده است. 100 GB فضا برای boot و سیستم عامل و 500 GB فضا برای دیتا بیس و log در تظر گرفته شده است.برای هر ماشین 16 vCPU و 64 GB رم و LSI Logic SAS SCSI controller اختصاص داده شده است .
این آزمایش بر روی SQL Server 2014 که بر روی سیستم عامل windows server 2012 R2 نصب شده است و بر اساسQuest’s Benchmark Factory for Databases که برای تست دیتا بیس های بزرگ طراحی شده است انجام شده است.
SQL Server Testing Configuration (per VM) Windows Server 2012 R2 Storage Footprint: 600GB allocated, 500GB used SQL Server 2014 Database Size: 1,500 scale Virtual Client Load: 15,000 RAM Buffer: 48GB Test Length: 3 hours 2.5 hours preconditioning 30 minutes sample period SQL Server OLTP Benchmark Factory LoadGen Equipment Dell PowerEdge R730 Virtualized SQL 4-node Cluster Eight Intel E5-2690 v3 CPUs for 249GHz in cluster (two per node, 2.6GHz, 12-cores, 30MB Cache) 1TB RAM (256GB per node, 16GB x 16 DDR4, 128GB per CPU) 4 x Emulex 16GB dual-port FC HBA 4 x Emulex 10GbE dual-port NIC VMware ESXi vSphere 6.5 / Enterprise Plus 8-CPU
عملکرد SQL server با دو تنظیم متفاوت را مورد سنجش قرار دادیم. یک تنظیم با چهار عدد SSD 800 GB در حالی که تنظیم دیگر با چهار عدد SSD 1.6 TB استفاده می نمایند. با توجه به حجم SSD ها متوجه می شویم به تنظیم اول می توان 2 ماشین و تنظیم دیگر 4 ماشین را اختصاص بدهیم. SSD های به کار گرفته شده از یک سری می باشند و عملکرد یکسانی را دارا هستند.در دو ماشین در حدود 6308 TPS را اندازه گیزی کردیم در چهار ماشین دیگر در حدود 12,554 TPS اندازگیری شد تقریبا 2 برابر 2 ماشین اول.
با توجه به زمان تاخیر متوجه عملکرد درخشان استوریج MSA 2052 می شویم. دو ماشینی که بر روی درایو های 800 GB قرار دارند در حدود 9.8 ms تاخیر دارند با افزایش بار کاری در درایو های 1.6 TB تاخیر در حدود 35.25 ms است که بسیار خوب است.
هنگامی که به آرایه های ذخیره سازی مورد ارزیابی قرار داده می شود، تست با برنامه واقعی بهترین راه ارزیابی استوریج می باشد تا به صورت مصنوعی زیرا نمایشی از بار واقعی نمی باشد.ما این تست ها را درطیف مختلفی از پروفایل های تست مختلف انجام دادیم.از جمله دیتابیس و VDI و به برنامه تست IO و برای تست از سرور های Dell PowerEdge R730 استفاده می کنیم
Profiles:
4K Random Read: 100% Read, 128 threads, 0-120% iorate
4K Random Write: 100% Write, 64 threads, 0-120% iorate
HPE MSA 2052 به خوبی در اولین تست مصنوعی ما با بلاک سایز 4 K به صورت خواندنی ظاهر شد. 187 K IOPS را زیر 1 ms پشت سر گذاشت ، این تست بیش از200K IOPS را طی می کند. حداکثر 233K IOPS را طی می کند با میانگین تاخیر 16.2ms
عملکرد استوریج MSA 2052 با داده های 4K تصادفی نوشتن بسیار خوب بود. 90K IOPS را زیر 1ms پاسخ داد .که درنهایت 110K IOPS را با تاخیر 14ms طی کرد.
HPE MSA 2052 به خوبی با انتقال داده های بزرگ رفتار می کند . همانطور در تست داده های خواندی ترتیبی با بلاک سایز 64K مشاهده می کنید MSA 2052 می تواند با عملکرد ، 5000 IOPS را زیر 1ms ارائه دهد و در نهایت 24K IOPS را در حدود 20.8ms پاسخگو باشد. در مدت زمان خواندن حداکثر پهنای باند آن 1.53GB به دست آورد.
\MSA 2052 با داده ترتیبی بزرگ هیچ گونه مشکلی را ندارد. با تاخیر،میانگین زمانی کمتر 0.25ms توانست 7800 IOPS را پاسخگو باشد، توانست 9200 IOPS با پهنای باند 572 MB/s دارا باشد.
SQL server توانست 170K IOPS را زیر 1ms انجام دهد و به حداکثر 195K IOPS را با تاخیر 4.89ms برسد.
SQL server با بار کاریه 90% خواندن و 10% نوشتن توانست با تاخیر زیر یک میلی ثانیه 160k IOPS را پاسخگو باشد. و حداکثر 184k IOPS را به میانگین 5.3ms برسد.
بانگاهی به SQL server با بار کاریه 80% خواندن و 20% نوشتن توانست با تاخیر زیر یک میلی ثانیه 145k IOPS را پاسخگو باشد. و حداکثر 166k IOPS را به میانگین 6.1ms برسد.
Oracle توانست 170K IOPS را زیر 1ms انجام دهد و به حداکثر 195K IOPS را با تاخیر 4.89ms برسد.
با افزایش خواندن بارکاری به 90% خواندن و 10% نوشتن توانست با تاخیر زیر یک میلی ثانیه 160k IOPS را پاسخگو باشد. و حداکثر 184k IOPS را به میانگین 3.3ms برسد.
با کاهش خواندن به 80% خواندن و 20% نوشتن MSA 2052 توانست با تاخیر زیر یک میلی ثانیه 145k IOPS را پاسخگو باشد و حداکثر 166k IOPS را به میانگین 6.1ms برسد ، عملکرد خوبی داشته باشد.
با نگاه به مشخصات بوت VDI Full-Clone متوجه می شویم 65K IOPS را با تاخیر زیر 1ms انجام می دهد. حداکثر 116K IOPS با تاخیر زمانی 8.9ms انجام میدهد.
در هنگام login ابتدایی 31K IOPS را در حدود 1ms پاسخگو می باشد قبل از رسیدن 16ms تاخیر 32k IOPS میرسد.
جمع بندی:
MSA سال ها است برای کسب کارهای کوچک ومتوسط عرضه شده است. در حالی که در بازار با توجه به عملکرد و کارایی درایو های SSD علاقه مندی بیشتری از گذشته وجود دارد و در بیشتر کسب کارها عملکرد و قیمت دو فاکتور اساسی می باشد. با توجه به عملکرد های بالا و گذشته استوریج MSA که به قابل اعتماد بودن و سادگی در کار مشهور است و مناسب بودن این ذخیره ساز برای اکثر کسب کارهای کشورمان به این نتیجه می رسیم که استوریج MSA 2052 هم عملکرد مناسبی را دارا است و مقرون به صرفه است و می تواند نیاز خیلی از سازمان ها و شرکت ها را را براورده سازد و از over designهای مرسوم جلوگیری نماید.
هر چند نباید از عملکرد چشم پوشی کنیم . در تست های بالا به 200K IOPS با بلاک سایز های 4K رسیدیم که نامطلوب نیست. حتی در تست به صورت مصنوعی به IOPS بیشتر از 200K با تاخیر زمانی زیر 1ms رسیدیم البته باید توجه داشت تست به صورت مصنوعی همه ویژگی های استوریج را نمی توان آشکار ساخت.
به طور کلی قیمت استوریج MSA 2052 با دو درایو SSD وتمام لاینس ها در حدود 10 هزار دلار می باشد. و با ترکیب درایو SSD و هارد دیسک های ارزان قیمت می تواند عمل کرد بسیار مناسبی داشته باشد با توجه به عملکرد و قیمت نمی توان هیچ استوریجی را با MSA 2052 مقایسه نمود ، ولی هنوز هم در بسیاری از کسب کارها عملکرد مهمتر از قیمت می باشد و نیاز به استوریجی با توانای ساپورت IO بیشتری می باشد پس نباید نگران باشید ،زیرا MSA 2052 یک راهکار بسیار مقرون به صرفه و کارا را ارائه می دهد.
در این حالت سرورهای فیزیکی و مجازی در حالت بلاک مستقیم به فضاهای دیسک دسترسی خواهند داشت و برای ایجاد این ارتباط معمولا از شبکه SAN استفاده خواهد شد. البته برای این حالت دسترسی DAS نیز بصورت Block Level عمل می نماید. در شبکه SAN که برای ذخیره سازی Block Level مورد استفاده قرار می گیرد از پروتکل FC معمولا استفاده می شود ولی در سال های اخیر میزان استفاده از پروتکل FCoE نیز افزایش یافته است. در این پروتکل, FC درون پروتکل Ethernet کپسوله شده و باعث می شود بتوانیم از زیر ساخت شبکه Ethernet برای ارسال پروتکل FC استفاده کنیم. همچنین برای کاهش هزینه ها پروتکل دیگری بنام iSCSI نیز وجود دارد که این پروتکل هم از زیر ساخت Ethernet استفاده می کند با این تفاوت که Latency بیشتری نسبت به FCoE دارد. دلیل این Latency این است که iSCSI با پروتکل IP کار می کند و Overhead بیشتری نسبت به FCoE دارد. در شبکه SAN فضاهای ذخیره سازی تحت عنوان LUN ها در اختیار سرورها قرار داده می شود که به این عمل Lun Masking می گوییم. این Lun ها معمولا بصورت RAID تنظیم می شوند. این Lun ها بصورت فضاهای Local برای سرور دیده خواهند شد و سرور ها می توانند روی این فضاها ذخیره سازی اطلاعات را انجام دهند.
این سرور که نسل قبلی آنها DL580 G9 می باشد تا 4 پردازنده را پوشش می دهد و حداکثر می تواند 112 هسته داشته باشد. همچنین از مهمترین مزیت این سرورها این است که نسبت به مدل قبلی 4.8 برابر فضای ذخیره سازی بیشتری را می توان روی آنها قرار داد.
به عبارت ساده تر تعداد دیسک های بیشتری را می توان روی این سرور نصب نمود. روی سرور می توان 48 عدد دیسک مدل SFF نصب نمود و یا اینکه از 20 NVMe کارت استفاده کرد. همچنین تا 6 ترابایت Memory می توان روی این سرور نصب کرد. این ماژول ها DDR 4 با فرکانس 2666 می باشند. این سرور می تواند 16 اسلات PCIe داشته باشد و تا 4 عدد GPU را Support می کند. همچنین با توجه به اینکه این سرور G10 می باشد قابلیت های IST را ( در پست های قبلی توضیح داده شده است ) نیز Support می کند. روی این سرور از iLO5 استفاده می شود.
همچنین با توجه به اینکه روی این سرور پردازنده های Gold و مدل Platinum می توان قرار داد، 28 درصد نسبت به نسل قبلی کارایی بالاتری دارد. از نکات مهم روی این سرور این است که Firmware ها هر 24 ساعت یکبار بصورت خودکار صحت سنجی می شود و در صورت وجود مشکل بصورت اتوماتیک به بهترین حالت خود در قبل Recover خواهد شد. این سرور حدودا 51 کیلوگرم وزن دارد.
فایروال سیسکو سری Firepower 9000 از جمله دیگر محصولات امنیتی کمپانی سیسکو می باشد. این محصول جهت استفاده در مراکز داده و دیگر موارد که نیاز به کارایی بالا، زمان تأخیر کم و توان عملیاتی بالا نیاز دارند، مناسب و ایده آل است. این دستگاه امنیتی یکپارچه و قابل ارتقاء را برای بار کاری و جریان داده بر روی محیط های Cloud، مجازی و فیزیکی ارائه می دهد. فایروال سری Firepower 9000 با سرویس های یکپارچه شده که به همراه دارد، هزینه ها را کاهش می دهد و شبکه های Open Programmable را پشتیبانی می کند.
ویژگی های فایروال سری 9000:
امنیت چند سرویسی قابل ارتقاء
این دستگاه حفره های امنیتی را حذف می کند، سرویس های امنیتی سیسکو را بر روی فابریک شبکه ادغام کرده و ارائه می دهد، سیاست ها ، ترافیک و رویدادها را بر روی سرویس های گوناگون بررسی و مرتبط می کند.
ماژول های امنیتی بسط پذیر
این محصول کارایی امنیت را ارتقاء می دهد، نیازهای پویای کسب و کارها را بررسی می کند و به سرعت قیودی را فعال می کند.
کارایی Carrier-grade
این دستگاه همراه با تنظیمات NEBS است همچنین کارایی شبکه و دفاع در برابر تهدیدها را با تاخیر کم ارائه می دهد، مدیریت جریانی عظیم و Orchestration سرویس های امنیتی را می افزاید. علاوه بر این از EPN ،ESP و معماری های ACI پشتیبانی می کند.